Model-Free Assessment of Simulator Fidelity via Quantile Curves
作者: Garud Iyengar, Yu-Shiou Willy Lin, Kaizheng Wang
分类: stat.ME, cs.AI, cs.LG
发布日期: 2025-12-04 (更新: 2026-01-31)
备注: 35 pages, 14 figures
💡 一句话要点
提出一种基于分位数曲线的无模型模拟器逼真度评估方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 模拟器逼真度 模型无关评估 分位数曲线 风险评估 置信集 大型语言模型 WorldValueBench
📋 核心要点
- 现有方法难以量化真实系统与模拟系统之间的差距,尤其是在数据量有限且异构的情况下。
- 该论文提出一种基于分位数曲线的无模型方法,通过构建置信集来评估模拟器的风险概况。
- 实验表明,该方法能够有效评估大型语言模型与人类价值观的对齐程度,并支持风险度量计算。
📝 摘要(中文)
随着生成式AI模型越来越多地用于模拟真实世界系统,量化“模拟到真实”的差距至关重要。真实输出和模拟输出之间的分布差异是由随机输入场景驱动的随机变量。一个根本的挑战是,对于任何给定的输入,真实输出和模拟输出的分布只能通过有限批次的样本观察到,而且样本大小通常是异构的。这使得标准预测推断方法不适用,因为它们试图量化可观察输出中的不确定性,而不是其潜在的总体参数。为了解决这个问题,我们为这些潜在参数构建置信集,并使用它们来推导模拟到真实差异的鲁棒代理。然后,我们估计这个代理的分位数函数,以提供模拟器的全面风险概况。我们的方法是模型无关的,并且可以处理一般的输出空间,例如分类调查响应和连续多维传感器数据。通过严格考虑抽样误差,由此产生的风险概况支持对新场景中真实输出分布的统计推断、条件风险价值 (CVaR) 等风险度量的计算,以及跨模拟器的原则性比较。我们通过评估四个主要LLM在WorldValueBench数据集上与人类群体的对齐程度,证明了该方法的实际效用。
🔬 方法详解
问题定义:论文旨在解决如何量化模拟器逼真度的问题,即评估模拟系统与真实系统输出分布之间的差异。现有方法在处理有限样本、异构样本大小以及一般输出空间(如分类数据和多维连续数据)时存在局限性,无法有效量化这种“模拟到真实”的差距。现有方法侧重于量化可观测输出的不确定性,而忽略了潜在总体参数的估计。
核心思路:论文的核心思路是构建潜在参数的置信集,并使用这些置信集来推导一个鲁棒的代理变量,用于表示模拟到真实的差异。通过估计该代理变量的分位数函数,可以获得模拟器的全面风险概况。这种方法是模型无关的,可以处理各种类型的输出空间,并能有效处理抽样误差。
技术框架:该方法主要包含以下几个阶段: 1. 数据收集:收集真实系统和模拟系统的输出样本,样本大小可能不同。 2. 置信集构建:为真实系统和模拟系统的潜在参数构建置信集。置信集的大小反映了参数估计的不确定性。 3. 差异代理计算:使用置信集来计算模拟到真实差异的鲁棒代理变量。该代理变量是对真实系统和模拟系统之间差异的保守估计。 4. 分位数函数估计:估计差异代理变量的分位数函数,从而获得模拟器的风险概况。 5. 风险评估与推断:利用风险概况进行统计推断,计算风险度量(如CVaR),并比较不同模拟器的性能。
关键创新:该方法最重要的创新点在于它提供了一种无模型的、基于置信集的模拟器逼真度评估方法。与传统方法相比,该方法不需要假设特定的模型结构,能够处理各种类型的输出空间,并且能够有效处理抽样误差。此外,通过估计差异代理变量的分位数函数,可以获得模拟器的全面风险概况,从而支持更全面的风险评估和决策。
关键设计:论文的关键设计包括: 1. 置信集构建方法:选择合适的置信集构建方法,例如基于bootstrap或贝叶斯方法的置信区间估计。 2. 差异代理变量的定义:设计一个鲁棒的代理变量,能够有效捕捉真实系统和模拟系统之间的差异,并对抽样误差具有鲁棒性。 3. 分位数函数估计方法:选择合适的分位数函数估计方法,例如基于核密度估计或经验分布函数的方法。 4. 风险度量计算方法:选择合适的风险度量,例如条件风险价值 (CVaR),并设计相应的计算方法。
🖼️ 关键图片


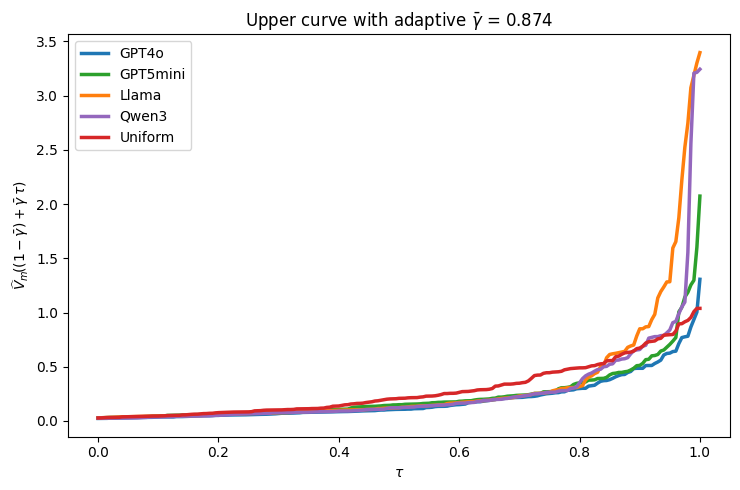
📊 实验亮点
论文通过在WorldValueBench数据集上评估四个大型语言模型与人类价值观的对齐程度,验证了该方法的有效性。实验结果表明,该方法能够有效区分不同模型的对齐程度,并支持风险度量(如CVaR)的计算。该方法为评估大型语言模型的社会影响提供了一种新的工具。
🎯 应用场景
该研究成果可广泛应用于各种需要模拟真实世界系统的领域,例如自动驾驶、金融建模、医疗诊断等。通过量化模拟器的逼真度,可以更好地评估模拟结果的可靠性,从而做出更明智的决策。此外,该方法还可以用于比较不同模拟器的性能,选择最合适的模拟器。
📄 摘要(原文)
As generative AI models are increasingly used to simulate real-world systems, quantifying the ``sim-to-real'' gap is critical. The distributional discrepancy between real and simulated outputs is a random variable driven by the stochastic input scenario. A fundamental challenge is that for any given input, the ground-truth and simulated output distributions are only observable through finite batches of samples, often of heterogeneous sizes. This renders standard predictive inference methods inapplicable, as they seek to quantify uncertainty in observable outputs rather than their underlying population parameters. To address this, we construct confidence sets for these latent parameters and use them to derive a robust proxy for the sim-to-real discrepancy. We then estimate the quantile function of this proxy to provide a comprehensive risk profile of the simulator. Our method is model-agnostic and handles general output spaces, such as categorical survey responses and continuous multi-dimensional sensor data. By rigorously accounting for sampling error, the resulting risk profile supports statistical inference for the real output distribution in a new scenario, the calculation of risk measures like Conditional Value-at-Risk (CVaR), and principled comparisons across simulators. We demonstrate the practical utility of this method by evaluating the alignment of four major LLMs with human populations on the WorldValueBench dataset.