MindPower: Enabling Theory-of-Mind Reasoning in VLM-based Embodied Agents
作者: Ruoxuan Zhang, Qiyun Zheng, Zhiyu Zhou, Ziqi Liao, Siyu Wu, Jian-Yu Jiang-Lin, Bin Wen, Hongxia Xie, Jianlong Fu, Wen-Huang Cheng
分类: cs.AI
发布日期: 2025-11-28
💡 一句话要点
MindPower:赋能VLM具身智能体进行心理理论推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心理理论 具身智能体 视觉语言模型 人机交互 决策 行动生成 机器人中心 多模态推理
📋 核心要点
- 现有具身智能体缺乏基于心理理论(ToM)的决策能力,且评估基准忽略了智能体自身视角。
- MindPower框架通过整合感知、心理推理、决策和行动,使智能体能够进行自我和他人的心理建模。
- MindPower模型在决策和行动生成方面显著优于GPT-4o,证明了其在ToM推理方面的有效性。
📝 摘要(中文)
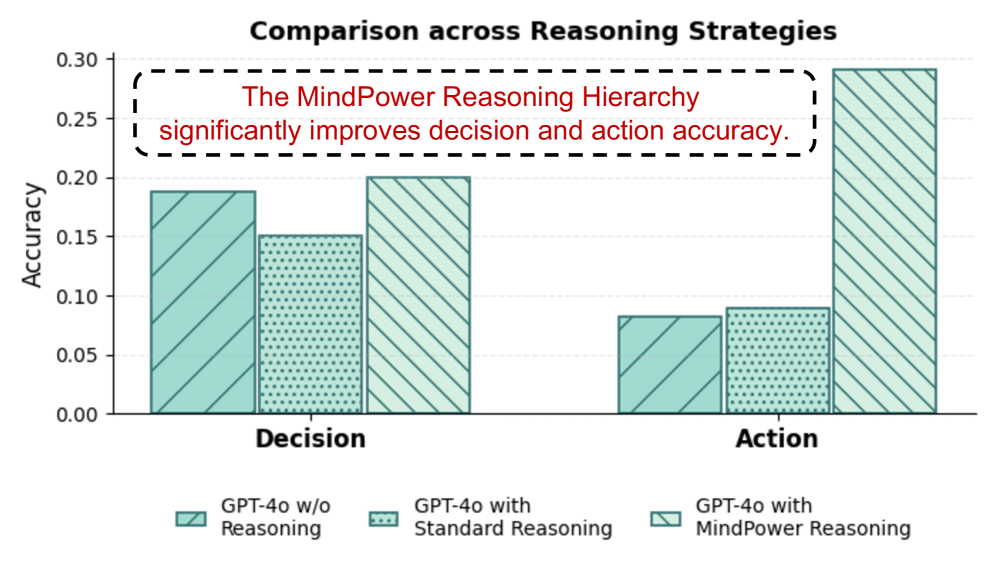
心理理论(ToM)是指推断他人心理状态(如信念、欲望和意图)的能力。当前的视觉-语言具身智能体缺乏基于ToM的决策能力,并且现有基准测试仅关注人类的心理状态,而忽略了智能体自身的视角,从而阻碍了连贯的决策和行动生成。为了解决这个问题,我们提出了MindPower,一个机器人中心的框架,集成了感知、心理推理、决策和行动。给定多模态输入,MindPower首先感知环境和人类状态,然后执行ToM推理来建模自身和他人,最后生成由推断的心理状态指导的决策和行动。此外,我们引入了Mind-Reward,一种新颖的优化目标,鼓励VLM产生一致的ToM推理和行为。我们的模型在决策方面优于GPT-4o 12.77%,在行动生成方面优于GPT-4o 12.49%。
🔬 方法详解
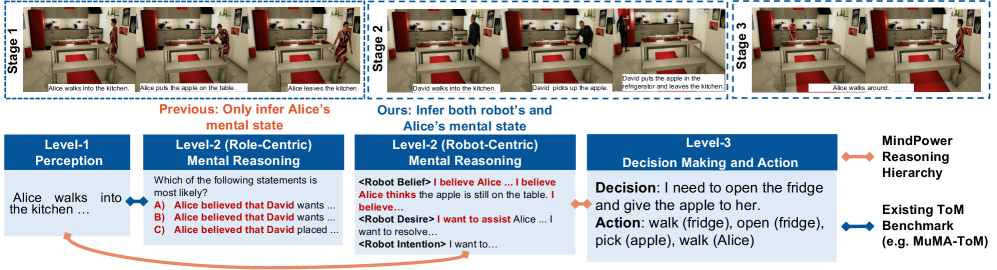
问题定义:现有视觉-语言具身智能体在决策时缺乏对他人心理状态的理解和推理能力,即缺乏心理理论(Theory of Mind, ToM)。现有的benchmark也主要关注人类的心理状态,忽略了agent自身的视角,导致决策和行动生成不连贯。
核心思路:论文的核心思路是构建一个机器人中心的框架,使智能体能够感知环境和人类状态,进行ToM推理以建模自身和他人,并根据推断的心理状态生成决策和行动。通过显式地建模智能体自身和他人的心理状态,提高决策的合理性和连贯性。
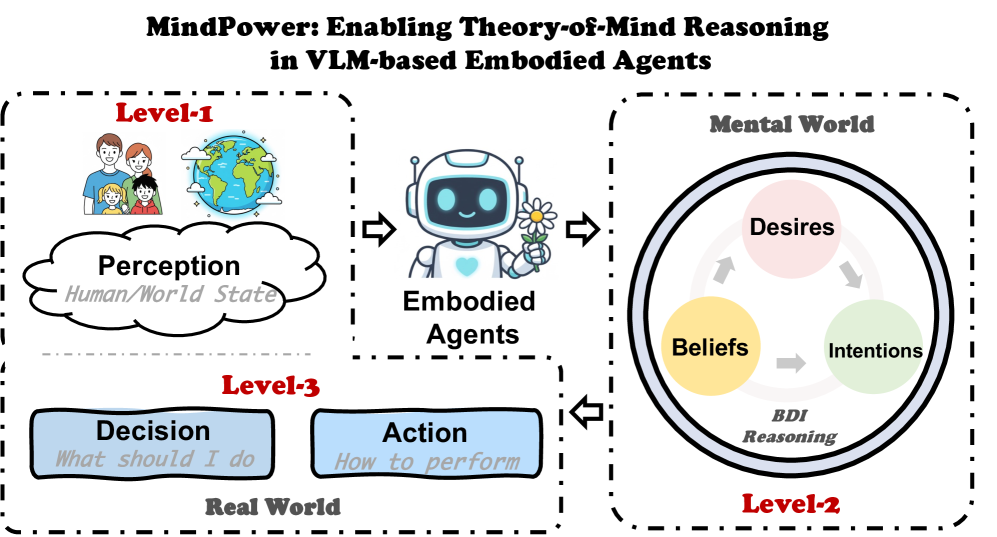
技术框架:MindPower框架包含四个主要模块:感知(Perception)、心理推理(Mental Reasoning)、决策(Decision Making)和行动(Action)。首先,感知模块接收多模态输入(例如,视觉和语言信息),提取环境和人类状态的特征。然后,心理推理模块利用这些特征进行ToM推理,建模智能体自身和他人的信念、欲望和意图。接下来,决策模块基于推理得到的心理状态生成决策。最后,行动模块将决策转化为具体的行动。
