Towards Contextual Sensitive Data Detection
作者: Liang Telkamp, Madelon Hulsebos
分类: cs.CR, cs.AI, cs.CL, cs.CY, cs.DB, cs.IR
发布日期: 2025-12-02
🔗 代码/项目: GITHUB
💡 一句话要点
提出上下文敏感数据检测方法,提升开放数据场景下的隐私保护能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 敏感数据检测 上下文感知 数据隐私 开放数据 大型语言模型
📋 核心要点
- 现有敏感数据检测方法主要关注个人数据,忽略了数据敏感性与上下文的关联,导致误报率高,适用范围窄。
- 论文提出类型上下文和领域上下文两种机制,利用数据集内部和外部信息,更准确地识别敏感数据。
- 实验表明,类型上下文显著降低了误报率,领域上下文在人道主义数据集等非标准领域表现良好,并能提供有用的解释。
📝 摘要(中文)
开放数据门户的兴起使得在数据集发布和交换之前保护敏感数据变得至关重要。虽然抑制敏感数据的方法很多,但对敏感数据的概念化和检测方法主要集中在个人数据上,如果披露这些数据可能会造成损害或侵犯隐私。我们认为有必要改进和扩展敏感数据的定义,并认为数据的敏感性取决于其上下文。基于此,我们引入了两种上下文敏感数据检测机制,它们考虑了手头数据集的更广泛的上下文。首先,我们引入了类型上下文,它首先检测特定数据值的语义类型,然后考虑数据集或文档中数据值的整体上下文。其次,我们引入了领域上下文,它基于从指定数据敏感性的文档(例如,数据主题和地理来源)中检索到的相关规则,确定给定数据集在更广泛的上下文中的敏感性。借助大型语言模型(LLM)进行的实验证实:1)类型上下文显著减少了基于类型的敏感数据检测的误报数量,并且与商业工具的63%相比,达到了94%的召回率;2)利用敏感性规则检索的领域上下文对于人道主义数据集等非标准数据领域中的上下文敏感数据检测是有效的。与人道主义数据专家的评估还表明,上下文相关的LLM解释为手动数据审计过程提供了有用的指导,从而提高了数据一致性。我们在https://github.com/trl-lab/sensitive-data-detection上开源了上下文敏感数据检测的机制和带注释的数据集。
🔬 方法详解
问题定义:现有敏感数据检测方法主要关注个人身份信息(PII)等显式敏感数据,忽略了数据在特定上下文中的敏感性。例如,一个数值本身可能不敏感,但在特定领域或与其他数据结合时可能变得敏感。现有方法缺乏对上下文的理解,导致误报和漏报,难以满足开放数据场景下的隐私保护需求。
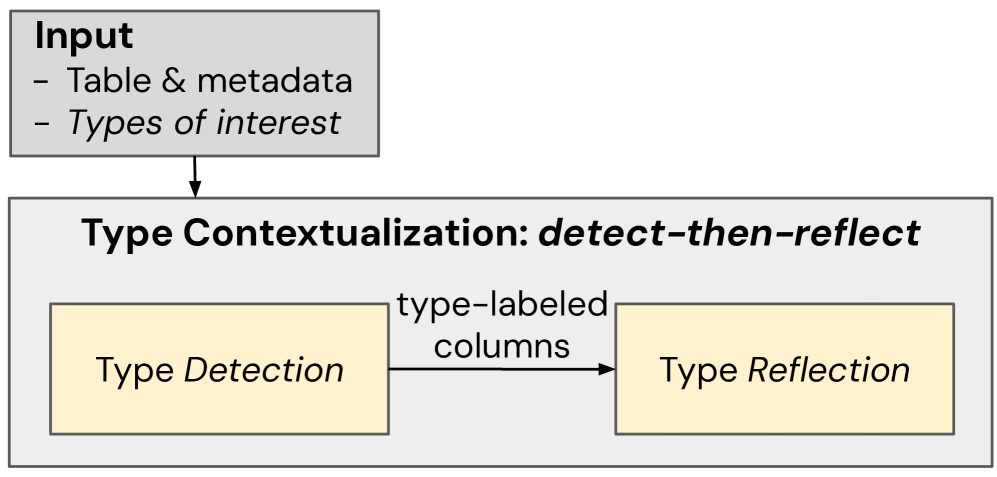
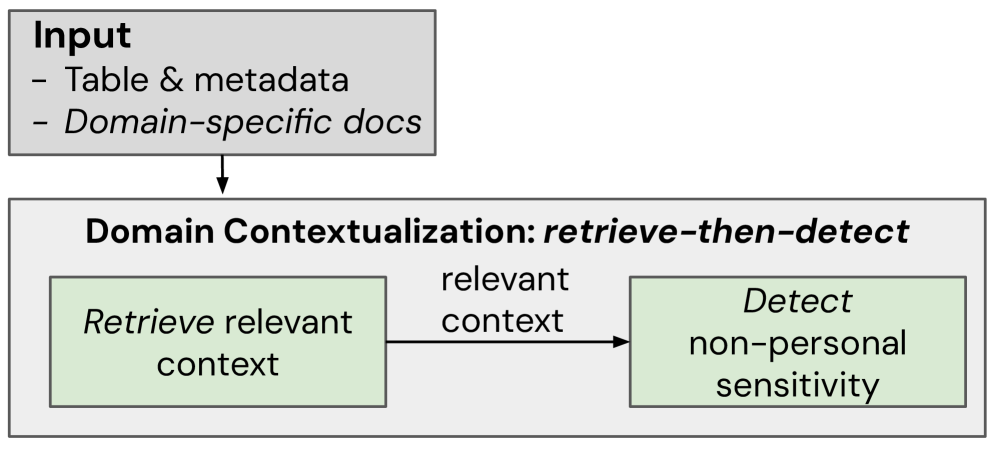
核心思路:论文的核心思路是引入上下文信息来辅助敏感数据检测。具体而言,论文提出了两种上下文感知机制:类型上下文(Type Contextualization)和领域上下文(Domain Contextualization)。类型上下文关注数据集内部的数据类型和语义关系,领域上下文则关注数据集外部的领域知识和敏感性规则。通过结合这两种上下文信息,可以更准确地判断数据的敏感性。
技术框架:整体框架包含两个主要模块:类型上下文模块和领域上下文模块。类型上下文模块首先使用预训练模型或规则引擎识别数据值的语义类型,然后根据数据集内的其他数据值和关系,判断该数据值是否敏感。领域上下文模块则从外部知识库(例如,包含敏感性规则的文档)中检索相关规则,并利用这些规则判断数据集的敏感性。两个模块的结果可以结合使用,以提高检测的准确性。
关键创新:论文的关键创新在于将上下文信息引入到敏感数据检测中。传统的敏感数据检测方法主要依赖于预定义的规则和模式,缺乏对数据含义的理解。通过引入类型上下文和领域上下文,论文能够更全面地考虑数据的敏感性,并减少误报和漏报。此外,论文还利用大型语言模型(LLM)来辅助上下文信息的提取和推理,进一步提高了检测的准确性和效率。
关键设计:类型上下文模块的关键设计在于如何有效地利用数据集内部的数据类型和语义关系。论文使用了预训练的语言模型来识别数据值的语义类型,并设计了一种基于图的算法来表示数据值之间的关系。领域上下文模块的关键设计在于如何从外部知识库中检索相关规则。论文使用了基于文本相似度的检索方法,并利用LLM对检索到的规则进行推理和过滤。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,类型上下文机制显著降低了敏感数据检测的误报率,召回率从商业工具的63%提升到94%。领域上下文机制在人道主义数据集等非标准数据领域表现良好,并且LLM提供的上下文解释有助于提高数据审计的一致性。这些结果验证了上下文敏感数据检测方法的有效性和实用性。
