Thinking by Doing: Building Efficient World Model Reasoning in LLMs via Multi-turn Interaction
作者: Bao Shu, Yan Cai, Jianjian Sun, Chunrui Han, En Yu, Liang Zhao, Jingcheng Hu, Yinmin Zhang, Haoran Lv, Yuang Peng, Zheng Ge, Xiangyu Zhang, Daxin Jiang, Xiangyu Yue
分类: cs.AI
发布日期: 2025-11-28
备注: 17 pages, 9 figures
💡 一句话要点
提出WMAct,通过高效交互提升LLM在复杂环境中的世界模型推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 大型语言模型 强化学习 智能体 交互式学习 主动推理 奖励重塑 环境建模
📋 核心要点
- 现有方法在LLM智能体进行世界模型推理时,推理过程僵化,限制了模型的主动学习能力,导致效率低下。
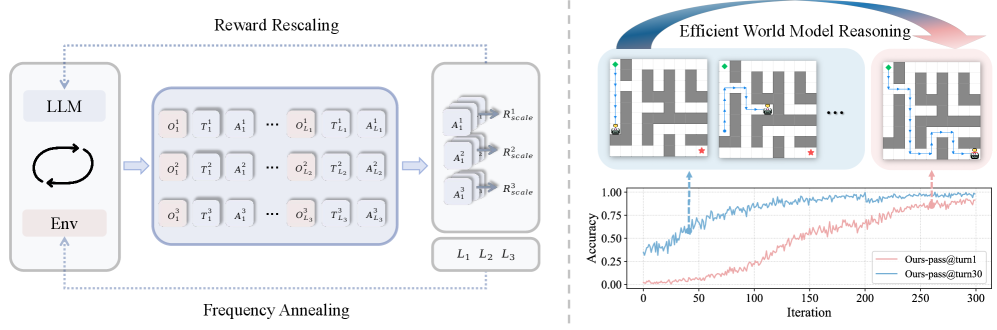
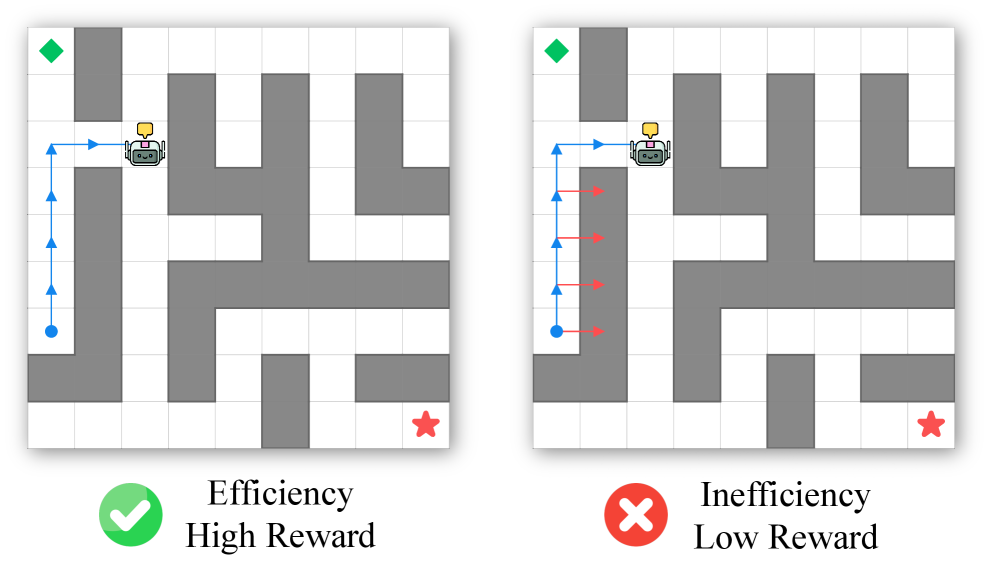
- WMAct通过奖励重缩放和交互频率退火两种机制,鼓励模型通过实践塑造思维,实现高效的世界模型内化。
- 实验表明,WMAct能使模型在单轮交互中解决复杂任务,并提升模型在复杂环境中的迁移能力和推理性能。
📝 摘要(中文)
本文旨在提升大型语言模型(LLM)智能体在复杂环境中规划和交互的世界模型推理能力。尽管多轮交互能通过真实反馈提供对环境动态的深入理解,但现有方法通常采用僵化的推理过程,限制了模型的积极学习,阻碍了高效的世界模型推理。为了解决这些问题,本文探索了通过高效交互和主动推理(WMAct)实现世界模型内化的方法。WMAct使模型能够通过实践直接塑造思维,并通过两种关键机制实现有效且高效的世界模型推理:(1)基于行动效能调整结果奖励的奖励重缩放机制,以激励冗余减少和有目的的交互;(2)逐步减少最大允许交互轮数的交互频率退火策略,迫使模型压缩学习并内化环境动态,而不是过度依赖环境线索。在Sokoban、Maze和Taxi上的实验表明,WMAct产生了有效世界模型推理,能够以单轮解决以前需要多次交互的任务,并促进了对复杂环境的强大可迁移性,提高了在一系列推理基准上的性能。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)智能体在复杂环境中进行规划和交互时,需要强大的世界模型推理能力。然而,现有方法通常采用固定的推理流程,限制了模型通过与环境的真实交互进行主动学习,从而导致世界模型推理效率低下。这些方法过度依赖预定义的步骤,无法充分利用多轮交互提供的环境反馈。
核心思路:本文的核心思路是通过高效的交互和主动推理(WMAct)来内化世界模型。WMAct的核心在于让模型通过“做”来“思考”,即通过与环境的交互来直接塑造其推理过程,而不是依赖预设的推理结构。通过激励模型进行有目的的交互并减少冗余,以及迫使模型压缩学习,WMAct旨在提高世界模型推理的效率和有效性。
技术框架:WMAct主要包含两个关键机制:奖励重缩放机制和交互频率退火策略。奖励重缩放机制根据行动的有效性调整结果奖励,鼓励模型减少冗余行动,进行更有目的的交互。交互频率退火策略逐步减少允许的最大交互轮数,迫使模型更快地学习并内化环境动态,而不是过度依赖环境提示。整体流程是,模型在环境中执行动作,环境给出反馈,WMAct根据反馈调整奖励和交互频率,引导模型学习更有效的策略。
关键创新:WMAct的关键创新在于它打破了传统LLM智能体推理过程的僵化结构,允许模型通过与环境的直接交互来塑造其推理过程。与现有方法相比,WMAct更加注重模型的自主学习和环境适应能力,而不是依赖预定义的推理步骤。这种“做中学”的模式使得模型能够更有效地内化世界模型,并提高推理效率。
