Retrieval-Augmented Few-Shot Prompting Versus Fine-Tuning for Code Vulnerability Detection
作者: Fouad Trad, Ali Chehab
分类: cs.SE, cs.AI, cs.CL, cs.CR
发布日期: 2025-11-28
备注: Accepted in the 3rd International Conference on Foundation and Large Language Models (FLLM2025)
💡 一句话要点
提出检索增强的少样本提示方法,用于代码漏洞检测,优于微调模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码漏洞检测 少样本学习 检索增强提示 大型语言模型 软件安全
📋 核心要点
- 现有少样本提示在代码漏洞检测等复杂领域依赖于高质量的上下文示例,选择不当会严重影响性能。
- 论文提出检索增强提示方法,通过检索语义相似的示例来改善少样本学习效果,提升漏洞检测准确率。
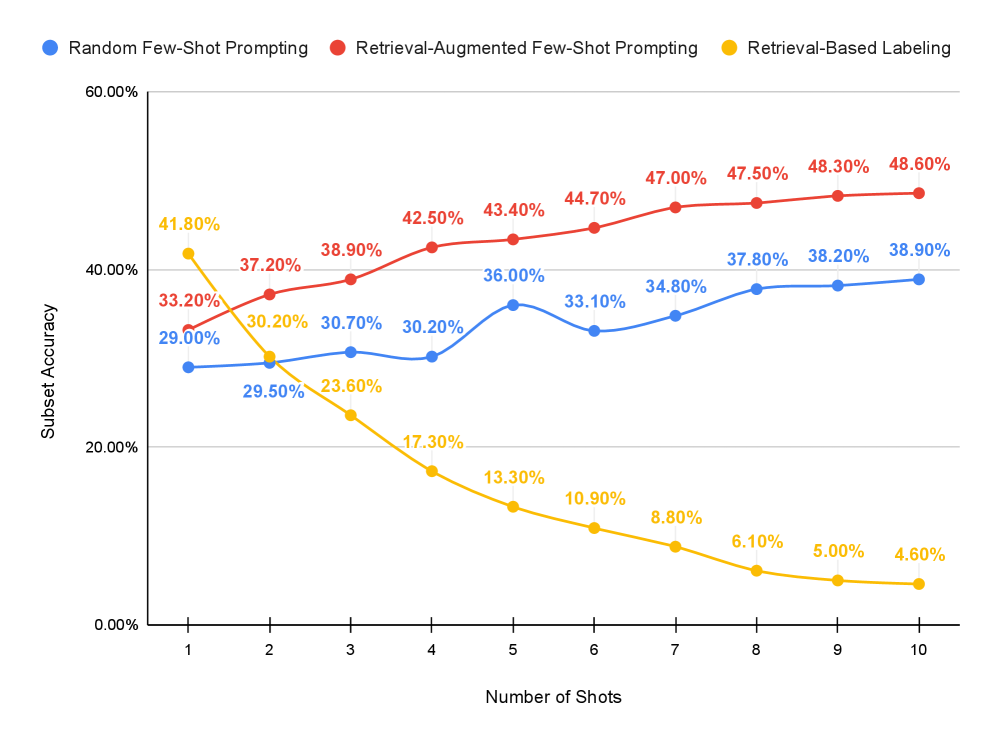
- 实验表明,检索增强提示优于标准少样本提示、零样本提示和微调的Gemini模型,在F1和准确率上均有提升。
📝 摘要(中文)
本文研究了检索增强提示作为一种策略,以提高大型语言模型(LLMs)在代码漏洞检测中的少样本性能。代码漏洞检测的目标是从预定义的漏洞类别中识别给定代码片段中存在的一个或多个与安全相关的弱点。我们使用Gemini-1.5-Flash模型对三种方法进行了系统评估:(1)使用随机选择的示例的标准少样本提示,(2)使用语义相似示例的检索增强提示,以及(3)基于检索的标记,其基于检索到的示例分配标签而无需模型推理。结果表明,检索增强提示始终优于其他提示策略。在20个示例时,它实现了74.05%的F1分数和83.90%的部分匹配准确率。我们进一步将这种方法与零样本提示和几个微调模型(包括Gemini-1.5-Flash和较小的开源模型,如DistilBERT、DistilGPT2和CodeBERT)进行了比较。检索增强提示优于零样本(F1分数:36.35%,部分匹配准确率:20.30%)和微调的Gemini(F1分数:59.31%,部分匹配准确率:53.10%),同时避免了与模型微调相关的训练时间和成本。另一方面,微调CodeBERT产生了更高的性能(F1分数:91.22%,部分匹配准确率:91.30%),但需要额外的训练、维护工作和资源。
🔬 方法详解
问题定义:代码漏洞检测旨在识别代码片段中存在的安全漏洞类型。现有方法,如标准少样本提示,依赖于人工选择的示例,质量难以保证,且可能无法覆盖所有漏洞类型。微调虽然有效,但需要大量的训练数据和计算资源,成本较高。
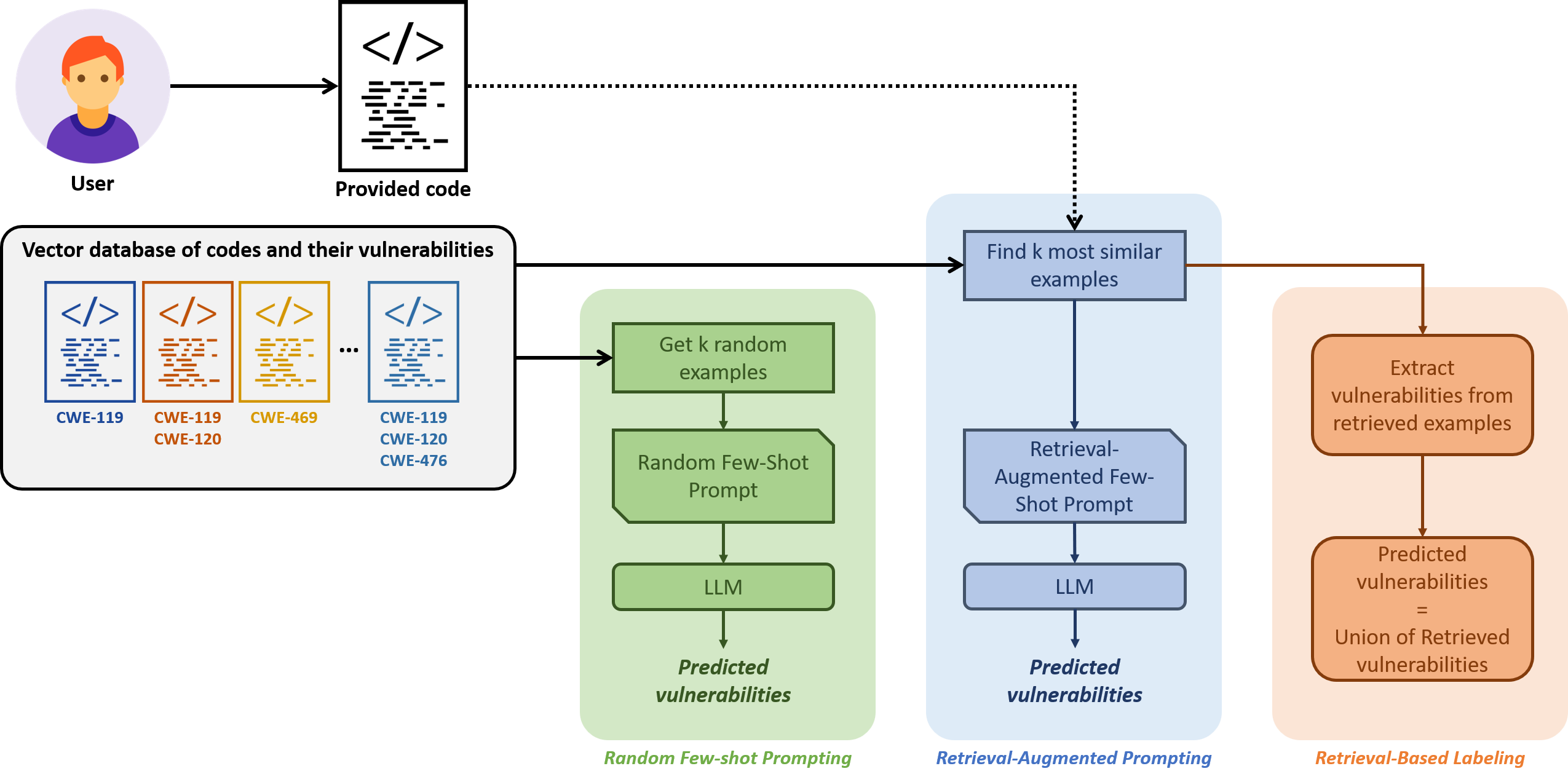
