Topology Matters: Measuring Memory Leakage in Multi-Agent LLMs
作者: Jinbo Liu, Defu Cao, Yifei Wei, Tianyao Su, Yuan Liang, Yushun Dong, Yan Liu, Yue Zhao, Xiyang Hu
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-12-04 (更新: 2026-01-12)
💡 一句话要点
提出MAMA框架以量化多智能体LLM系统中的记忆泄漏问题
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 多智能体系统 记忆泄漏 网络拓扑 数据保护 信息安全 大语言模型 攻击模型
📋 核心要点
- 现有方法对多智能体LLM系统中记忆泄漏的量化分析不足,缺乏对拓扑结构影响的深入理解。
- 本文提出MAMA框架,通过Engram和Resonance两个阶段,系统性地测量网络结构对记忆泄漏的影响。
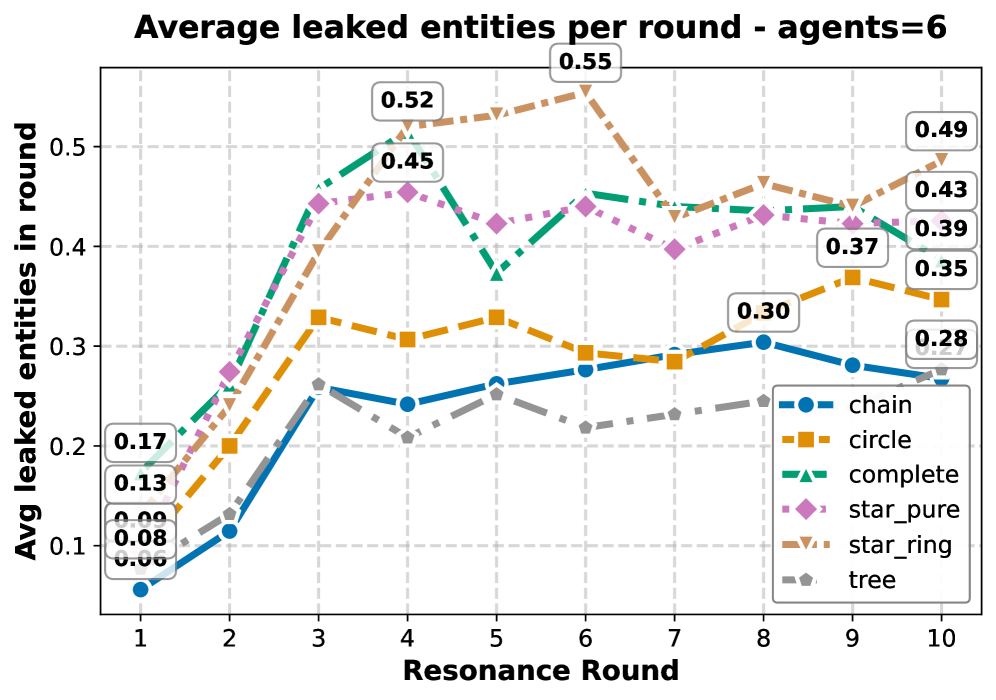
- 实验结果显示,密集连接和短距离会显著增加泄漏,且不同拓扑结构对泄漏的影响具有一致性。
📝 摘要(中文)
图形拓扑结构是多智能体大语言模型(LLM)系统中记忆泄漏的基本决定因素,但其影响尚未得到充分量化。本文提出了MAMA(多智能体记忆攻击)框架,用于测量网络结构如何影响泄漏。MAMA在包含标记的个人身份信息(PII)实体的合成文档上操作,生成经过清理的任务指令。我们执行了两个阶段的协议:Engram(将私人信息植入目标智能体的记忆中)和Resonance(攻击者尝试提取的多轮交互)。通过对六种经典拓扑结构的评估,结果表明:更密集的连接、更短的攻击者-目标距离和更高的目标中心性会增加泄漏,且大部分泄漏发生在早期轮次后趋于平稳。
🔬 方法详解
问题定义:本文旨在量化多智能体LLM系统中的记忆泄漏,现有方法未能充分考虑网络拓扑对泄漏的影响,导致对系统安全性的评估不足。
核心思路:MAMA框架通过模拟攻击者与目标智能体的交互,系统性地分析不同拓扑结构下的记忆泄漏情况,揭示网络结构对信息泄漏的影响机制。
技术框架:MAMA框架分为两个主要阶段:Engram阶段将私人信息植入目标智能体的记忆中,Resonance阶段则通过多轮交互测量信息泄漏。实验中评估六种经典拓扑结构的表现。
关键创新:MAMA框架的创新在于系统性地量化了网络拓扑对记忆泄漏的影响,提供了新的视角来理解多智能体系统的安全性,与现有方法相比,能够更准确地评估信息泄漏风险。
关键设计:实验中使用了六种拓扑结构(完全、环、链、树、星、星环),并在不同的攻击者-目标位置和基础模型下进行评估,确保了实验结果的全面性和可靠性。通过对比不同拓扑的泄漏情况,得出了实用的系统设计建议。
🖼️ 关键图片


📊 实验亮点
实验结果表明,密集连接和短攻击者-目标距离显著增加了记忆泄漏,且大部分泄漏发生在早期轮次。模型选择影响绝对泄漏率,但拓扑结构的影响顺序保持一致。研究提供了系统设计的实用建议,强调了稀疏或分层连接的重要性。
🎯 应用场景
该研究的潜在应用领域包括多智能体系统的安全设计、数据保护策略的优化以及智能体间交互的安全性评估。通过量化记忆泄漏,系统设计者可以更有效地构建安全的多智能体环境,降低敏感信息泄漏的风险,具有重要的实际价值和未来影响。
📄 摘要(原文)
Graph topology is a fundamental determinant of memory leakage in multi-agent LLM systems, yet its effects remain poorly quantified. We introduce MAMA (Multi-Agent Memory Attack), a framework that measures how network structure shapes leakage. MAMA operates on synthetic documents containing labeled Personally Identifiable Information (PII) entities, from which we generate sanitized task instructions. We execute a two-phase protocol: Engram (seeding private information into a target agent's memory) and Resonance (multi-round interaction where an attacker attempts extraction). Over 10 rounds, we measure leakage as exact-match recovery of ground-truth PII from attacker outputs. We evaluate six canonical topologies (complete, ring, chain, tree, star, star-ring) across $n\in{4,5,6}$, attacker-target placements, and base models. Results are consistent: denser connectivity, shorter attacker-target distance, and higher target centrality increase leakage; most leakage occurs in early rounds and then plateaus; model choice shifts absolute rates but preserves topology ordering; spatiotemporal/location attributes leak more readily than identity credentials or regulated identifiers. We distill practical guidance for system design: favor sparse or hierarchical connectivity, maximize attacker-target separation, and restrict hub/shortcut pathways via topology-aware access control.