M3DR: Towards Universal Multilingual Multimodal Document Retrieval
作者: Adithya S Kolavi, Vyoman Jain
分类: cs.IR, cs.AI, cs.CL, cs.CV
发布日期: 2025-12-03
💡 一句话要点
提出M3DR框架,解决多语言多模态文档检索中现有方法对英语的过度依赖问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言文档检索 多模态学习 跨语言检索 对比学习 合成数据
📋 核心要点
- 现有方法在多模态文档检索中过度依赖英语,限制了其在多语言环境下的应用。
- M3DR框架利用合成多语言数据和对比学习,学习跨语言和跨模态的统一表示。
- 实验结果表明,M3DR在22种语言上表现出一致的性能,并在跨语言检索方面取得了显著提升。
📝 摘要(中文)
多模态文档检索系统在对齐视觉和文本内容以进行语义搜索方面取得了显著进展。然而,现有方法大多以英语为中心,限制了其在多语言环境中的有效性。本文提出了M3DR(多语言多模态文档检索)框架,旨在弥合语言之间的差距,使其能够应用于不同的语言和文化背景。M3DR利用合成的多语言文档数据,并可推广到不同的视觉-语言架构和模型大小,从而实现鲁棒的跨语言和跨模态对齐。通过对比学习,模型学习文本和文档图像的统一表示,从而有效地跨语言迁移。在22种类型多样的语言上验证了该能力,证明了其在语言和脚本变体中的一致性能和适应性。进一步引入了一个综合基准,捕捉了真实的多语言场景,并在单语、多语和混合语言设置下评估模型。M3DR可推广到单密集向量和ColBERT风格的token级多向量检索范式。模型NetraEmbed和ColNetraEmbed实现了最先进的性能,在跨语言检索方面实现了约150%的相对改进。
🔬 方法详解
问题定义:现有的多模态文档检索系统主要集中在英语语境下,缺乏对其他语言的支持。这限制了它们在多语言环境中的应用,无法有效处理包含多种语言的文档检索任务。现有方法难以在不同语言和模态之间建立有效的语义关联,导致跨语言检索性能不佳。
核心思路:M3DR的核心思路是利用合成的多语言文档数据,通过对比学习训练模型,使其能够学习到跨语言和跨模态的统一表示。通过这种方式,模型可以更好地理解不同语言和模态之间的语义关系,从而提高跨语言文档检索的性能。
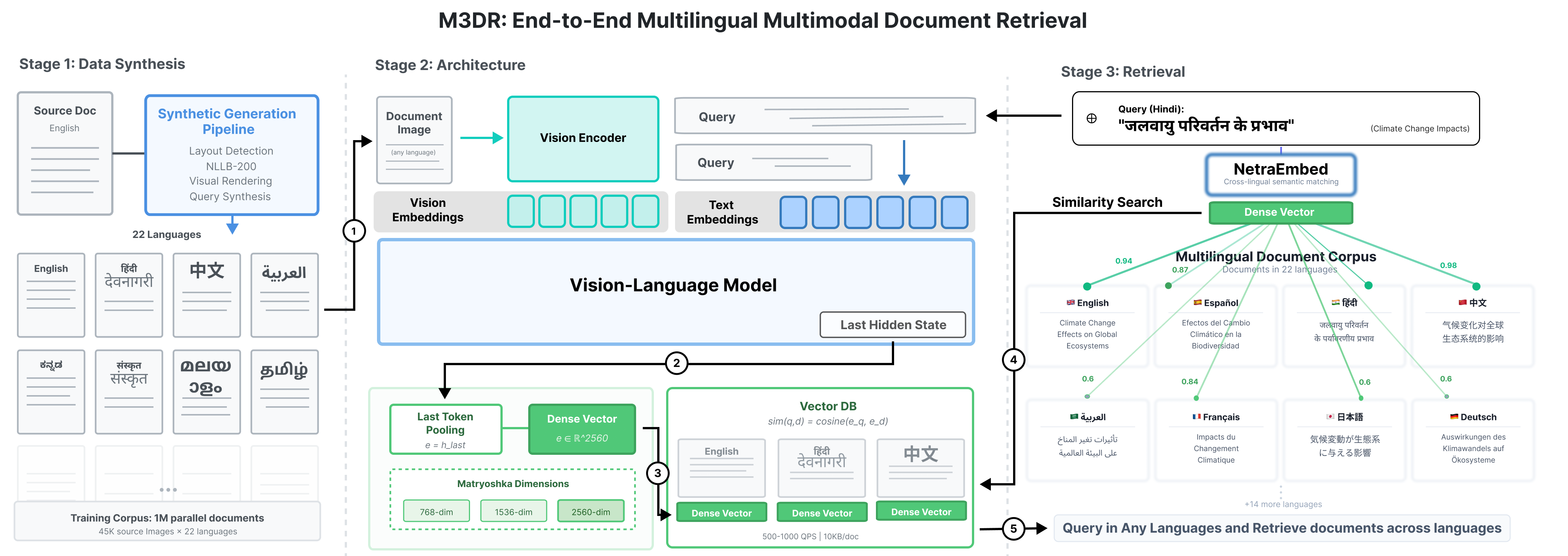
技术框架:M3DR框架包含数据合成模块、模型训练模块和评估模块。数据合成模块负责生成多语言文档数据,包括文本和图像。模型训练模块使用对比学习方法,训练模型学习跨语言和跨模态的统一表示。评估模块使用提出的多语言基准测试模型在不同语言环境下的检索性能。该框架可以应用于不同的视觉-语言架构和模型大小。
关键创新:M3DR的关键创新在于其利用合成数据进行多语言多模态文档检索,并提出了一个综合性的多语言基准。通过合成数据,可以有效地扩展训练数据的规模和多样性,从而提高模型的泛化能力。多语言基准能够更全面地评估模型在不同语言环境下的检索性能。
关键设计:M3DR使用对比学习损失函数,鼓励模型将语义相似的文本和图像映射到相近的向量空间中。具体而言,模型使用InfoNCE损失函数,最大化正样本对(即同一文档的文本和图像)之间的相似度,同时最小化负样本对之间的相似度。模型支持单密集向量表示(NetraEmbed)和ColBERT风格的token级多向量表示(ColNetraEmbed)。
🖼️ 关键图片

📊 实验亮点