核心思路:论文的核心思路是利用检索增强提示,通过检索与待检测代码片段语义相似的示例,作为上下文信息提供给大型语言模型。这样可以避免人工选择示例的偏差,并利用模型的泛化能力,提高漏洞检测的准确率。
技术框架:整体流程包括:1)代码片段嵌入:将代码片段转换为向量表示;2)相似性检索:使用向量相似度度量,从代码库中检索与待检测代码片段最相似的示例;3)提示构建:将检索到的示例作为上下文,构建提示输入给大型语言模型;4)漏洞预测:大型语言模型根据提示,预测代码片段中存在的漏洞类型。
关键创新:关键创新在于将检索增强与少样本提示相结合,利用检索到的语义相似示例来提升少样本学习的效果。与传统的少样本提示相比,该方法能够自动选择更具代表性的示例,提高模型的泛化能力。与微调相比,该方法无需训练,节省了计算资源和时间。
关键设计:论文使用了Gemini-1.5-Flash模型作为大型语言模型,并采用向量数据库存储代码片段的嵌入向量。相似性度量使用了余弦相似度。在提示构建方面,采用了标准的少样本提示格式,将检索到的示例和待检测代码片段拼接在一起作为输入。
🖼️ 关键图片

📊 实验亮点
实验结果表明,检索增强提示在20个示例时,F1分数达到74.05%,部分匹配准确率达到83.90%,显著优于零样本提示(F1: 36.35%, 准确率: 20.30%)和微调的Gemini-1.5-Flash模型(F1: 59.31%, 准确率: 53.10%)。虽然微调CodeBERT能达到更高的性能(F1: 91.22%, 准确率: 91.30%),但需要额外的训练成本。
🎯 应用场景
该研究成果可应用于软件安全开发生命周期(SSDLC)的各个阶段,例如代码审查、静态代码分析和漏洞扫描。通过自动识别代码中的潜在漏洞,可以帮助开发人员及时修复安全缺陷,提高软件的整体安全性。此外,该方法还可以用于构建自动化的漏洞报告系统,减轻安全工程师的工作负担。
📄 摘要(原文)
Few-shot prompting has emerged as a practical alternative to fine-tuning for leveraging the capabilities of large language models (LLMs) in specialized tasks. However, its effectiveness depends heavily on the selection and quality of in-context examples, particularly in complex domains. In this work, we examine retrieval-augmented prompting as a strategy to improve few-shot performance in code vulnerability detection, where the goal is to identify one or more security-relevant weaknesses present in a given code snippet from a predefined set of vulnerability categories. We perform a systematic evaluation using the Gemini-1.5-Flash model across three approaches: (1) standard few-shot prompting with randomly selected examples, (2) retrieval-augmented prompting using semantically similar examples, and (3) retrieval-based labeling, which assigns labels based on retrieved examples without model inference. Our results show that retrieval-augmented prompting consistently outperforms the other prompting strategies. At 20 shots, it achieves an F1 score of 74.05% and a partial match accuracy of 83.90%. We further compare this approach against zero-shot prompting and several fine-tuned models, including Gemini-1.5-Flash and smaller open-source models such as DistilBERT, DistilGPT2, and CodeBERT. Retrieval-augmented prompting outperforms both zero-shot (F1 score: 36.35%, partial match accuracy: 20.30%) and fine-tuned Gemini (F1 score: 59.31%, partial match accuracy: 53.10%), while avoiding the training time and cost associated with model fine-tuning. On the other hand, fine-tuning CodeBERT yields higher performance (F1 score: 91.22%, partial match accuracy: 91.30%) but requires additional training, maintenance effort, and resources.