🎯 应用场景
该研究成果可应用于开放数据平台、数据共享环境和数据治理等领域。通过更准确地检测和保护敏感数据,可以促进数据的安全共享和利用,同时降低数据泄露的风险。该方法还有助于提高数据审计的效率和一致性,为数据驱动的决策提供更可靠的基础。
📄 摘要(原文)
The emergence of open data portals necessitates more attention to protecting sensitive data before datasets get published and exchanged. While an abundance of methods for suppressing sensitive data exist, the conceptualization of sensitive data and methods to detect it, focus particularly on personal data that, if disclosed, may be harmful or violate privacy. We observe the need for refining and broadening our definitions of sensitive data, and argue that the sensitivity of data depends on its context. Based on this definition, we introduce two mechanisms for contextual sensitive data detection that consider the broader context of a dataset at hand. First, we introduce type contextualization, which first detects the semantic type of particular data values, then considers the overall context of the data values within the dataset or document. Second, we introduce domain contextualization which determines sensitivity of a given dataset in the broader context based on the retrieval of relevant rules from documents that specify data sensitivity (e.g., data topic and geographic origin). Experiments with these mechanisms, assisted by large language models (LLMs), confirm that: 1) type-contextualization significantly reduces the number of false positives for type-based sensitive data detection and reaches a recall of 94% compared to 63% with commercial tools, and 2) domain-contextualization leveraging sensitivity rule retrieval is effective for context-grounded sensitive data detection in non-standard data domains such as humanitarian datasets. Evaluation with humanitarian data experts also reveals that context-grounded LLM explanations provide useful guidance in manual data auditing processes, improving consistency. We open-source mechanisms and annotated datasets for contextual sensitive data detection at https://github.com/trl-lab/sensitive-data-detection.