Serving Heterogeneous LoRA Adapters in Distributed LLM Inference Systems
作者: Shashwat Jaiswal, Shrikara Arun, Anjaly Parayil, Ankur Mallick, Spyros Mastorakis, Alind Khare, Chloi Alverti, Renee St Amant, Chetan Bansal, Victor Rühle, Josep Torrellas
分类: cs.DC, cs.AI, cs.LG
发布日期: 2025-11-28
💡 一句话要点
LoRAServe:一种工作负载感知的LoRA适配器动态部署与路由框架,解决异构LoRA服务中的性能倾斜问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LoRA 大规模语言模型 参数高效微调 动态适配器放置 GPU Direct RDMA 异构计算 服务优化
📋 核心要点
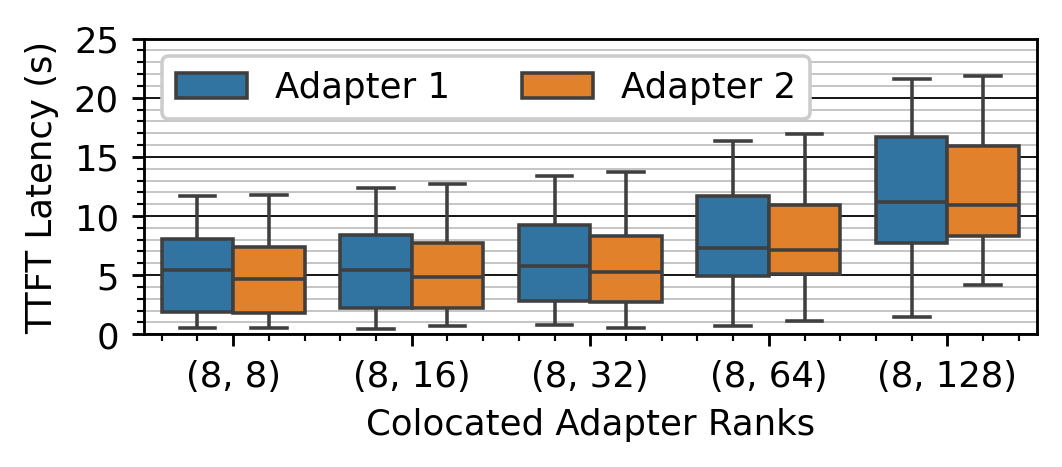
- 现有LoRA服务系统忽略了适配器秩(大小)的异构性,导致严重的性能倾斜和GPU资源浪费。
- LoRAServe通过动态适配器放置和路由,以及GPU Direct RDMA,实现负载均衡和资源高效利用。
- 在实际生产环境中,LoRAServe显著提升了吞吐量,降低了延迟,并减少了GPU使用量。
📝 摘要(中文)
低秩适应(LoRA)已成为大规模语言模型(LLM)参数高效微调的事实标准方法,能够快速适应不同的领域。在生产环境中,基于LoRA的模型以大规模方式提供服务,创建了具有数百个适配器共享一个基础模型的多租户环境。然而,目前最先进的服务系统在共同批处理异构适配器时,没有考虑到秩(大小)的可变性,导致严重的性能倾斜,最终需要添加更多的GPU来满足服务水平目标(SLO)。现有的优化,主要集中在加载、缓存和内核执行方面,忽略了这种异构性,导致GPU资源未得到充分利用。我们提出了LoRAServe,一种工作负载感知的动态适配器放置和路由框架,旨在解决LoRA服务中的秩多样性问题。通过动态地在GPU之间重新平衡适配器,并利用GPU Direct RDMA进行远程访问,LoRAServe在真实世界的工作负载漂移下,最大限度地提高了吞吐量,并最大限度地降低了尾部延迟。在Company X的生产跟踪数据上的评估表明,与最先进的系统相比,LoRAServe在满足SLO约束的条件下,吞吐量提高了2倍,TTFT降低了9倍,同时使用的GPU减少了50%。
🔬 方法详解
问题定义:现有LoRA服务系统在处理大量异构LoRA适配器时,由于不同适配器的秩(rank)大小差异显著,导致共同批处理时出现严重的性能倾斜。这种性能倾斜使得部分GPU负载过重,而其他GPU则利用率不足,最终需要增加更多GPU才能满足服务水平目标(SLO)。现有的优化方法主要集中在模型加载、缓存和内核执行层面,忽略了适配器异构性带来的影响。