关键创新:论文的关键创新在于提出了一个机器人中心的ToM推理框架,并引入了Mind-Reward优化目标。与以往主要关注人类心理状态的方法不同,MindPower显式地建模了智能体自身的心理状态,从而更好地指导决策和行动。Mind-Reward鼓励VLM产生一致的ToM推理和行为,进一步提高了模型的性能。
关键设计:Mind-Reward是一种新颖的优化目标,旨在鼓励VLM产生一致的ToM推理和行为。具体来说,Mind-Reward包括两部分:一是推理一致性奖励,鼓励模型在不同时间步产生一致的心理状态推理结果;二是行为一致性奖励,鼓励模型根据推理得到的心理状态采取合理的行动。论文中VLM的具体选择和参数设置未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MindPower模型在决策方面优于GPT-4o 12.77%,在行动生成方面优于GPT-4o 12.49%。这表明MindPower框架能够有效地提升具身智能体的心理理论推理能力,并显著改善其决策和行动生成性能。Mind-Reward的引入进一步提高了模型的性能,验证了其有效性。
🎯 应用场景
该研究成果可应用于人机协作机器人、智能家居、自动驾驶等领域。通过使智能体具备心理理论能力,可以提升其与人类的交互体验,使其能够更好地理解人类意图并做出合理的决策,从而实现更自然、高效的人机协作。未来,该技术有望应用于更复杂的社会环境中,例如教育、医疗等领域。
📄 摘要(原文)
Theory of Mind (ToM) refers to the ability to infer others' mental states, such as beliefs, desires, and intentions. Current vision-language embodied agents lack ToM-based decision-making, and existing benchmarks focus solely on human mental states while ignoring the agent's own perspective, hindering coherent decision and action generation. To address this, we propose MindPower, a Robot-Centric framework integrating Perception, Mental Reasoning, Decision Making and Action. Given multimodal inputs, MindPower first perceives the environment and human states, then performs ToM Reasoning to model both self and others, and finally generates decisions and actions guided by inferred mental states. Furthermore, we introduce Mind-Reward, a novel optimization objective that encourages VLMs to produce consistent ToM Reasoning and behavior. Our model outperforms GPT-4o by 12.77% in decision making and 12.49% in action generation.