SELF: A Robust Singular Value and Eigenvalue Approach for LLM Fingerprinting
作者: Hanxiu Zhang, Yue Zheng
分类: cs.CR, cs.AI, cs.CL, cs.LG
发布日期: 2025-12-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出SELF,一种基于奇异值和特征值的LLM稳健指纹识别方法,解决现有方法易受攻击的问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指纹识别 知识产权保护 奇异值分解 特征值分解
📋 核心要点
- 现有LLM指纹识别方法易受虚假声明攻击和权重操纵,无法有效保护模型知识产权。
- SELF通过奇异值和特征值分解提取LLM注意力权重的不变指纹,并使用神经网络进行相似度比较。
- 实验表明,SELF在保持高检测精度的同时,对量化、剪枝和微调等攻击具有很强的鲁棒性。
📝 摘要(中文)
大型语言模型(LLM)中知识产权(IP)的保护是当前人工智能研究中的一个关键挑战。指纹识别技术已成为检测未经授权模型使用的基本机制,但现有的方法——无论是基于行为的还是基于结构的——都存在诸如虚假声明攻击或易受权重操纵等漏洞。为了克服这些限制,我们提出了一种新颖的、基于内在权重的指纹识别方案SELF,该方案消除了对输入的依赖,并且本质上可以抵抗虚假声明。SELF通过两个关键创新实现了强大的IP保护:1)通过LLM注意力权重的奇异值和特征值分解实现独特的、可扩展的和变换不变的指纹提取;2)基于少样本学习和数据增强的有效神经网络指纹相似度比较。实验结果表明,SELF在保持高IP侵权检测精度的同时,对各种下游修改(包括量化、剪枝和微调攻击)表现出强大的鲁棒性。我们的代码可在https://github.com/HanxiuZhang/SELF_v2 获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的知识产权保护问题。现有的指纹识别方法,如基于行为或结构的方案,容易受到虚假声明攻击或权重篡改的影响,导致无法可靠地检测未经授权的模型使用。这些方法的痛点在于对输入数据的依赖性以及对模型微小改动的敏感性。
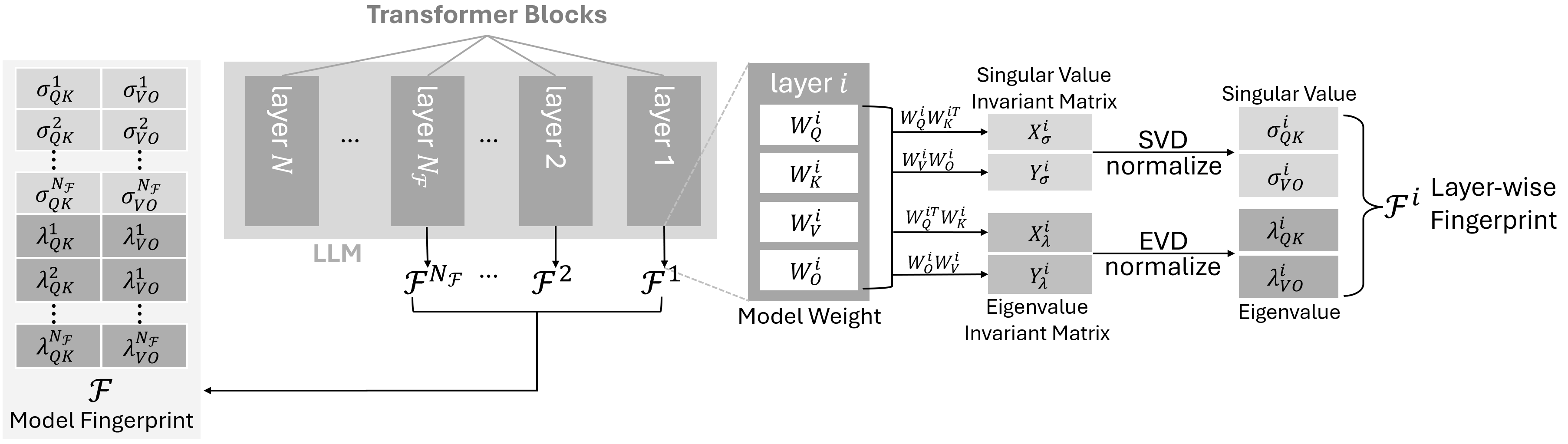
核心思路:SELF的核心思路是利用LLM内部权重矩阵的固有属性来生成指纹,从而避免对输入数据的依赖。具体而言,它通过对LLM注意力权重矩阵进行奇异值分解(SVD)和特征值分解(EVD),提取出具有变换不变性的指纹。这种方法的设计理念是,SVD和EVD能够捕捉到权重矩阵的本质结构信息,即使模型经过微调、剪枝或量化等操作,这些结构信息仍然能够保持相对稳定。
技术框架:SELF的整体框架包括两个主要阶段:指纹提取和指纹匹配。在指纹提取阶段,首先对LLM的注意力权重矩阵进行SVD和EVD,得到相应的奇异值和特征值。然后,将这些值作为指纹的表示。在指纹匹配阶段,使用一个神经网络来比较两个指纹的相似度。该神经网络采用少样本学习和数据增强技术,以提高匹配的准确性和鲁棒性。
关键创新:SELF最重要的技术创新在于其指纹提取方法,即利用SVD和EVD从LLM注意力权重中提取变换不变的指纹。与现有方法相比,SELF的指纹不依赖于输入数据,因此可以抵抗虚假声明攻击。此外,SVD和EVD提取的指纹对模型微小改动具有鲁棒性,从而提高了对各种下游攻击的抵抗能力。
