LLM CHESS: Benchmarking Reasoning and Instruction-Following in LLMs through Chess
作者: Sai Kolasani, Maxim Saplin, Nicholas Crispino, Kyle Montgomery, Jared Quincy Davis, Matei Zaharia, Chi Wang, Chenguang Wang
分类: cs.AI, cs.CL
发布日期: 2025-12-01
💡 一句话要点
提出LLM CHESS框架以评估LLMs的推理与指令遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 指令遵循 国际象棋 评估框架 动态对弈 行为指标 Elo估计
📋 核心要点
- 现有方法在评估大型语言模型的推理和指令遵循能力时,往往面临过拟合和记忆化的问题。
- LLM CHESS框架通过国际象棋的动态对弈,提供了一种新的评估方式,旨在减少模型的过拟合现象。
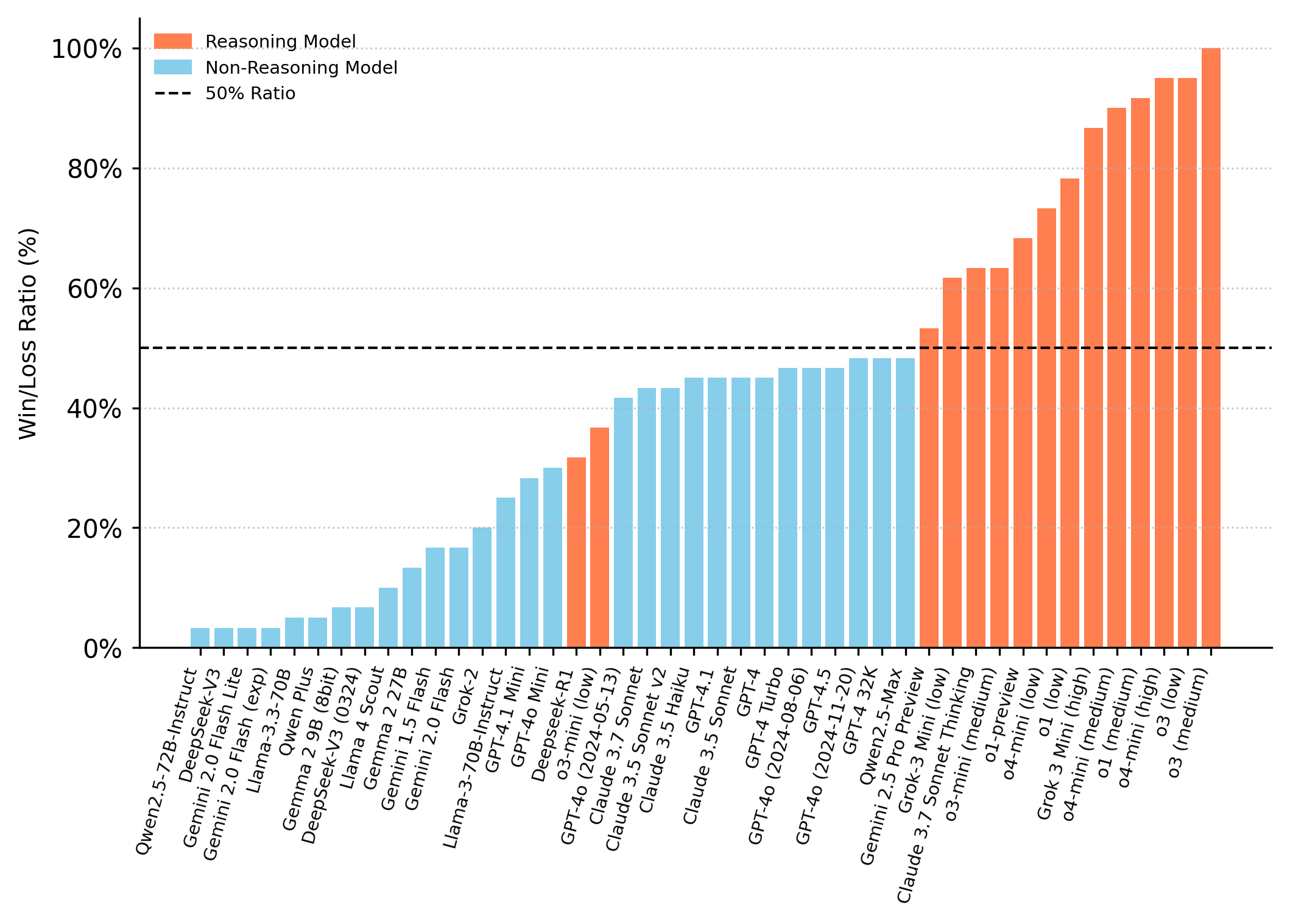
- 实验结果显示,许多最先进的模型在简单的指令遵循任务中仍然难以实现一致的胜利,揭示了推理能力的不足。
📝 摘要(中文)
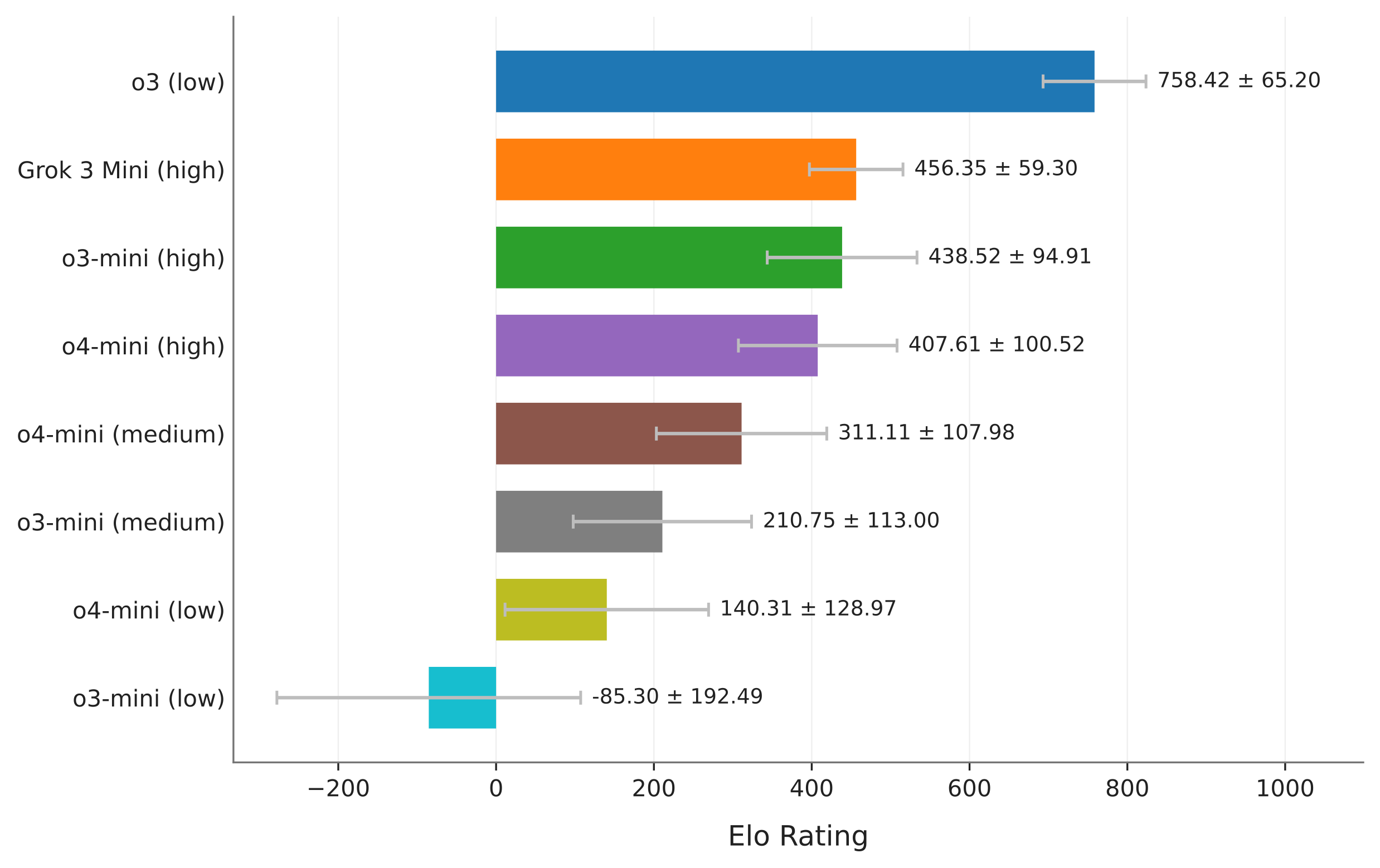
我们介绍了LLM CHESS,一个评估框架,旨在通过在国际象棋领域的扩展智能交互来探测大型语言模型(LLMs)的推理和指令遵循能力的泛化。我们通过与随机对手对弈,使用多种行为指标对50多个开源和闭源模型进行排名,包括胜负率、走棋质量、走棋合法性、幻觉行为和游戏时长。