核心思路:LoRAServe的核心思路是根据工作负载动态地将LoRA适配器放置到不同的GPU上,并利用GPU Direct RDMA技术实现适配器在GPU之间的远程访问。通过动态调整适配器的分布,LoRAServe能够实现GPU之间的负载均衡,从而提高整体吞吐量和降低延迟。此外,LoRAServe还考虑了工作负载的动态变化,能够根据实际情况实时调整适配器的放置策略。
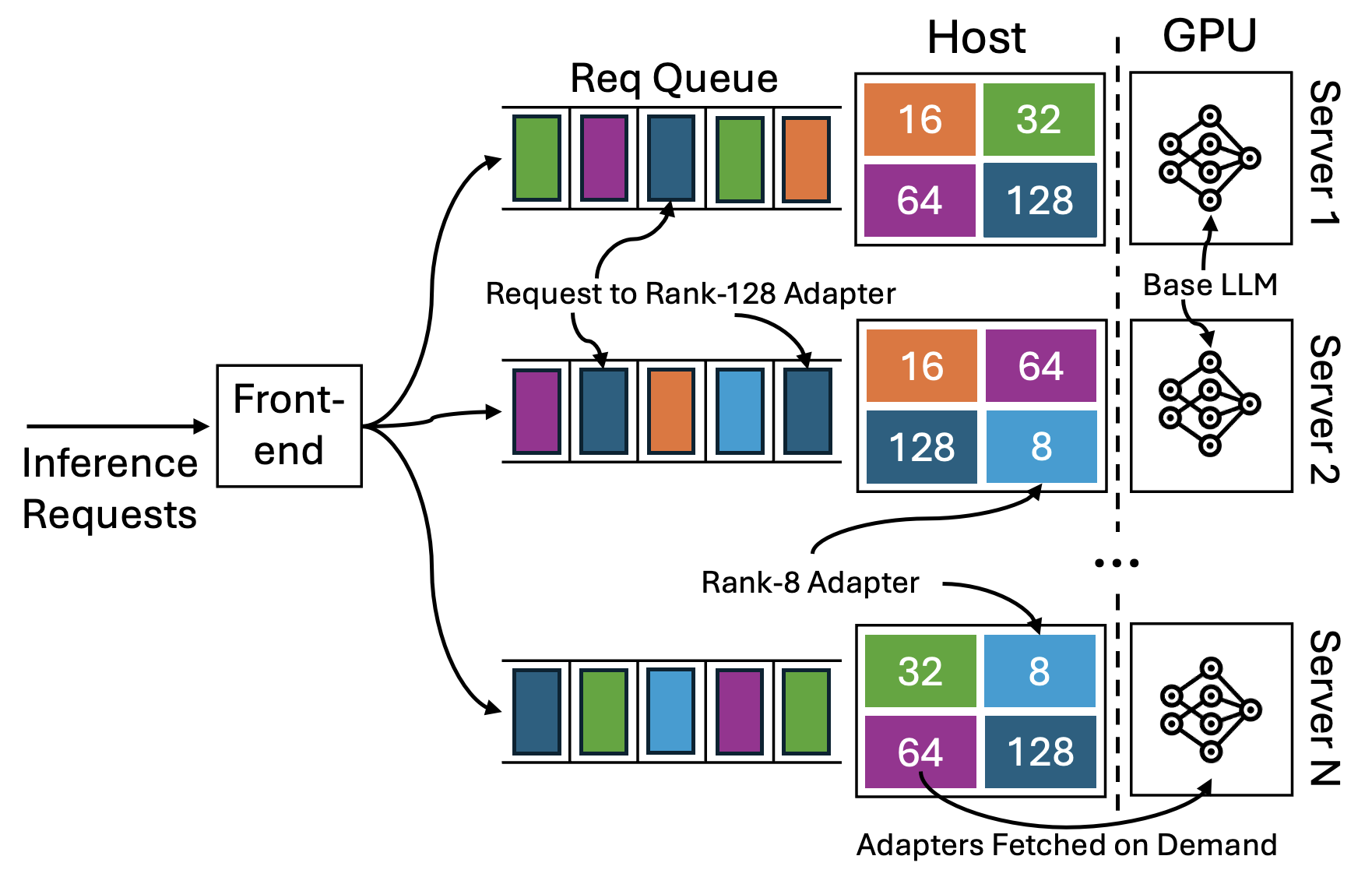
技术框架:LoRAServe的整体架构包含以下几个主要模块:1) 监控模块:负责监控各个GPU的负载情况,包括GPU利用率、内存使用率等。2) 放置策略模块:根据监控模块收集到的信息,决定将哪些适配器放置到哪些GPU上。该模块会考虑适配器的秩大小、GPU的剩余资源等因素。3) 路由模块:负责将请求路由到相应的GPU上。如果请求所需的适配器不在本地GPU上,则通过GPU Direct RDMA技术从远程GPU获取。4) 适配器管理模块:负责适配器的加载、卸载和缓存管理。
关键创新:LoRAServe最重要的技术创新点在于其工作负载感知的动态适配器放置和路由策略。与现有方法相比,LoRAServe能够根据实际的工作负载情况,动态地调整适配器的分布,从而实现更好的负载均衡和资源利用率。此外,LoRAServe还利用GPU Direct RDMA技术实现了适配器在GPU之间的远程访问,避免了数据拷贝的开销。
关键设计:LoRAServe的关键设计包括:1) 动态放置策略:采用基于贪心算法的放置策略,优先将秩较大的适配器放置到负载较轻的GPU上。2) 路由策略:采用基于最小延迟的路由策略,优先将请求路由到本地GPU,如果本地GPU没有所需的适配器,则路由到延迟最低的远程GPU。3) 缓存策略:采用基于LRU(Least Recently Used)的缓存策略,优先缓存最近使用的适配器。
🖼️ 关键图片

📊 实验亮点
在Company X的生产跟踪数据上进行的评估表明,与最先进的系统相比,LoRAServe在满足SLO约束的条件下,吞吐量提高了2倍,TTFT(Time To First Token)降低了9倍,同时使用的GPU减少了50%。这些结果表明,LoRAServe能够显著提高LoRA服务的性能和效率。
🎯 应用场景
LoRAServe可广泛应用于需要服务大量异构LoRA适配器的场景,例如多租户LLM服务、个性化推荐系统、以及需要快速适应不同领域的AI应用。通过提高吞吐量、降低延迟和减少GPU使用量,LoRAServe能够显著降低服务成本,并提升用户体验。未来,LoRAServe可以进一步扩展到支持更多类型的适配器和更复杂的硬件架构。
📄 摘要(原文)
Low-Rank Adaptation (LoRA) has become the de facto method for parameter-efficient fine-tuning of large language models (LLMs), enabling rapid adaptation to diverse domains. In production, LoRA-based models are served at scale, creating multi-tenant environments with hundreds of adapters sharing a base model. However, state-of-the-art serving systems co-batch heterogeneous adapters without accounting for rank (size) variability, leading to severe performance skew, which ultimately requires adding more GPUs to satisfy service-level objectives (SLOs). Existing optimizations, focused on loading, caching, and kernel execution, ignore this heterogeneity, leaving GPU resources underutilized. We present LoRAServe, a workload-aware dynamic adapter placement and routing framework designed to tame rank diversity in LoRA serving. By dynamically rebalancing adapters across GPUs and leveraging GPU Direct RDMA for remote access, LoRAServe maximizes throughput and minimizes tail latency under real-world workload drift. Evaluations on production traces from Company X show that LoRAServe elicits up to 2$\times$ higher throughput, up to 9$\times$ lower TTFT, while using up to 50% fewer GPUs under SLO constraints compared to state-of-the-art systems.