Evaluating LLMs for One-Shot Patching of Real and Artificial Vulnerabilities
作者: Aayush Garg, Zanis Ali Khan, Renzo Degiovanni, Qiang Tang
分类: cs.CR, cs.AI, cs.SE
发布日期: 2025-11-28
备注: Pre-print - Extended version of the poster paper accepted at the 41st ACM/SIGAPP Symposium on Applied Computing (SAC) Smarter Engineering-Building AI and Building with AI (SEAI) 2026
💡 一句话要点
评估大型语言模型在真实和人工漏洞的单样本补丁修复能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 漏洞修复 软件安全 真实漏洞 人工漏洞 漏洞验证 代码补丁
📋 核心要点
- 现有研究主要使用公开漏洞评估LLM的补丁修复能力,缺乏对人工漏洞的有效性评估。
- 该研究通过漏洞验证(PoV)测试,评估LLM生成的代码是否成功修复真实和人工漏洞。
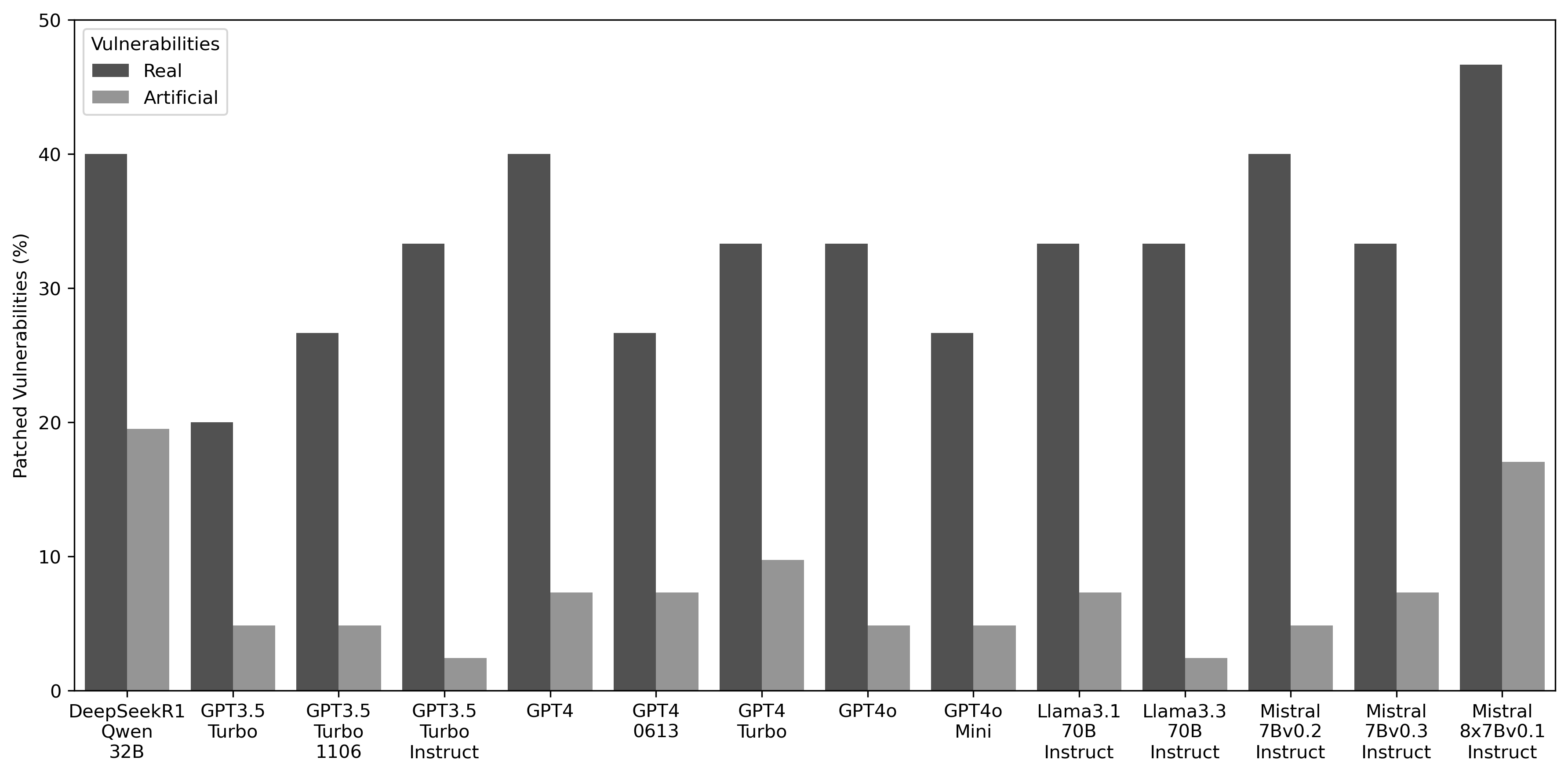
- 实验结果表明,LLM在修复真实漏洞方面优于人工漏洞,且不同LLM在漏洞修复上具有互补性。
📝 摘要(中文)
自动漏洞补丁修复对于软件安全至关重要,而大型语言模型(LLMs)的最新进展为自动化此任务提供了有希望的能力。然而,现有研究主要使用公开披露的漏洞评估LLMs,在很大程度上未探索它们在相关人工漏洞上的有效性。本研究实证评估了包括OpenAI的GPT变体、LLaMA、DeepSeek和Mistral模型等几种著名LLMs在真实和人工漏洞上的补丁修复效果和互补性。我们的评估采用漏洞验证(PoV)测试执行来具体评估LLM生成的源代码是否成功修复了漏洞。结果表明,LLMs在修复真实漏洞方面比人工漏洞更有效。此外,我们的分析揭示了LLMs在重叠(多个LLMs修复相同的漏洞)和互补性(仅由单个LLM修复的漏洞)方面存在显著差异,强调了选择合适的LLMs以实现有效的漏洞修复的重要性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在自动修复软件漏洞方面的能力,特别是区分其在真实漏洞和人工构造漏洞上的表现差异。现有方法主要集中于使用公开披露的漏洞进行评估,忽略了LLMs在处理新型或人工漏洞时的泛化能力,这限制了对LLMs实际应用价值的全面理解。
