Evolutionary Discovery of Heuristic Policies for Traffic Signal Control
作者: Ruibing Wang, Shuhan Guo, Zeen Li, Zhen Wang, Quanming Yao
分类: cs.AI
发布日期: 2025-11-28
💡 一句话要点
提出Temporal Policy Evolution for Traffic (TPET),利用LLM进化交通信号控制策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 交通信号控制 大型语言模型 启发式策略 进化算法 状态抽象
📋 核心要点
- 现有交通信号控制方法,如经典启发式算法过于简化,深度强化学习泛化性差,在线LLM延迟高且缺乏环境优化。
- 论文提出TPET框架,利用LLM作为进化引擎,通过结构化状态抽象和信用分配反馈,生成专门的启发式策略。
- TPET在提示级别运行,无需训练,即可生成轻量级、鲁棒的策略,在特定交通环境中优于现有启发式算法和在线LLM。
📝 摘要(中文)
交通信号控制(TSC)面临着一个具有挑战性的权衡:经典启发式算法高效但过于简化,而深度强化学习(DRL)实现了高性能,但泛化能力差且策略不透明。在线大型语言模型(LLM)提供了一般的推理能力,但延迟高且缺乏特定环境的优化。为了解决这些问题,我们提出了交通时序策略进化(TPET),它使用LLM作为进化引擎来推导专门的启发式策略。该框架引入了两个关键模块:(1)结构化状态抽象(SSA),将高维交通数据转换为用于推理的时序逻辑事实;(2)信用分配反馈(CAF),追踪有缺陷的微观决策到不良的宏观结果,以便进行有针对性的批判。TPET完全在提示级别上运行,无需训练,即可产生针对特定交通环境优化的轻量级、鲁棒的策略,优于启发式算法和在线LLM执行器。
🔬 方法详解
问题定义:论文旨在解决交通信号控制(TSC)中现有方法的不足。经典启发式算法虽然高效,但过于简化,无法适应复杂的交通状况。深度强化学习(DRL)虽然性能较高,但泛化能力差,且策略不透明,难以解释和调试。在线大型语言模型(LLM)虽然具备通用推理能力,但延迟较高,且缺乏针对特定交通环境的优化,难以直接应用于实时控制。
核心思路:论文的核心思路是利用LLM作为进化引擎,自动生成针对特定交通环境优化的启发式策略。通过将高维交通数据抽象为结构化的时序逻辑事实,并结合信用分配反馈机制,引导LLM生成更有效的控制策略。这种方法旨在结合LLM的推理能力和启发式算法的效率,同时避免DRL的泛化性问题和在线LLM的延迟问题。
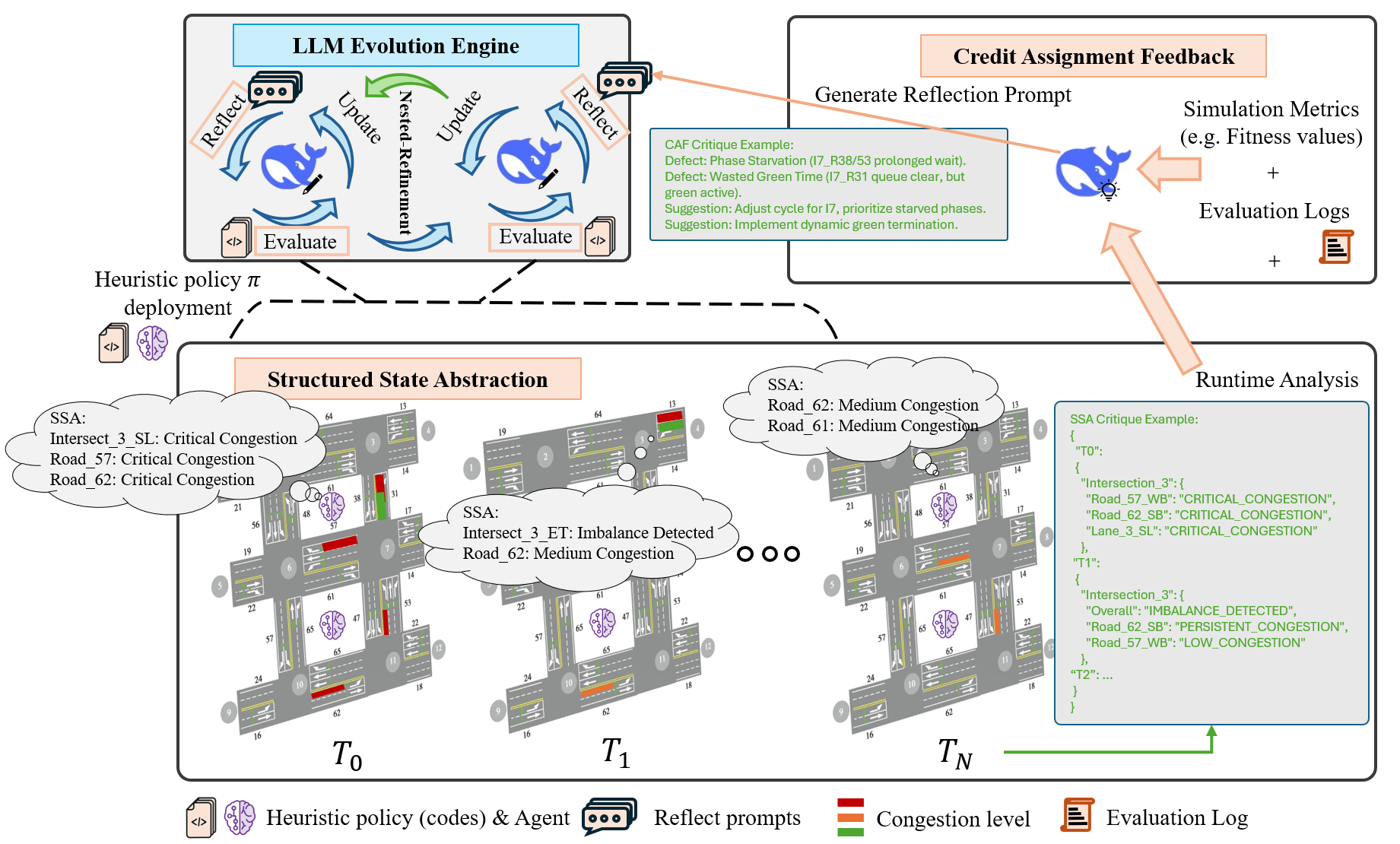
技术框架:TPET框架包含两个主要模块:结构化状态抽象(SSA)和信用分配反馈(CAF)。首先,SSA模块将高维的交通数据转换为时序逻辑事实,为LLM提供结构化的输入。然后,LLM基于这些事实生成交通信号控制策略。接下来,CAF模块追踪策略执行过程中的微观决策,并将不良的宏观结果反馈给LLM,引导LLM改进策略。整个过程在提示级别上进行,无需训练。
关键创新:TPET的关键创新在于利用LLM作为进化引擎,自动生成针对特定交通环境优化的启发式策略。与传统的启发式算法相比,TPET能够自动适应不同的交通状况。与DRL相比,TPET生成的策略更加透明和可解释。与直接使用在线LLM相比,TPET的延迟更低,且能够针对特定环境进行优化。