关键设计:SELF的关键设计包括:1) 选择注意力权重矩阵作为指纹提取的来源,因为注意力机制在LLM中起着关键作用,其权重包含了重要的模型结构信息。2) 使用SVD和EVD提取奇异值和特征值,这些值对权重矩阵的旋转、缩放等变换具有不变性。3) 使用神经网络进行指纹相似度比较,并采用少样本学习和数据增强技术来提高匹配的准确性和鲁棒性。具体的网络结构和损失函数等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SELF在保持高IP侵权检测精度的同时,对各种下游修改(包括量化、剪枝和微调攻击)表现出强大的鲁棒性。具体的性能数据和对比基线在摘要中未提供,详细结果需要在论文中进一步查阅。SELF通过独特的指纹提取方法和神经网络相似度比较,显著提升了LLM指纹识别的可靠性和安全性。
🎯 应用场景
SELF可应用于LLM的知识产权保护,帮助模型开发者检测未经授权的模型使用和侵权行为。该技术能够有效防止模型被非法复制、篡改或用于商业用途,从而维护开发者的合法权益,促进人工智能领域的健康发展。未来,SELF还可扩展到其他类型的深度学习模型,提供更广泛的知识产权保护。
📄 摘要(原文)
The protection of Intellectual Property (IP) in Large Language Models (LLMs) represents a critical challenge in contemporary AI research. While fingerprinting techniques have emerged as a fundamental mechanism for detecting unauthorized model usage, existing methods -- whether behavior-based or structural -- suffer from vulnerabilities such as false claim attacks or susceptible to weight manipulations. To overcome these limitations, we propose SELF, a novel intrinsic weight-based fingerprinting scheme that eliminates dependency on input and inherently resists false claims. SELF achieves robust IP protection through two key innovations: 1) unique, scalable and transformation-invariant fingerprint extraction via singular value and eigenvalue decomposition of LLM attention weights, and 2) effective neural network-based fingerprint similarity comparison based on few-shot learning and data augmentation. Experimental results demonstrate SELF maintains high IP infringement detection accuracy while showing strong robustness against various downstream modifications, including quantization, pruning, and fine-tuning attacks. Our code is available at https://github.com/HanxiuZhang/SELF_v2.