AgriCoT: A Chain-of-Thought Benchmark for Evaluating Reasoning in Vision-Language Models for Agriculture
作者: Yibin Wen, Qingmei Li, Zi Ye, Jiarui Zhang, Jing Wu, Zurong Mai, Shuohong Lou, Yuhang Chen, Henglian Huang, Xiaoya Fan, Yang Zhang, Lingyuan Zhao, Haohuan Fu, Huang Jianxi, Juepeng Zheng
分类: cs.AI
发布日期: 2025-11-28
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出AgriCoT:农业领域视觉-语言模型推理能力评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 农业 推理能力 思维链 视觉问答 数据集 基准测试
📋 核心要点
- 现有VQA数据集难以充分评估视觉-语言模型在复杂农业场景下的推理和问题解决能力。
- AgriCoT数据集通过引入思维链(CoT)推理,专门评估VLM在农业领域的推理能力,侧重逻辑推理和问题解决。
- 实验结果表明,现有VLM在农业推理方面存在显著差距,强调了CoT在评估中的重要性。
📝 摘要(中文)
视觉-语言模型(VLM)的最新进展显著改变了各个行业。在农业领域,这些双模态能力为精准农业、作物监测、病虫害检测和环境可持续性提供了有前景的应用。虽然已经开发了多个视觉问答(VQA)数据集和基准来评估VLM性能,但它们通常无法充分评估复杂农业环境中所需的关键推理和问题解决能力。为了解决这一差距,我们引入了AgriCoT,这是一个结合了思维链(CoT)推理的VQA数据集,专门用于评估VLM的推理能力。AgriCoT包含4,535个精心策划的样本,通过关注VLM进行逻辑推理和有效问题解决的能力,为VLM的推理能力提供全面而稳健的评估,尤其是在零样本场景中。我们使用26个具有代表性的VLM(包括专有模型和开源模型)进行的评估表明,虽然一些专有模型擅长回答问题,但它们的推理能力存在显著差距。这突显了结合CoT进行更精确和有效评估的重要性。我们的数据集可在https://huggingface.co/datasets/wenyb/AgriCoT获取。
🔬 方法详解
问题定义:论文旨在解决现有视觉问答(VQA)数据集在评估视觉-语言模型(VLM)在农业领域推理能力方面的不足。现有数据集无法充分评估VLM在复杂农业场景下的逻辑推理和问题解决能力,限制了VLM在农业领域的应用。
核心思路:论文的核心思路是构建一个包含思维链(Chain-of-Thought, CoT)推理的VQA数据集AgriCoT,该数据集专门设计用于评估VLM在农业领域的推理能力。通过引入CoT,AgriCoT能够更精确地评估VLM进行逻辑推理和有效问题解决的能力,尤其是在零样本场景下。这样设计的目的是为了弥补现有数据集的不足,并为VLM在农业领域的应用提供更可靠的评估基准。
技术框架:AgriCoT数据集的构建流程主要包括以下几个阶段:首先,收集与农业相关的图像和问题。然后,为每个问题设计思维链推理过程,即CoT。最后,将图像、问题和CoT推理过程组合成一个样本,构成AgriCoT数据集。该数据集包含4,535个精心策划的样本,涵盖了农业领域的各种场景和问题。
关键创新:论文的关键创新在于构建了一个专门针对农业领域的、包含思维链推理的VQA数据集AgriCoT。与现有VQA数据集相比,AgriCoT更加关注VLM在农业领域的推理能力,并引入了CoT推理过程,从而能够更精确地评估VLM的逻辑推理和问题解决能力。这是现有方法所不具备的。
关键设计:AgriCoT数据集的关键设计包括:1) 样本的多样性,涵盖了农业领域的各种场景和问题;2) CoT推理过程的质量,确保CoT推理过程的逻辑性和正确性;3) 数据集的规模,包含4,535个样本,能够为VLM的评估提供充分的数据支持。论文未提及具体的参数设置、损失函数或网络结构等技术细节,可能因为数据集本身是作为评估工具,而非一种新的模型或算法。
