QoS-Aware Dynamic CU Selection in O-RAN with Graph-Based Reinforcement Learning
作者: Sebastian Racedo, Brigitte Jaumard, Oscar Delgado, Meysam Masoudi
分类: cs.NI, cs.AI, cs.LG
发布日期: 2025-11-21
💡 一句话要点
提出基于图神经网络强化学习的O-RAN动态CU选择方法,优化QoS和能耗。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: O-RAN 动态CU选择 图神经网络 深度强化学习 服务功能链 QoS 能源效率
📋 核心要点
- 传统无线接入网中逻辑功能与物理位置的静态绑定,在时变流量和资源条件下效率低下,难以满足动态需求。
- 论文提出一种基于图神经网络强化学习的动态O-CU选择方法,通过联合优化路由和O-CU位置,实现节能和QoS保障。
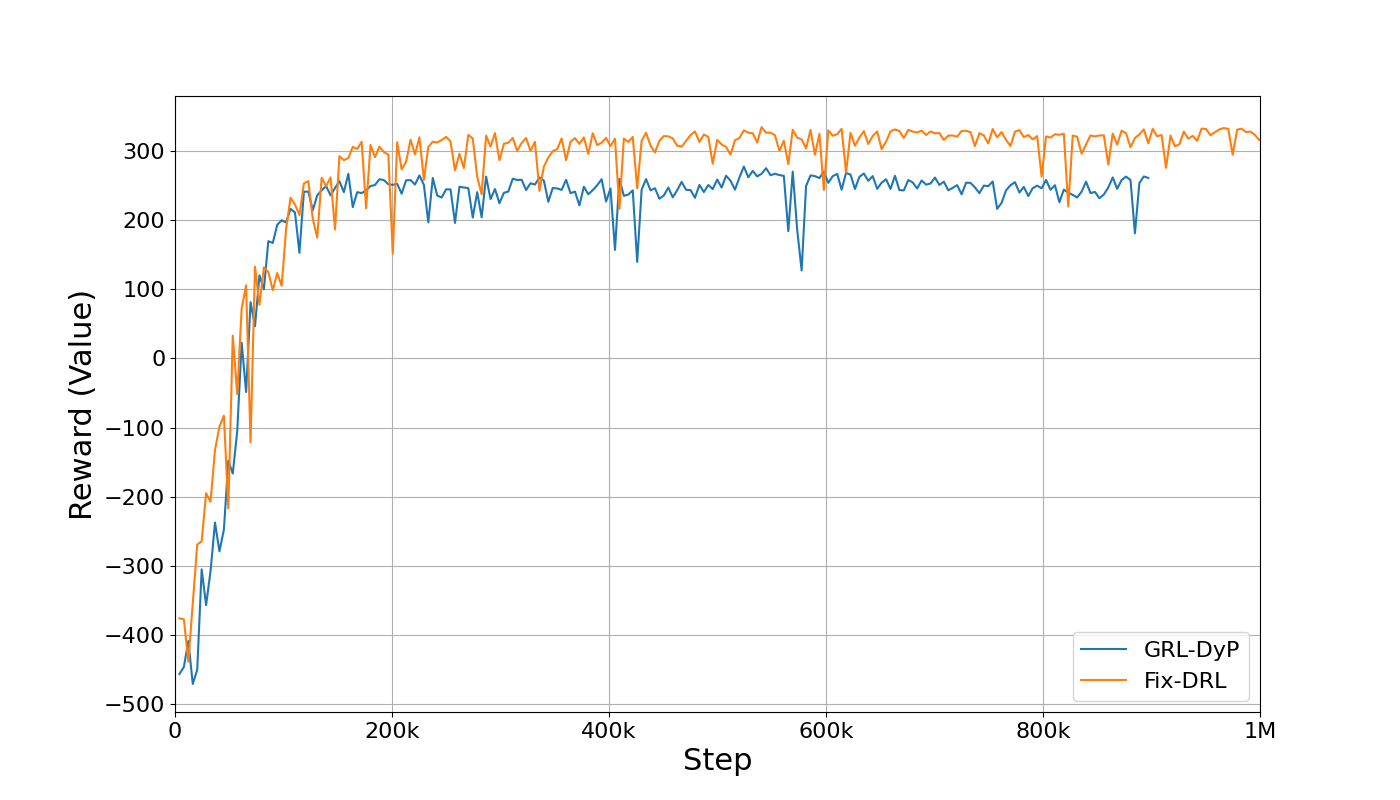
- 实验结果表明,与静态映射相比,该方法在满足QoS的前提下,显著降低了网络能耗,验证了其在O-RAN部署中的实用性。
📝 摘要(中文)
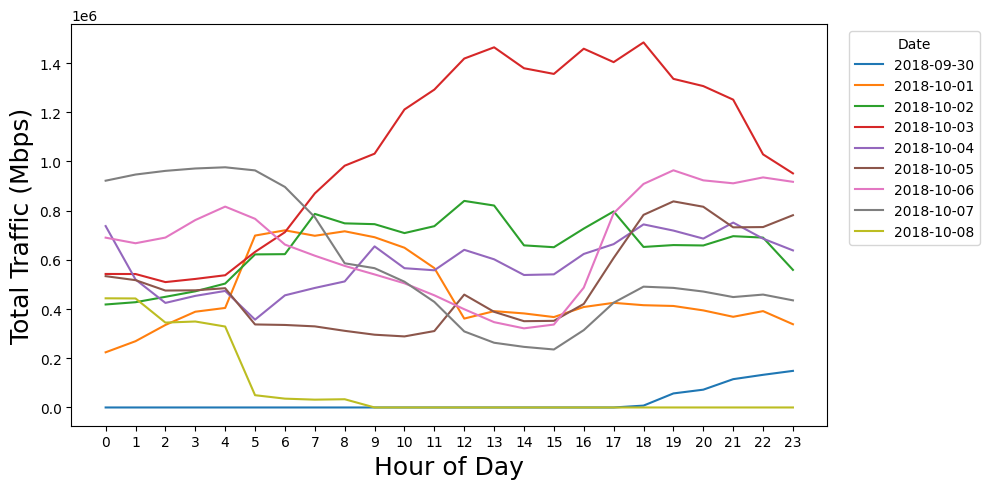
本文针对开放无线接入网络(O-RAN)中传统静态映射导致的资源利用率低效问题,提出了一种基于图神经网络(GNN)辅助的深度强化学习(DRL)方法GRLDyP,用于动态服务功能链(SFC)配置和O-CU选择。该方法将问题建模为马尔可夫决策过程,通过GNN编码网络拓扑和资源利用率,DRL策略学习平衡服务质量(QoS)、延迟和能耗。GRLDyP能够为每个传入的服务流联合选择路由和O-CU位置,从而最小化网络能耗并满足QoS约束。在蒙特利尔市24小时流量数据集上的评估表明,与静态映射基线相比,动态O-CU选择和路由显著降低了能耗,且不违反QoS。结果表明,基于DRL的SFC配置是节能、资源自适应O-RAN部署的实用控制方法。
🔬 方法详解
问题定义:传统O-RAN部署中,逻辑功能与物理位置的映射是静态的,无法根据实时流量和资源状况进行调整,导致资源利用率低下和能源浪费。现有方法难以在保证服务质量(QoS)的同时,实现动态的资源分配和节能优化。
核心思路:论文的核心思路是将O-CU的选择和路由问题建模为一个马尔可夫决策过程(MDP),并利用深度强化学习(DRL)来学习最优策略。通过图神经网络(GNN)来提取网络拓扑和资源利用率的特征,辅助DRL智能体做出决策,从而实现动态的O-CU选择和路由优化,以最小化网络能耗并满足QoS约束。
