Semantic Faithfulness and Entropy Production Measures to Tame Your LLM Demons and Manage Hallucinations
作者: Igor Halperin
分类: cs.AI, cs.CL, cs.IT, cs.LG, q-fin.CP
发布日期: 2025-12-04 (更新: 2025-12-08)
备注: 23 pages, 6 figures
💡 一句话要点
提出基于信息论和热力学的语义忠实度与熵产生指标,用于评估和控制LLM幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 忠实度评估 信息论 热力学 幻觉控制 无监督学习 语义分析
📋 核心要点
- 现有LLM忠实度评估方法存在不足,缺乏有效的无监督指标来衡量模型输出与输入上下文的一致性。
- 将LLM视为信息引擎,利用信息论和热力学原理,通过建模QCA三元组的主题转换来评估语义忠实度。
- 提出的SF和SEP指标可用于LLM评估和幻觉控制,在公司SEC 10-K文件摘要任务上验证了框架的有效性。
📝 摘要(中文)
本文提出两种新的无监督指标,利用信息论和热力学原理评估大型语言模型(LLM)的忠实度。该方法将LLM视为一个二分信息引擎,其中隐藏层充当麦克斯韦妖,通过提示Q控制上下文C到答案A的转换。问题-上下文-答案(QCA)三元组被建模为共享主题上的概率分布。从C到Q和A的主题转换被建模为转移矩阵${\bf Q}$和${\bf A}$,分别编码查询目标和实际结果。语义忠实度(SF)指标通过这些矩阵之间的Kullback-Leibler(KL)散度来量化任何给定QCA三元组的忠实度。通过凸优化同时推断这两个矩阵的KL散度,并将最小散度映射到单位区间[0,1]以获得最终的SF指标,其中较高的分数表示更高的忠实度。此外,提出了基于热力学的语义熵产生(SEP)指标,并表明高忠实度通常意味着低熵产生。SF和SEP指标可以联合或单独用于LLM评估和幻觉控制。在公司SEC 10-K文件的LLM摘要任务上验证了该框架。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的忠实度评估问题,即如何衡量LLM生成的答案是否忠实于给定的上下文。现有方法通常依赖于人工标注或有监督学习,成本高昂且难以泛化。因此,需要一种无监督的、可解释的指标来评估LLM的忠实度,并控制其产生幻觉。
核心思路:论文的核心思路是将LLM视为一个信息引擎,利用信息论和热力学的概念来建模LLM的运作过程。具体来说,将LLM的隐藏层类比为麦克斯韦妖,它控制着上下文到答案的信息转换。通过分析上下文、问题和答案之间的主题转换,可以量化LLM的忠实度,并评估其信息熵的产生。