🖼️ 关键图片

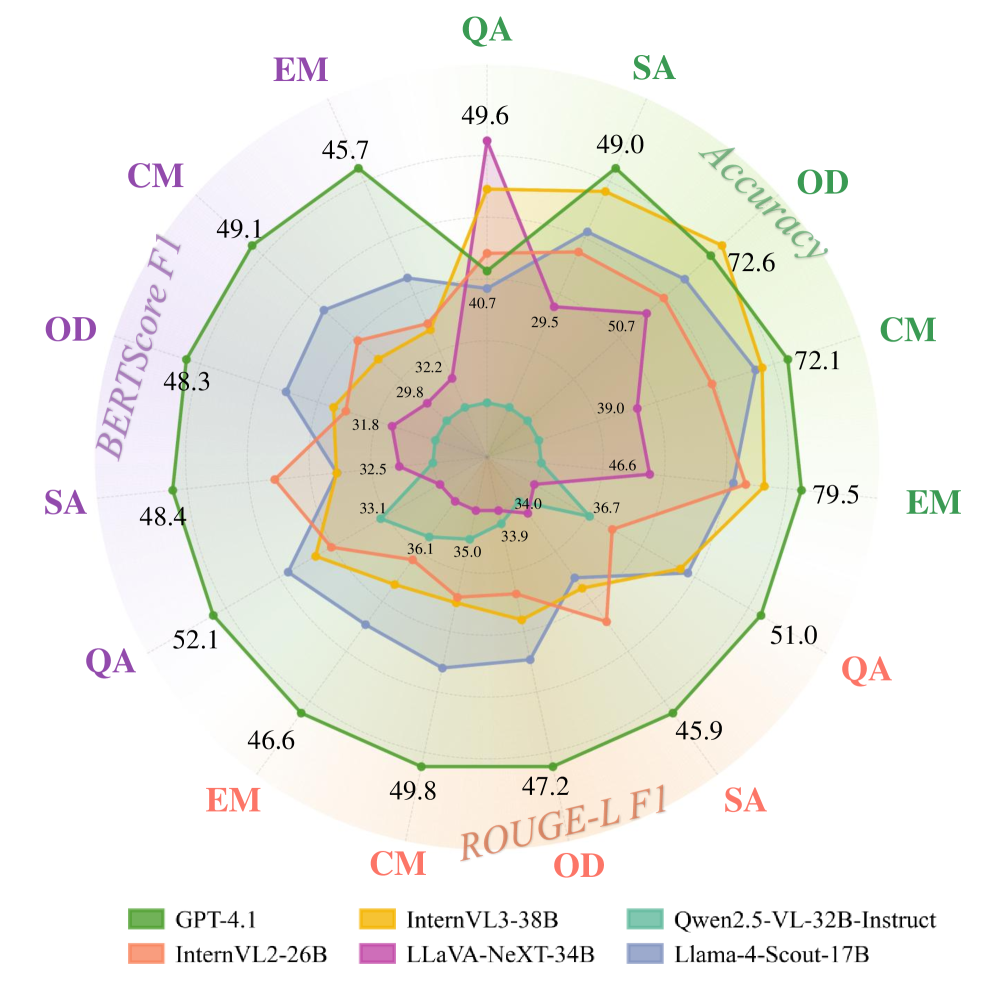

📊 实验亮点
使用AgriCoT数据集对26个具有代表性的VLM(包括专有模型和开源模型)进行评估,结果表明,虽然一些专有模型擅长回答问题,但它们的推理能力存在显著差距。这突显了结合CoT进行更精确和有效评估的重要性,并为未来VLM在农业领域的应用指明了方向。
🎯 应用场景
AgriCoT数据集可用于评估和提升视觉-语言模型在农业领域的应用,例如精准农业、作物监测、病虫害检测和环境可持续性。通过更准确地评估模型的推理能力,可以促进开发更可靠、更有效的农业智能系统,提高农业生产效率和可持续性。
📄 摘要(原文)
Recent advancements in Vision-Language Models (VLMs) have significantly transformed various industries. In agriculture, these dual-modal capabilities offer promising applications such as precision farming, crop monitoring, pest detection, and environmental sustainability. While several Visual Question Answering (VQA) datasets and benchmarks have been developed to evaluate VLM performance, they often fail to adequately assess the critical reasoning and problem-solving skills required in complex agricultural contexts. To address this gap, we introduce AgriCoT, a VQA dataset that incorporates Chain-of-Thought (CoT) reasoning, specifically designed to evaluate the reasoning capabilities of VLMs. With 4,535 carefully curated samples, AgriCoT offers a comprehensive and robust evaluation of reasoning abilities for VLMs, particularly in zero-shot scenarios, by focusing on their capacity to engage in logical reasoning and effective problem-solving. Our evaluations, conducted with 26 representative VLMs, including both proprietary and open-source models, reveal that while some proprietary models excel at answering questions, there is a notable and significant gap in their reasoning capabilities. This underscores the importance of incorporating CoT for more precise and effective assessments. Our dataset are available at https://huggingface.co/datasets/wenyb/AgriCoT.