对于一部分顶尖推理模型,我们通过与不同技能配置的国际象棋引擎对弈,推导出Elo估计,从而以易于理解的方式进行模型间比较。尽管指令遵循任务相对简单且对手较弱,许多最先进的模型在完成游戏或实现一致胜利方面仍然面临挑战。我们的实验揭示了推理模型与非推理模型之间的明显差异,并且LLM CHESS的随机和动态特性有效减少了过拟合和记忆化,防止了基准饱和,甚至对顶尖推理模型也构成了挑战。为了支持未来对LLMs推理和指令遵循的评估工作,我们发布了实验框架、公共排行榜和相关游戏数据集。
🔬 方法详解
问题定义:本研究旨在解决现有评估框架在测试大型语言模型推理和指令遵循能力时的不足,特别是过拟合和记忆化现象。
核心思路:LLM CHESS通过引入动态和随机的国际象棋对弈,提供了一种新的评估方式,能够有效测试模型的泛化能力和推理能力。
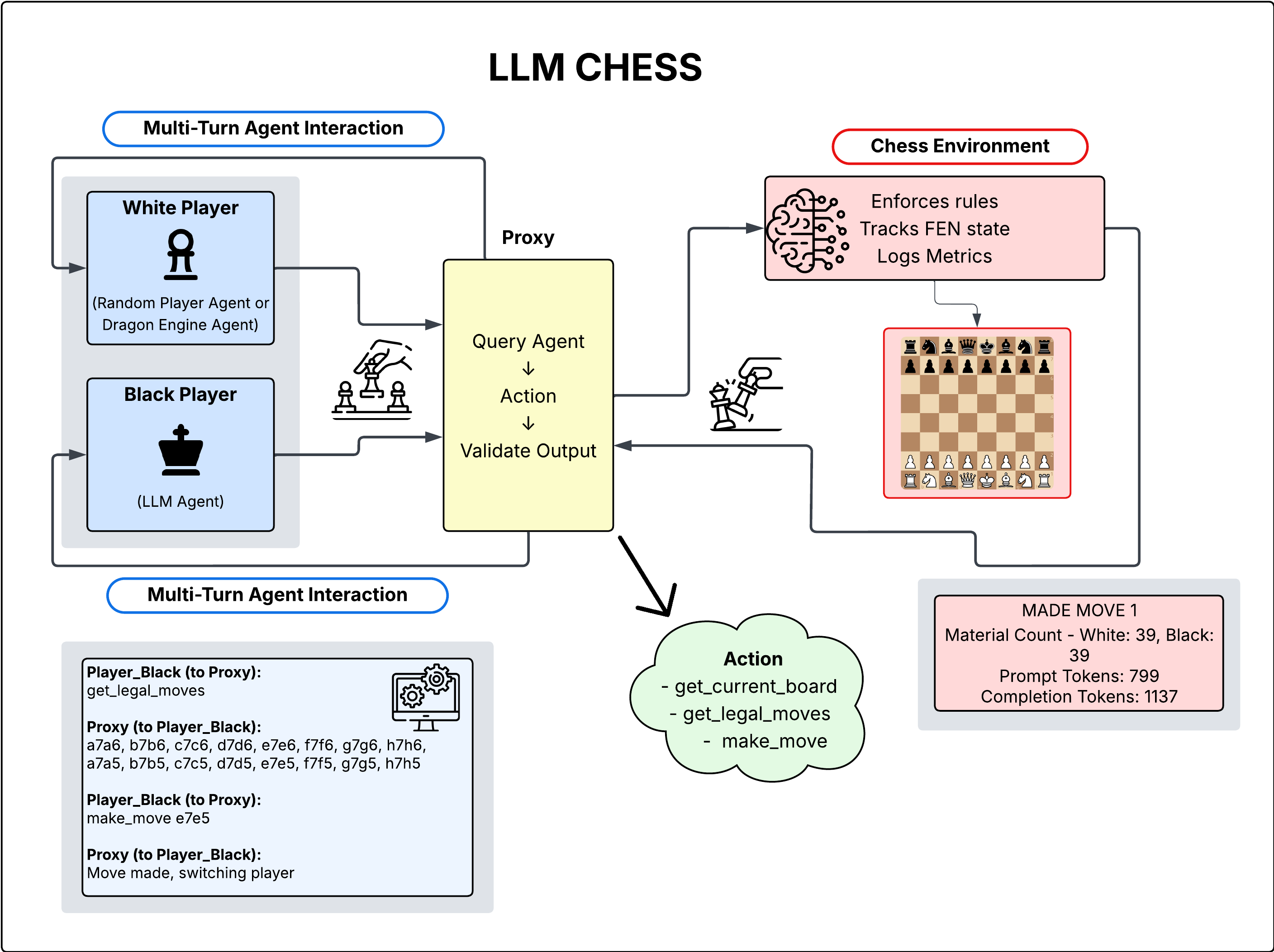
技术框架:该框架包括多个模块:模型选择、对弈过程、行为指标评估和结果分析。模型通过与随机对手进行对弈,收集行为数据并进行评估。
关键创新:LLM CHESS的随机性和动态性是其核心创新点,这种设计有效减少了模型的过拟合和记忆化现象,与现有静态基准测试方法形成鲜明对比。
关键设计:在实验中,模型的行为指标包括胜负率、走棋质量和游戏时长等,Elo估计则通过与不同技能水平的国际象棋引擎对弈得出,确保了评估的准确性和可比性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,尽管对手较弱,许多最先进的模型在完成游戏或实现一致胜利方面仍然面临挑战,表明推理能力的不足。LLM CHESS有效减少了过拟合现象,提供了更具挑战性的评估标准。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、游戏AI和教育等。通过评估大型语言模型的推理和指令遵循能力,LLM CHESS可以为模型的改进和优化提供重要依据,推动智能体在复杂任务中的表现提升。
📄 摘要(原文)
We introduce LLM CHESS, an evaluation framework designed to probe the generalization of reasoning and instruction-following abilities in large language models (LLMs) through extended agentic interaction in the domain of chess. We rank over 50 open and closed source models by playing against a random opponent using a range of behavioral metrics, including win and loss rates, move quality, move legality, hallucinated actions, and game duration. For a subset of top reasoning models, we derive an Elo estimate by playing against a chess engine with variably configured skill, which allows for comparisons between models in an easily understandable way. Despite the simplicity of the instruction-following task and the weakness of the opponent, many state-of-the-art models struggle to complete games or achieve consistent wins. Similar to other benchmarks on complex reasoning tasks, our experiments reveal a clear separation between reasoning and non-reasoning models. However, unlike existing static benchmarks, the stochastic and dynamic nature of LLM CHESS uniquely reduces overfitting and memorization while preventing benchmark saturation, proving difficult even for top reasoning models. To support future work on evaluating reasoning and instruction-following in LLMs, we release our experimental framework, a public leaderboard, and a dataset of associated games.