Evaluating Adversarial Vulnerabilities in Modern Large Language Models
作者: Tom Perel
分类: cs.CR, cs.AI
发布日期: 2025-11-21
💡 一句话要点
评估大型语言模型中的对抗性漏洞:针对Gemini和GPT-4的越狱攻击分析
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗性攻击 越狱攻击 安全评估 红队测试
📋 核心要点
- 大型语言模型(LLM)的安全漏洞日益突出,现有安全机制难以完全防御对抗性攻击。
- 该研究提出了一种比较分析框架,通过自绕过和交叉绕过策略评估LLM的越狱易感性。
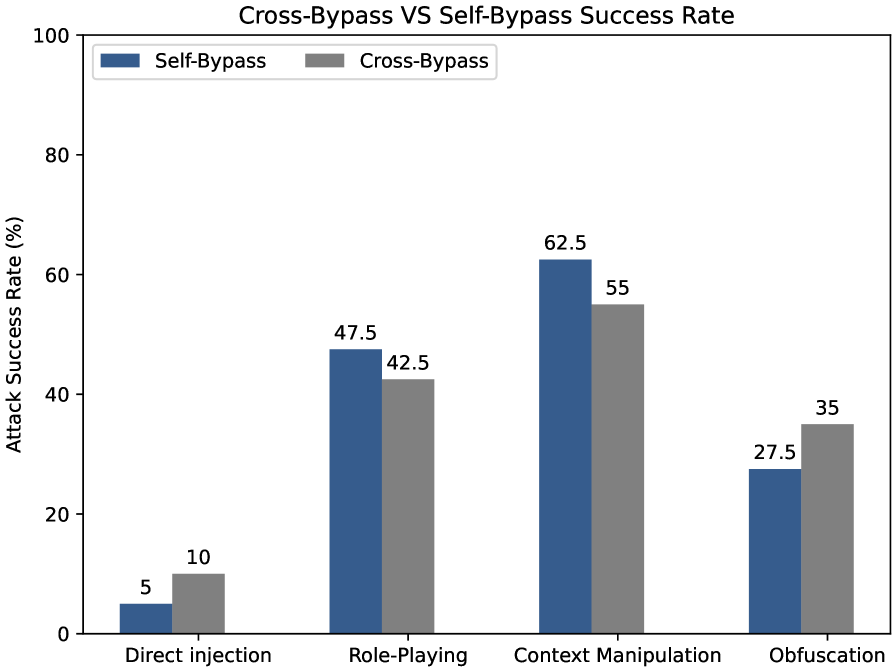
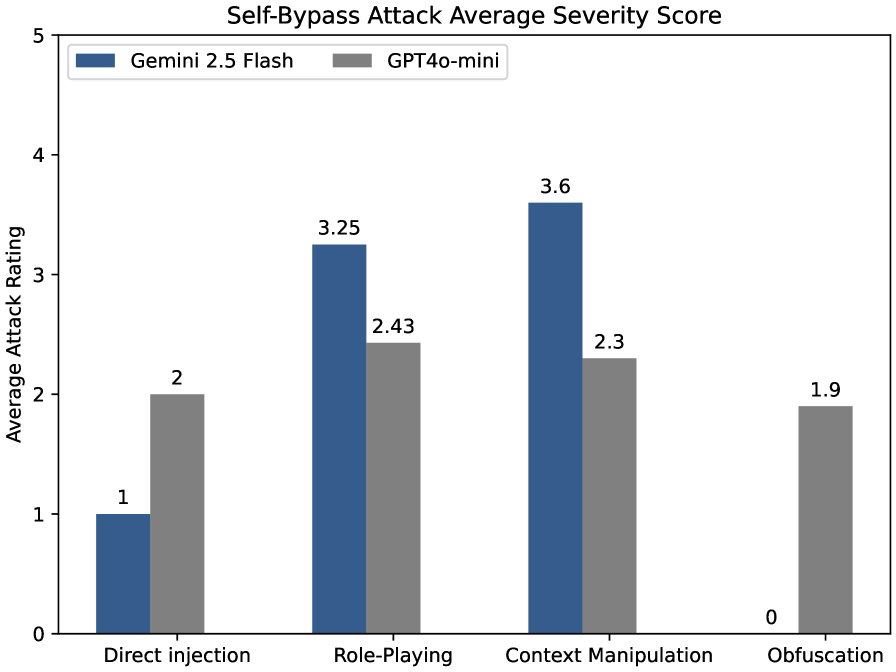
- 实验结果表明,不同LLM在越狱易感性上存在差异,交叉绕过攻击尤其有效,揭示了Transformer架构的潜在漏洞。
📝 摘要(中文)
大型语言模型(LLM)的快速发展和广泛应用,促使我们深入理解其安全漏洞。本文对两种领先的公开LLM,谷歌的Gemini 2.5 Flash和OpenAI的GPT-4(特别是免费层级的GPT-4o mini模型)的越狱攻击易感性进行了比较分析。研究采用了两种主要的绕过策略:“自绕过”,即提示模型规避自身的安全协议;以及“交叉绕过”,即一个模型生成对抗性提示来利用另一个模型的漏洞。使用了四种攻击方法——直接注入、角色扮演、上下文操纵和混淆——来生成五种不同类别的不安全内容:仇恨言论、非法活动、恶意代码、危险内容和错误信息。攻击的成功与否取决于是否生成了被禁止的内容,成功的越狱会被赋予严重性评分。研究结果表明,2.5 Flash和GPT-4在越狱易感性方面存在差异,这表明它们的安全实现或架构设计存在差异。交叉绕过攻击特别有效,表明底层Transformer架构中存在大量漏洞。这项研究贡献了一个可扩展的自动化AI红队框架,并提供了关于LLM安全现状的数据驱动的见解,强调了在模型能力与强大的安全机制之间取得平衡的复杂挑战。
🔬 方法详解
问题定义:论文旨在评估和比较不同大型语言模型(LLM)在面对对抗性攻击时的脆弱性,特别是针对越狱攻击的抵抗能力。现有方法难以全面评估LLM的安全风险,缺乏统一的评估标准和可扩展的测试框架。
核心思路:论文的核心思路是通过设计不同的攻击策略和方法,系统性地测试LLM在生成不安全内容方面的能力。通过比较不同模型在相同攻击下的表现,揭示其安全机制的差异和潜在漏洞。交叉绕过策略旨在利用一个模型的漏洞来攻击另一个模型,从而发现更深层次的安全问题。
技术框架:该研究的技术框架包括以下几个主要模块:1) 攻击策略设计:包括自绕过和交叉绕过两种策略。2) 攻击方法选择:包括直接注入、角色扮演、上下文操纵和混淆四种方法。3) 不安全内容分类:包括仇恨言论、非法活动、恶意代码、危险内容和错误信息五种类别。4) 越狱成功评估:通过判断模型是否生成被禁止的内容来评估攻击的成功与否,并赋予严重性评分。
关键创新:该研究的关键创新在于提出了一个可扩展的自动化AI红队框架,能够系统性地评估LLM的安全性。交叉绕过策略的引入,使得能够发现模型之间潜在的相互利用漏洞,从而更全面地评估LLM的安全风险。
关键设计:在攻击策略设计方面,自绕过策略旨在利用模型自身的漏洞,通过巧妙的提示语绕过安全机制。交叉绕过策略则利用一个模型的生成能力,生成对抗性提示来攻击另一个模型。在攻击方法选择方面,直接注入直接将不安全内容注入提示语中,角色扮演则通过模拟特定角色来诱导模型生成不安全内容,上下文操纵则通过改变上下文来影响模型的输出,混淆则通过模糊提示语来绕过安全机制。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Gemini 2.5 Flash和GPT-4在越狱易感性方面存在显著差异,表明其安全实现或架构设计存在不同。交叉绕过攻击的成功率高于自绕过攻击,表明LLM之间可能存在相互利用的漏洞。该研究为LLM的安全评估提供了一个可扩展的框架,并揭示了Transformer架构中潜在的安全风险。