核心思路:核心思路是通过构建一个包含真实漏洞和人工漏洞的综合数据集,并利用漏洞验证(Proof-of-Vulnerability, PoV)测试来评估不同LLMs生成的补丁代码的有效性。通过比较LLMs在两种类型漏洞上的表现,可以更深入地了解它们的优势和局限性,从而指导LLMs在漏洞修复领域的应用。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 收集真实漏洞数据;2) 构建人工漏洞数据集;3) 选择多种具有代表性的LLMs(如GPT系列、LLaMA、DeepSeek、Mistral等);4) 使用LLMs为每个漏洞生成补丁代码;5) 利用PoV测试执行来验证补丁代码是否成功修复漏洞;6) 分析实验结果,比较不同LLMs在真实和人工漏洞上的表现,并评估它们的互补性。
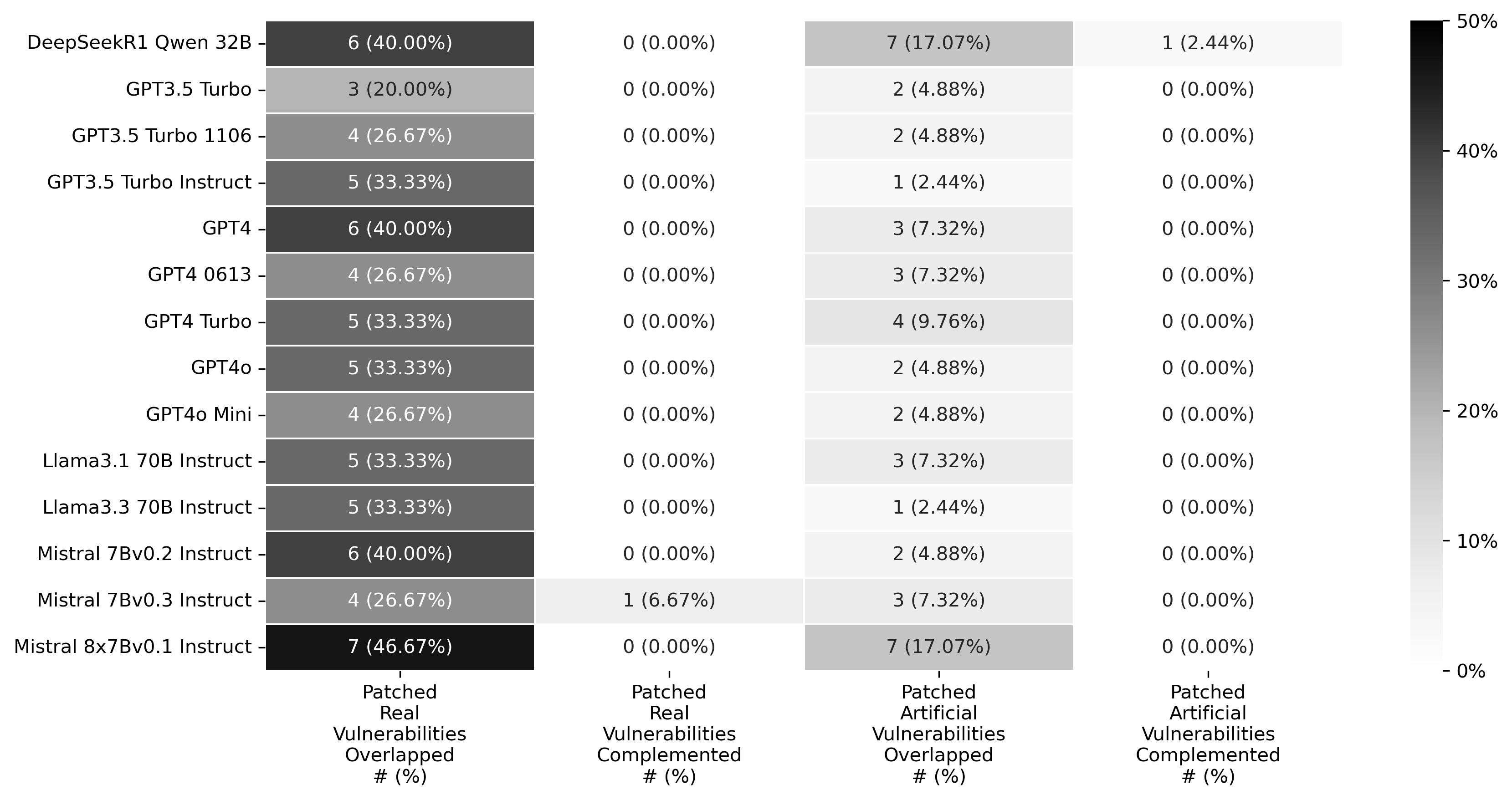
关键创新:该研究的关键创新在于同时评估LLMs在真实漏洞和人工漏洞上的修复能力,并采用PoV测试执行进行严格验证。这种综合评估方法能够更全面地揭示LLMs在漏洞修复领域的潜力和挑战,为未来的研究提供更可靠的依据。此外,研究还分析了不同LLMs在漏洞修复上的互补性,为选择合适的LLMs组合以提高漏洞修复效果提供了指导。
关键设计:研究的关键设计包括:1) 精心设计的人工漏洞,以模拟真实漏洞的各种特征;2) 采用PoV测试执行,确保对补丁代码的有效性进行客观评估;3) 选择多种具有代表性的LLMs,以评估不同模型的性能差异;4) 详细分析实验结果,包括修复成功率、重叠率和互补性等指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLMs在修复真实漏洞方面比人工漏洞更有效。此外,不同LLMs在漏洞修复上表现出显著的互补性,意味着可以通过组合使用不同的LLMs来提高整体的漏洞修复效果。研究还量化了不同LLMs在修复相同漏洞上的重叠率,以及仅由单个LLM修复的漏洞比例,为实际应用中选择合适的LLMs提供了数据支持。
🎯 应用场景
该研究成果可应用于自动化软件安全领域,帮助开发者快速修复漏洞,提高软件系统的安全性。通过选择合适的LLMs或LLMs组合,可以更有效地修复各种类型的漏洞,降低安全风险。此外,该研究还可以促进LLMs在安全领域的进一步发展,例如,用于漏洞挖掘、恶意代码检测等。
📄 摘要(原文)
Automated vulnerability patching is crucial for software security, and recent advancements in Large Language Models (LLMs) present promising capabilities for automating this task. However, existing research has primarily assessed LLMs using publicly disclosed vulnerabilities, leaving their effectiveness on related artificial vulnerabilities largely unexplored. In this study, we empirically evaluate the patching effectiveness and complementarity of several prominent LLMs, such as OpenAI's GPT variants, LLaMA, DeepSeek, and Mistral models, using both real and artificial vulnerabilities. Our evaluation employs Proof-of-Vulnerability (PoV) test execution to concretely assess whether LLM-generated source code successfully patches vulnerabilities. Our results reveal that LLMs patch real vulnerabilities more effectively compared to artificial ones. Additionally, our analysis reveals significant variability across LLMs in terms of overlapping (multiple LLMs patching the same vulnerabilities) and complementarity (vulnerabilities patched exclusively by a single LLM), emphasizing the importance of selecting appropriate LLMs for effective vulnerability patching.