M3DR在跨语言检索方面取得了显著的性能提升,在提出的多语言基准测试中,NetraEmbed和ColNetraEmbed模型实现了最先进的性能,相对现有方法取得了约150%的性能提升。实验结果表明,M3DR能够有效地处理不同语言和脚本的文档检索任务,具有良好的泛化能力。
🎯 应用场景
M3DR可应用于多语言文档检索、跨语言信息检索、多模态机器翻译等领域。该研究有助于构建更加通用和智能的文档检索系统,促进不同语言和文化之间的信息交流。未来,M3DR可以扩展到更多的语言和模态,并应用于更广泛的实际场景。
📄 摘要(原文)
Multimodal document retrieval systems have shown strong progress in aligning visual and textual content for semantic search. However, most existing approaches remain heavily English-centric, limiting their effectiveness in multilingual contexts. In this work, we present M3DR (Multilingual Multimodal Document Retrieval), a framework designed to bridge this gap across languages, enabling applicability across diverse linguistic and cultural contexts. M3DR leverages synthetic multilingual document data and generalizes across different vision-language architectures and model sizes, enabling robust cross-lingual and cross-modal alignment. Using contrastive training, our models learn unified representations for text and document images that transfer effectively across languages. We validate this capability on 22 typologically diverse languages, demonstrating consistent performance and adaptability across linguistic and script variations. We further introduce a comprehensive benchmark that captures real-world multilingual scenarios, evaluating models under monolingual, multilingual, and mixed-language settings. M3DR generalizes across both single dense vector and ColBERT-style token-level multi-vector retrieval paradigms. Our models, NetraEmbed and ColNetraEmbed achieve state-of-the-art performance with ~150% relative improvements on cross-lingual retrieval.