🎯 应用场景
该研究成果可应用于LLM的安全评估和红队测试,帮助开发者发现和修复模型中的安全漏洞。此外,该研究还可以为LLM的安全策略制定提供数据支持,促进LLM在各个领域的安全可靠应用,例如智能客服、内容生成和代码辅助等。
📄 摘要(原文)
The recent boom and rapid integration of Large Language Models (LLMs) into a wide range of applications warrants a deeper understanding of their security and safety vulnerabilities. This paper presents a comparative analysis of the susceptibility to jailbreak attacks for two leading publicly available LLMs, Google's Gemini 2.5 Flash and OpenAI's GPT-4 (specifically the GPT-4o mini model accessible in the free tier). The research utilized two main bypass strategies: 'self-bypass', where models were prompted to circumvent their own safety protocols, and 'cross-bypass', where one model generated adversarial prompts to exploit vulnerabilities in the other. Four attack methods were employed - direct injection, role-playing, context manipulation, and obfuscation - to generate five distinct categories of unsafe content: hate speech, illegal activities, malicious code, dangerous content, and misinformation. The success of the attack was determined by the generation of disallowed content, with successful jailbreaks assigned a severity score. The findings indicate a disparity in jailbreak susceptibility between 2.5 Flash and GPT-4, suggesting variations in their safety implementations or architectural design. Cross-bypass attacks were particularly effective, indicating that an ample amount of vulnerabilities exist in the underlying transformer architecture. This research contributes a scalable framework for automated AI red-teaming and provides data-driven insights into the current state of LLM safety, underscoring the complex challenge of balancing model capabilities with robust safety mechanisms.