技术框架:整体框架包含以下几个主要模块:1) 环境建模:将O-RAN网络建模为图结构,节点表示O-CU候选位置和网络节点,边表示链路。2) 状态表示:使用GNN编码网络拓扑和资源利用率信息,包括CPU利用率、带宽等。3) 动作空间:定义动作空间为O-CU的选择和路由选择。4) 奖励函数:设计奖励函数,综合考虑能耗、延迟和QoS等因素。5) DRL智能体:使用DRL算法训练智能体,使其能够根据当前状态选择最优的动作。
关键创新:论文的关键创新在于将图神经网络(GNN)与深度强化学习(DRL)相结合,用于解决O-RAN中的动态O-CU选择和路由问题。GNN能够有效地提取网络拓扑和资源利用率的特征,为DRL智能体提供更全面的状态信息,从而提高决策的准确性和效率。与传统的基于规则或优化的方法相比,该方法能够更好地适应动态变化的网络环境。
关键设计:论文中GNN采用多层图卷积网络(GCN)结构,用于提取节点和边的特征。DRL智能体采用Actor-Critic框架,Actor网络负责选择动作,Critic网络负责评估动作的价值。奖励函数的设计至关重要,需要平衡能耗、延迟和QoS等多个目标。具体而言,奖励函数可以设置为能耗的负值,同时对违反QoS约束的行为进行惩罚。训练过程中,采用经验回放和目标网络等技术来提高训练的稳定性和收敛速度。
🖼️ 关键图片
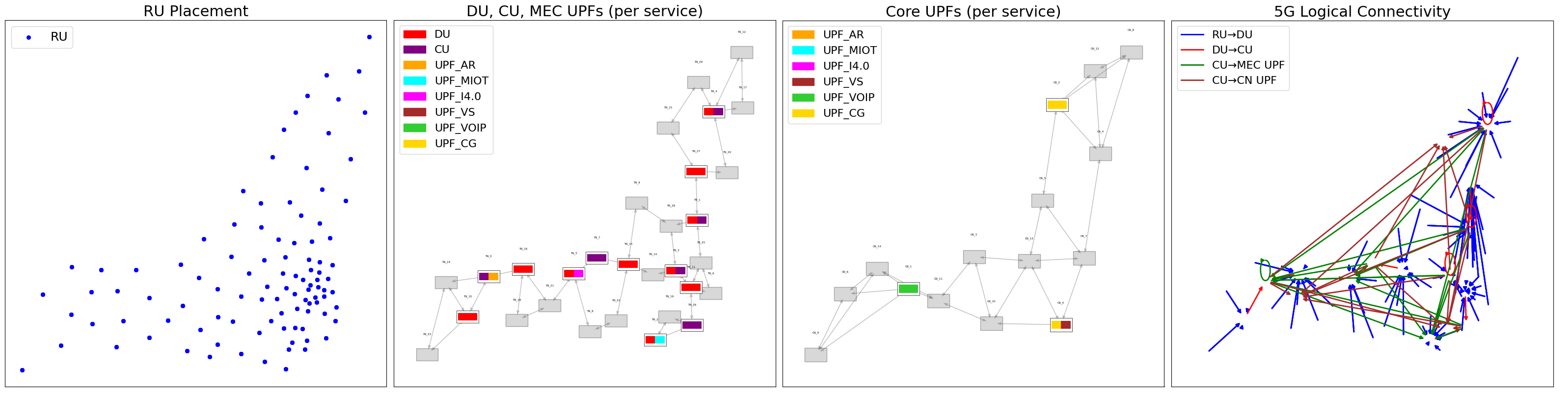
📊 实验亮点
实验结果表明,与静态映射基线相比,所提出的GRLDyP方法在满足QoS约束的前提下,显著降低了网络能耗。具体而言,在蒙特利尔市24小时流量数据集上的评估显示,GRLDyP能够将能耗降低约20%-30%。这表明动态O-CU选择和路由能够有效地提高O-RAN的能源效率。
🎯 应用场景
该研究成果可应用于未来的开放无线接入网络(O-RAN)部署中,实现节能、资源自适应的网络管理。通过动态调整O-CU的位置和路由,可以提高网络资源利用率,降低能源消耗,并保障用户的服务质量。该方法还可扩展到其他网络资源管理场景,例如虚拟网络功能(VNF)的部署和调度。
📄 摘要(原文)
Open Radio Access Network (O RAN) disaggregates conventional RAN into interoperable components, enabling flexible resource allocation, energy savings, and agile architectural design. In legacy deployments, the binding between logical functions and physical locations is static, which leads to inefficiencies under time varying traffic and resource conditions. We address this limitation by relaxing the fixed mapping and performing dynamic service function chain (SFC) provisioning with on the fly O CU selection. We formulate the problem as a Markov decision process and solve it using GRLDyP, i.e., a graph neural network (GNN) assisted deep reinforcement learning (DRL). The proposed agent jointly selects routes and the O-CU location (from candidate sites) for each incoming service flow to minimize network energy consumption while satisfying quality of service (QoS) constraints. The GNN encodes the instantaneous network topology and resource utilization (e.g., CPU and bandwidth), and the DRL policy learns to balance grade of service, latency, and energy. We perform the evaluation of GRLDyP on a data set with 24-hour traffic traces from the city of Montreal, showing that dynamic O CU selection and routing significantly reduce energy consumption compared to a static mapping baseline, without violating QoS. The results highlight DRL based SFC provisioning as a practical control primitive for energy-aware, resource-adaptive O-RAN deployments.