Balancing Safety and Helpfulness in Healthcare AI Assistants through Iterative Preference Alignment
作者: Huy Nghiem, Swetasudha Panda, Devashish Khatwani, Huy V. Nguyen, Krishnaram Kenthapadi, Hal Daumé
分类: cs.AI, cs.CL, cs.CY
发布日期: 2025-12-03
备注: ML4H 2025 Proceedings, Best Paper Award
💡 一句话要点
提出迭代偏好对齐框架,提升医疗AI助手安全性和实用性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医疗AI助手 大型语言模型 安全性 偏好对齐 迭代优化
📋 核心要点
- 医疗AI助手面临安全挑战,需避免有害回复和过度拒绝,现有方法难以兼顾。
- 提出迭代偏好对齐框架,利用KTO和DPO,针对领域安全信号优化模型。
- 实验表明,该方法显著提升有害查询检测安全性,并揭示模型架构对校准的影响。
📝 摘要(中文)
大型语言模型(LLMs)在医疗保健领域的应用日益广泛,但确保其安全性和可信赖性仍然是部署的障碍。对话式医疗助手必须避免不安全的行为,同时避免过度拒绝良性查询。本文提出了一种迭代的后部署对齐框架,该框架应用Kahneman-Tversky优化(KTO)和直接偏好优化(DPO)来针对特定领域的安全信号改进模型。使用CARES-18K基准测试对抗鲁棒性,我们评估了四个LLM(Llama-3B/8B、Meditron-8B、Mistral-7B)在多个周期中的表现。结果表明,有害查询检测的安全相关指标提高了高达42%,同时也发现了与错误拒绝之间的有趣权衡,从而揭示了依赖于架构的校准偏差。我们还进行了消融研究,以确定何时自我评估是可靠的,以及何时需要外部或微调的评估者来最大化性能提升。我们的研究结果强调了在对话式医疗助手的设计中,采用平衡患者安全、用户信任和临床效用的最佳实践的重要性。
🔬 方法详解
问题定义:医疗AI助手在实际应用中面临着安全性和实用性的双重挑战。一方面,模型需要避免生成有害或误导性的医疗建议,以保障患者安全。另一方面,模型不应过度保守,拒绝回答良性的医疗查询,从而影响用户体验和临床效用。现有的方法往往难以在这两者之间取得平衡,容易出现“unsafe compliance”(不安全顺从)或“erroneous refusals”(错误拒绝)的问题。
核心思路:本文的核心思路是通过迭代的后部署对齐,不断优化模型的行为,使其更好地符合医疗领域的安全标准和用户需求。具体来说,作者利用Kahneman-Tversky Optimization (KTO) 和 Direct Preference Optimization (DPO) 两种偏好优化方法,根据模型在特定安全信号上的表现,对其进行微调。这种迭代优化的方式能够逐步提升模型的安全性和实用性,并允许在两者之间进行权衡。
技术框架:该框架主要包含以下几个阶段:1) 数据收集:收集包含安全和非安全医疗查询的数据集,例如CARES-18K。2) 模型初始化:选择预训练的大型语言模型作为基础模型,例如Llama、Meditron、Mistral等。3) 偏好学习:使用KTO或DPO等偏好优化方法,根据安全信号对模型进行微调。安全信号可以是人工标注的偏好数据,也可以是模型自身的评估结果。4) 迭代优化:重复步骤3,不断优化模型,直到达到预期的安全性和实用性水平。5) 评估:使用特定的指标(如有害查询检测准确率、错误拒绝率)评估模型的性能。
关键创新:该论文的关键创新在于提出了一个迭代的后部署对齐框架,能够有效地提升医疗AI助手的安全性和实用性。与传统的预训练或微调方法相比,该框架能够根据实际应用中的反馈,不断优化模型的行为,使其更好地适应特定领域的需求。此外,该论文还探讨了不同偏好优化方法(KTO和DPO)的优缺点,以及如何选择合适的评估方法,以最大化性能提升。
关键设计:在偏好学习阶段,作者使用了KTO和DPO两种方法。KTO是一种基于对比学习的优化方法,它通过最大化模型对安全回复的偏好,同时最小化对不安全回复的偏好,来提升模型的安全性。DPO则是一种直接优化偏好的方法,它通过直接优化模型对不同回复的偏好概率,来提升模型的性能。在评估阶段,作者使用了多种指标,包括有害查询检测准确率、错误拒绝率等,以全面评估模型的安全性和实用性。此外,作者还进行了消融研究,以确定何时自我评估是可靠的,以及何时需要外部或微调的评估者。
🖼️ 关键图片
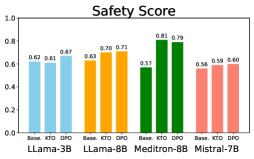
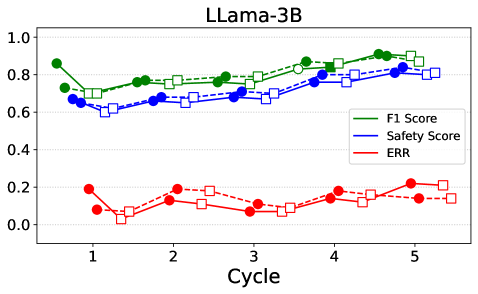
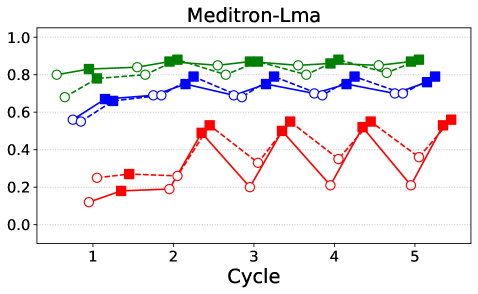
📊 实验亮点
实验结果表明,该方法在CARES-18K基准测试中,将有害查询检测的安全相关指标提高了高达42%。同时,研究揭示了不同模型架构在安全性和实用性之间的权衡,以及模型校准偏差。消融实验表明,在某些情况下,自我评估是可靠的,但在其他情况下,需要外部或微调的评估者来最大化性能提升。
🎯 应用场景
该研究成果可应用于开发更安全、更可靠的医疗AI助手,辅助医生进行诊断和治疗决策,为患者提供个性化的健康建议。通过迭代优化,可以不断提升AI助手在实际应用中的表现,增强用户信任,促进医疗AI的广泛应用。未来,该框架还可扩展到其他高风险领域,如金融、法律等。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used in healthcare, yet ensuring their safety and trustworthiness remains a barrier to deployment. Conversational medical assistants must avoid unsafe compliance without over-refusing benign queries. We present an iterative post-deployment alignment framework that applies Kahneman-Tversky Optimization (KTO) and Direct Preference Optimization (DPO) to refine models against domain-specific safety signals. Using the CARES-18K benchmark for adversarial robustness, we evaluate four LLMs (Llama-3B/8B, Meditron-8B, Mistral-7B) across multiple cycles. Our results show up to 42% improvement in safety-related metrics for harmful query detection, alongside interesting trade-offs against erroneous refusals, thereby exposing architecture-dependent calibration biases. We also perform ablation studies to identify when self-evaluation is reliable and when external or finetuned judges are necessary to maximize performance gains. Our findings underscore the importance of adopting best practices that balance patient safety, user trust, and clinical utility in the design of conversational medical assistants.