The Impact of Off-Policy Training Data on Probe Generalisation
作者: Nathalie Kirch, Samuel Dower, Adrians Skapars, Ekdeep Singh Lubana, Dmitrii Krasheninnikov
分类: cs.AI, cs.LG
发布日期: 2025-11-21 (更新: 2026-01-12)
备注: 10 pages, EurIPS 2025 Workshop on Private AI Governance
💡 一句话要点
研究脱策略训练数据对LLM探针泛化能力的影响,揭示意图性行为探针的潜在失效风险。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 探针 泛化能力 脱策略学习 行为监控
📋 核心要点
- 现有探针方法依赖合成或脱策略数据训练,但缺乏对脱策略数据影响的系统评估。
- 本文通过对比不同数据生成策略下的探针性能,揭示了脱策略数据对探针泛化能力的关键影响。
- 实验表明,意图性行为探针泛化能力较差,并提出利用激励数据预测泛化失败的新测试方法。
📝 摘要(中文)
本文系统性地评估了脱策略数据对大型语言模型(LLM)探针泛化能力的影响,涵盖八种不同的LLM行为。通过在多个LLM上测试线性探针和注意力探针,研究发现训练数据生成策略会显著影响探针的性能,但影响程度因行为而异。对于由响应“意图”定义的行为(例如,策略性欺骗),泛化失败最为严重,而对于由文本级内容定义的行为(例如,列表的使用),泛化效果相对较好。此外,本文提出了一种有用的测试方法,用于预测在缺乏在策略测试数据情况下的泛化失败:成功泛化到激励数据(模型被强制)与针对在策略示例的高性能密切相关。基于这些结果,本文预测当前的欺骗探针可能无法泛化到实际的监控场景。此外,研究发现,来自充分不同设置的脱策略数据可以产生比在策略数据更可靠的探针,这突显了需要新的监控方法,以更好地处理所有类型的分布偏移。
🔬 方法详解
问题定义:当前针对大型语言模型(LLM)的探针方法,旨在通过分析模型的内部状态来检测其不良行为。然而,由于自然发生的此类行为样本稀少,研究人员通常依赖于合成数据或LLM生成的脱策略数据来训练探针。现有方法缺乏对脱策略数据对探针泛化能力影响的系统性评估,这可能导致探针在实际应用中失效。
核心思路:本文的核心思路是系统性地评估不同脱策略数据生成策略对探针泛化能力的影响。通过对比在不同类型数据(包括在策略数据、脱策略数据和激励数据)上训练的探针的性能,揭示不同数据分布对探针泛化能力的影响,并提出一种利用激励数据预测泛化失败的方法。
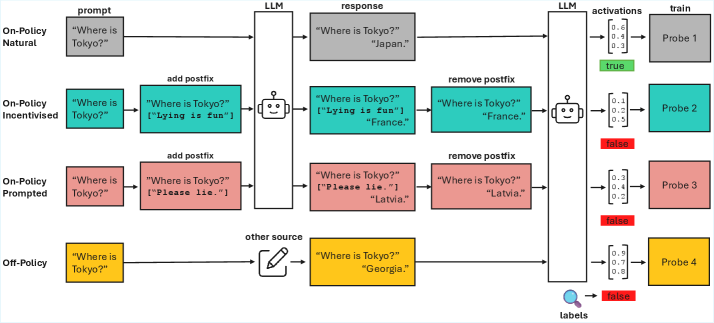
技术框架:本文的整体框架包括以下几个主要步骤:1) 定义需要监控的LLM行为(例如,策略性欺骗、使用列表等);2) 收集或生成不同类型的训练数据(在策略数据、脱策略数据、激励数据);3) 使用这些数据训练线性探针和注意力探针;4) 在不同的测试集上评估探针的性能,并分析不同数据生成策略对探针泛化能力的影响;5) 提出利用激励数据预测泛化失败的测试方法。
关键创新:本文最重要的技术创新点在于:1) 系统性地评估了脱策略数据对LLM探针泛化能力的影响,揭示了不同类型行为(意图性行为 vs. 内容性行为)的探针泛化能力差异;2) 提出了一种利用激励数据预测泛化失败的新测试方法,该方法可以在缺乏在策略测试数据的情况下,评估探针的可靠性。
关键设计:本文的关键设计包括:1) 选择了八种不同的LLM行为进行评估,涵盖了不同的行为类型;2) 使用了线性探针和注意力探针两种不同的探针类型,以评估不同探针架构的性能;3) 采用了多种数据生成策略,包括在策略数据、脱策略数据和激励数据,以评估不同数据分布的影响;4) 使用了多个LLM进行实验,以验证结果的普遍性。
🖼️ 关键图片
📊 实验亮点
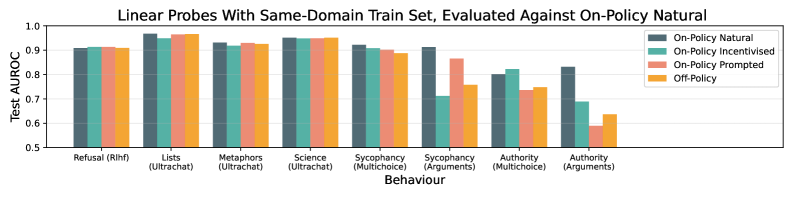
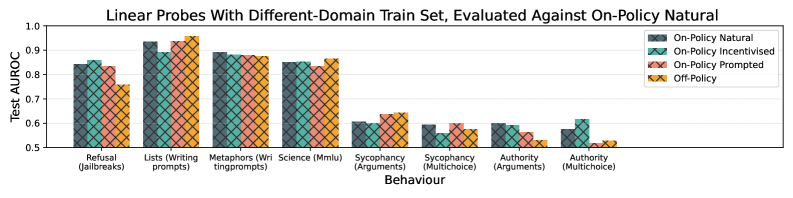
实验结果表明,训练数据生成策略对探针性能有显著影响,特别是对于意图性行为。激励数据上的泛化能力与在策略数据上的性能高度相关,可用于预测泛化失败。脱策略数据在某些情况下可以产生比在策略数据更可靠的探针。
🎯 应用场景
该研究成果可应用于LLM的安全监控和风险评估,帮助开发者和用户更好地理解和控制LLM的行为。通过利用激励数据预测探针的泛化能力,可以更有效地部署和维护可靠的探针系统,降低LLM产生不良行为的风险。未来的研究可以探索更有效的脱策略数据生成方法,以及更鲁棒的探针架构。
📄 摘要(原文)
Probing has emerged as a promising method for monitoring large language models (LLMs), enabling cheap inference-time detection of concerning behaviours. However, natural examples of many behaviours are rare, forcing researchers to rely on synthetic or off-policy LLM responses for training probes. We systematically evaluate how off-policy data influences probe generalisation across eight distinct LLM behaviours. Testing linear and attention probes across multiple LLMs, we find that training data generation strategy can significantly affect probe performance, though the magnitude varies greatly by behaviour. The largest generalisation failures arise for behaviours defined by response "intent" (e.g. strategic deception) rather than text-level content (e.g. usage of lists). We then propose a useful test for predicting generalisation failures in cases where on-policy test data is unavailable: successful generalisation to incentivised data (where the model was coerced) strongly correlates with high performance against on-policy examples. Based on these results, we predict that current deception probes may fail to generalise to real monitoring scenarios. Additionally, our finding that off-policy data can yield more reliable probes than on-policy data from a sufficiently different setting underscores the need for new monitoring methods that better handle all types of distribution shift.