技术框架:该框架主要包含以下几个步骤:1) 将问题-上下文-答案(QCA)三元组表示为共享主题上的概率分布;2) 将上下文到问题和答案的主题转换建模为转移矩阵${\bf Q}$和${\bf A}$;3) 通过凸优化方法同时推断这两个转移矩阵,并计算它们之间的Kullback-Leibler(KL)散度;4) 将KL散度映射到单位区间[0,1],得到语义忠实度(SF)指标;5) 计算语义熵产生(SEP)指标,用于评估答案生成过程中的信息损失。
关键创新:该论文的关键创新在于:1) 提出了一种基于信息论和热力学的LLM忠实度评估框架,无需人工标注;2) 将LLM类比为信息引擎,为理解LLM的运作机制提供了一种新的视角;3) 提出了语义忠实度(SF)和语义熵产生(SEP)两个指标,可以联合或单独使用,用于LLM评估和幻觉控制。
关键设计:在技术细节上,论文采用了凸优化方法来同时推断转移矩阵${\bf Q}$和${\bf A}$,这保证了算法的收敛性和效率。KL散度被用作衡量两个转移矩阵之间差异的指标,因为它具有良好的数学性质和可解释性。此外,论文还设计了一种将KL散度映射到单位区间的函数,使得SF指标具有更好的可比性。
🖼️ 关键图片

📊 实验亮点
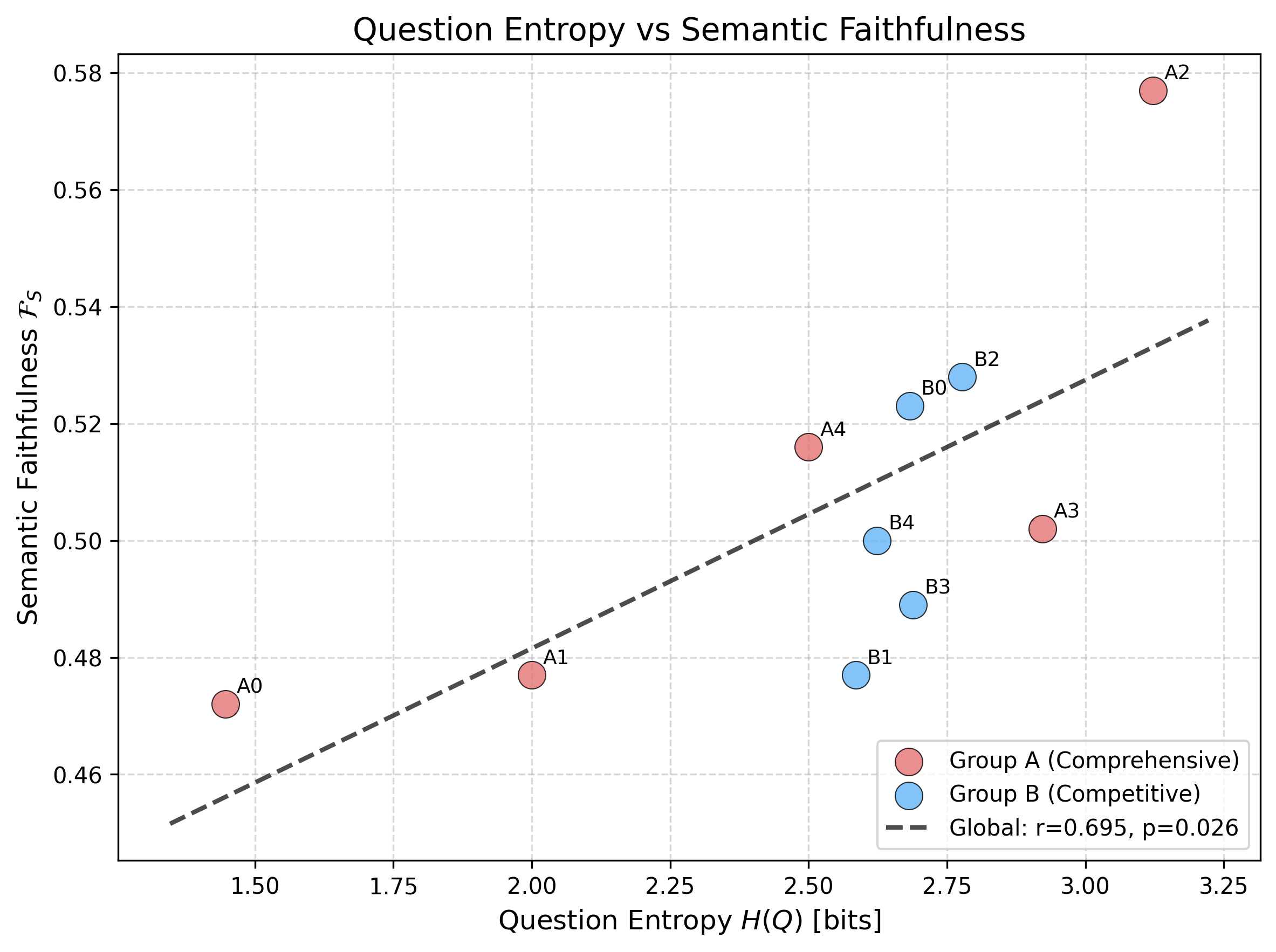
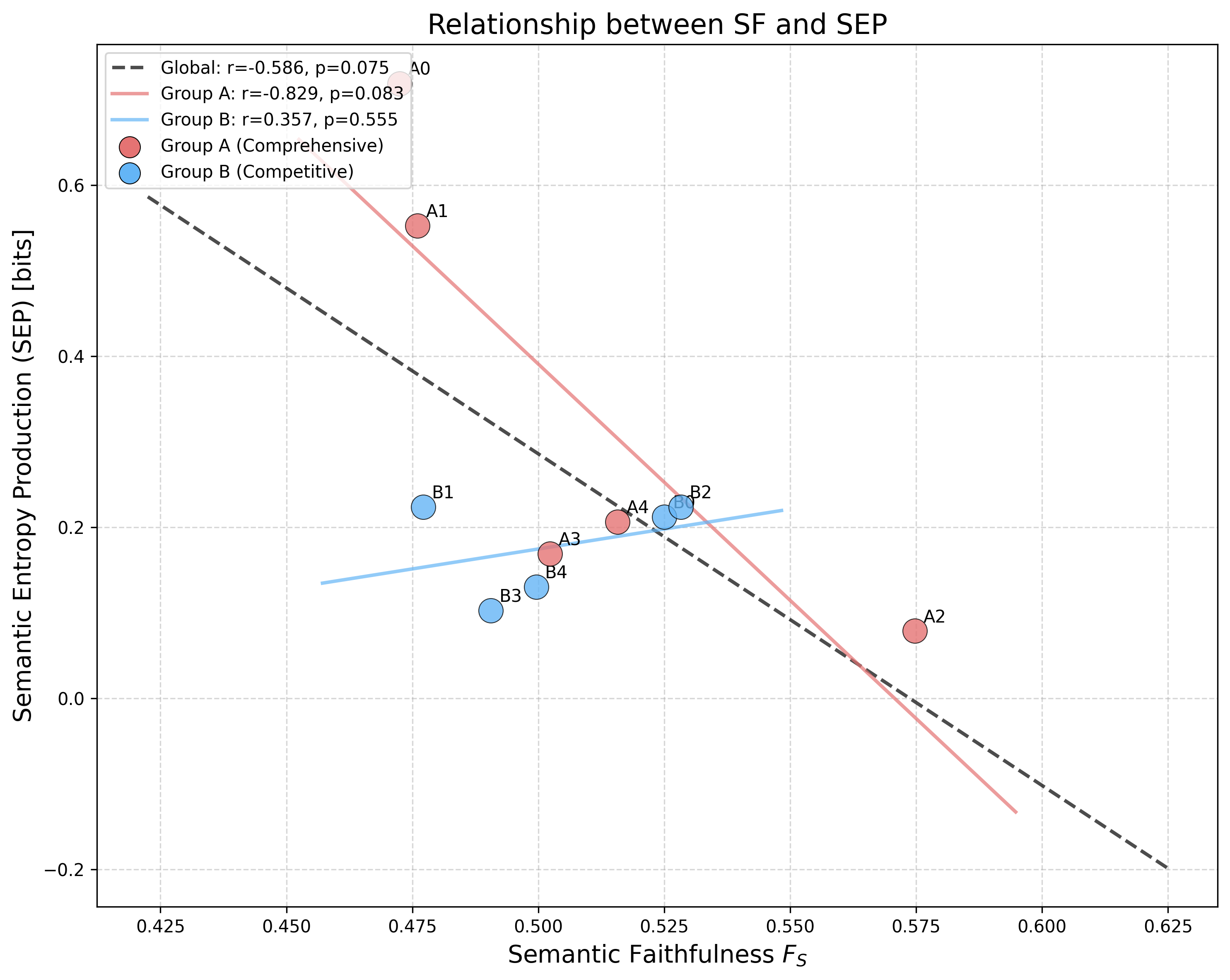
论文在公司SEC 10-K文件的LLM摘要任务上验证了所提出的框架。实验结果表明,SF指标能够有效区分忠实和不忠实的摘要,并且高忠实度通常伴随着低熵产生。这些结果表明,SF和SEP指标可以作为LLM评估和幻觉控制的有效工具。
🎯 应用场景
该研究成果可应用于各种需要LLM生成可靠信息的场景,例如金融报告摘要、法律文件分析、医疗诊断辅助等。通过使用SF和SEP指标,可以评估和筛选LLM生成的答案,降低幻觉风险,提高信息的可信度。此外,该研究为理解和改进LLM的内部机制提供了新的思路。
📄 摘要(原文)
Evaluating faithfulness of Large Language Models (LLMs) to a given task is a complex challenge. We propose two new unsupervised metrics for faithfulness evaluation using insights from information theory and thermodynamics. Our approach treats an LLM as a bipartite information engine where hidden layers act as a Maxwell demon controlling transformations of context $C $ into answer $A$ via prompt $Q$. We model Question-Context-Answer (QCA) triplets as probability distributions over shared topics. Topic transformations from $C$ to $Q$ and $A$ are modeled as transition matrices ${\bf Q}$ and ${\bf A}$ encoding the query goal and actual result, respectively. Our semantic faithfulness (SF) metric quantifies faithfulness for any given QCA triplet by the Kullback-Leibler (KL) divergence between these matrices. Both matrices are inferred simultaneously via convex optimization of this KL divergence, and the final SF metric is obtained by mapping the minimal divergence onto the unit interval [0,1], where higher scores indicate greater faithfulness. Furthermore, we propose a thermodynamics-based semantic entropy production (SEP) metric in answer generation, and show that high faithfulness generally implies low entropy production. The SF and SEP metrics can be used jointly or separately for LLM evaluation and hallucination control. We demonstrate our framework on LLM summarization of corporate SEC 10-K filings.