关键设计:SSA模块的关键设计在于如何将高维交通数据有效地抽象为时序逻辑事实。这需要仔细选择合适的特征,并设计合理的逻辑规则。CAF模块的关键设计在于如何准确地将不良的宏观结果追溯到具体的微观决策。这可能需要使用因果推理或归因分析等技术。论文中未明确提及具体的参数设置、损失函数或网络结构,因为该方法主要在提示级别上运行,不涉及模型的训练。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TPET在特定交通环境中优于传统的启发式算法和在线LLM执行器。具体性能数据未知,但论文强调TPET能够生成轻量级、鲁棒的策略,且无需训练,即可实现优越的性能。
🎯 应用场景
该研究成果可应用于智能交通系统,提升城市交通效率,减少交通拥堵,降低环境污染。通过自动生成针对特定交通环境优化的控制策略,可以降低人工维护成本,提高系统的自适应性。未来,该方法可以扩展到其他智能控制领域,如智能电网、智能制造等。
📄 摘要(原文)
Traffic Signal Control (TSC) involves a challenging trade-off: classic heuristics are efficient but oversimplified, while Deep Reinforcement Learning (DRL) achieves high performance yet suffers from poor generalization and opaque policies. Online Large Language Models (LLMs) provide general reasoning but incur high latency and lack environment-specific optimization. To address these issues, we propose Temporal Policy Evolution for Traffic (\textbf{\method{}}), which uses LLMs as an evolution engine to derive specialized heuristic policies. The framework introduces two key modules: (1) Structured State Abstraction (SSA), converting high-dimensional traffic data into temporal-logical facts for reasoning; and (2) Credit Assignment Feedback (CAF), tracing flawed micro-decisions to poor macro-outcomes for targeted critique. Operating entirely at the prompt level without training, \method{} yields lightweight, robust policies optimized for specific traffic environments, outperforming both heuristics and online LLM actors.