关键设计:奖励重缩放机制的具体实现方式是,如果一个动作对达成目标没有贡献,则降低该动作的奖励。交互频率退火策略的具体实现方式是,随着训练的进行,逐步降低允许的最大交互轮数。具体的退火策略可以是线性退火或指数退火。论文中还可能包含一些超参数的设置,例如奖励重缩放的比例因子和交互频率退火的速率,这些参数需要根据具体的环境进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,WMAct在Sokoban、Maze和Taxi等任务上取得了显著的性能提升。WMAct能够使模型在单轮交互中解决以前需要多次交互才能完成的任务,并且在复杂环境中表现出更强的迁移能力。例如,在某些任务上,WMAct的性能超过了现有基线方法,并且能够更快地收敛到最优策略。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、自动驾驶等领域,提升智能体在复杂、动态环境中的决策能力。通过高效的世界模型推理,智能体能够更好地理解环境,制定更有效的行动计划,从而实现更智能、更自主的行为。未来,该方法有望扩展到更广泛的领域,例如智能制造、智能医疗等。
📄 摘要(原文)
Developing robust world model reasoning is crucial for large language model (LLM) agents to plan and interact in complex environments. While multi-turn interaction offers a superior understanding of environmental dynamics via authentic feedback, current approaches often impose a rigid reasoning process, which constrains the model's active learning, ultimately hindering efficient world model reasoning. To address these issues, we explore world-model internalization through efficient interaction and active reasoning (WMAct), which liberates the model from structured reasoning, allowing the model to shape thinking directly through its doing, and achieves effective and efficient world model reasoning with two key mechanisms: (1) a reward rescaling mechanism adjusting outcome reward based on action efficacy to incentivize redundancy reduction and purposeful interaction; (2) an interaction frequency annealing strategy to progressively reduce the maximum allowed interaction turns, which compels the model to condense its learning and internalize environmental dynamics rather than over-relying on environmental cues. Our experiments on Sokoban, Maze, and Taxi show that WMAct yields effective world model reasoning capable of resolving tasks in a single turn that previously required multiple interactions and fosters strong transferability to complex environments, improving performance on a suite of reasoning benchmarks.