Asm2SrcEval: Evaluating Large Language Models for Assembly-to-Source Code Translation
作者: Parisa Hamedi, Hamed Jelodar, Samita Bai, Mohammad Meymani, Roozbeh Razavi-Far, Ali A. Ghorbani
分类: cs.SE, cs.AI
发布日期: 2025-11-28
💡 一句话要点
Asm2SrcEval:首个大规模汇编到源代码翻译的LLM评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 汇编代码翻译 大型语言模型 评测基准 逆向工程 程序分析 网络安全 软件维护
📋 核心要点
- 现有汇编到源代码翻译缺乏系统性评测基准,难以有效评估LLM的性能。
- 提出Asm2SrcEval基准,通过多样化指标全面评估LLM在汇编到源代码翻译中的表现。
- 实验揭示了不同LLM在准确性、流畅度和效率之间的权衡,并分析了典型成功与失败案例。
📝 摘要(中文)
汇编到源代码的翻译是逆向工程、网络安全和软件维护中的一项关键任务,但目前缺乏系统性的基准来评估大型语言模型(LLM)在此问题上的表现。本文首次对五个最先进的LLM在汇编到源代码翻译任务上进行了全面评估。我们使用一套多样化的指标来评估模型性能,包括词汇相似性(BLEU、ROUGE和METEOR)、语义对齐(BERTScore)、流畅度(Perplexity)和效率(时间预测)。结果表明,模型之间存在明显的权衡:某些模型在文本相似性指标上表现出色,而另一些模型则表现出较低的困惑度或更快的推理时间。我们还对典型的模型成功和失败案例进行了定性分析,突出了控制流恢复和标识符重建等挑战。总而言之,我们的基准为当前LLM在程序翻译方面的优势和局限性提供了可操作的见解,为未来在实际应用中结合准确性和效率的研究奠定了基础。
🔬 方法详解
问题定义:论文旨在解决汇编代码到源代码的自动翻译问题,并针对现有缺乏系统性评测基准的现状。现有方法难以有效评估大型语言模型在此任务上的性能,阻碍了相关研究的进展。
核心思路:论文的核心思路是构建一个全面的评测基准,通过多样化的指标来评估LLM在汇编到源代码翻译任务中的表现,从而揭示不同模型的优势和局限性,并为未来的研究提供指导。
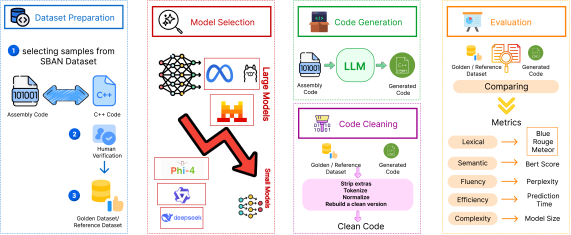
技术框架:论文构建了Asm2SrcEval评测基准,主要包含以下几个阶段:1) 选择五个最先进的LLM进行评估;2) 使用多样化的指标评估模型性能,包括词汇相似性(BLEU、ROUGE和METEOR)、语义对齐(BERTScore)、流畅度(Perplexity)和效率(时间预测);3) 对模型的成功和失败案例进行定性分析,识别关键挑战。
关键创新:该论文最重要的创新点在于构建了首个大规模汇编到源代码翻译的LLM评测基准Asm2SrcEval。与现有方法相比,该基准更加全面和系统化,能够更有效地评估LLM在此任务上的性能。
关键设计:论文的关键设计包括:1) 选择具有代表性的LLM进行评估;2) 使用多样化的指标来全面评估模型性能,不仅考虑了词汇相似性,还考虑了语义对齐、流畅度和效率;3) 通过定性分析来深入了解模型的优势和局限性。
🖼️ 关键图片

📊 实验亮点
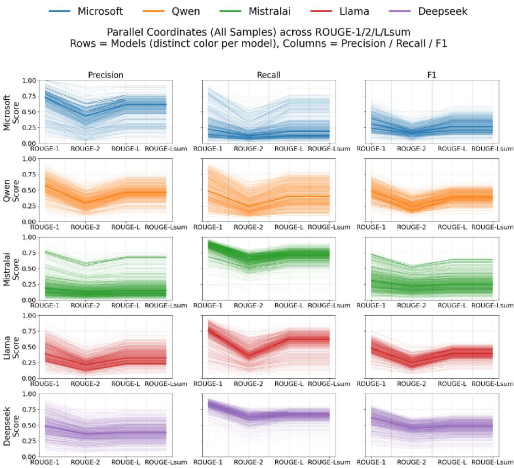
实验结果表明,不同LLM在汇编到源代码翻译任务中表现出不同的优势和局限性。例如,某些模型在BLEU等文本相似性指标上表现出色,而另一些模型则具有较低的困惑度或更快的推理速度。该研究还揭示了控制流恢复和标识符重建是该任务中的关键挑战。
🎯 应用场景
该研究成果可应用于逆向工程、网络安全、软件维护等领域。通过自动将汇编代码翻译成源代码,可以提高软件分析和理解的效率,加速漏洞挖掘和修复,并降低软件维护成本。未来,该研究可以促进开发更准确、更高效的程序翻译工具,从而推动相关领域的发展。
📄 摘要(原文)
Assembly-to-source code translation is a critical task in reverse engineering, cybersecurity, and software maintenance, yet systematic benchmarks for evaluating large language models on this problem remain scarce. In this work, we present the first comprehensive evaluation of five state-of-the-art large language models on assembly-to-source translation. We assess model performance using a diverse set of metrics capturing lexical similarity (BLEU, ROUGE, and METEOR), semantic alignment (BERTScore), fluency (Perplexity), and efficiency (time prediction). Our results reveal clear trade-offs: while certain models excel in text similarity metrics, others demonstrate lower perplexity or faster inference times. We further provide qualitative analyses of typical model successes and failure cases, highlighting challenges such as control flow recovery and identifier reconstruction. Taken together, our benchmark offers actionable insights into the strengths and limitations of current large language models for program translation, establishing a foundation for future research in combining accuracy with efficiency for real-world applications.