Revisiting Disaggregated Large Language Model Serving for Performance and Energy Implications
作者: Jiaxi Li, Yue Zhu, Eun Kyung Lee, Klara Nahrstedt
分类: cs.PF, cs.AI, cs.AR, cs.DC
发布日期: 2025-11-14
💡 一句话要点
重评估LLM解耦服务:性能与能耗影响分析及优化策略探索
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 解耦服务 KV缓存 性能评估 能耗分析 动态电压频率缩放 GPU 推理优化
📋 核心要点
- 现有LLM服务通常将预填充和解码阶段置于同一GPU,资源竞争导致效率瓶颈,解耦服务虽有潜力但缺乏系统性评估。
- 该论文通过细致的基准测试,对比不同KV缓存传输路径和优化策略下的解耦服务性能与能耗,揭示其内在权衡。
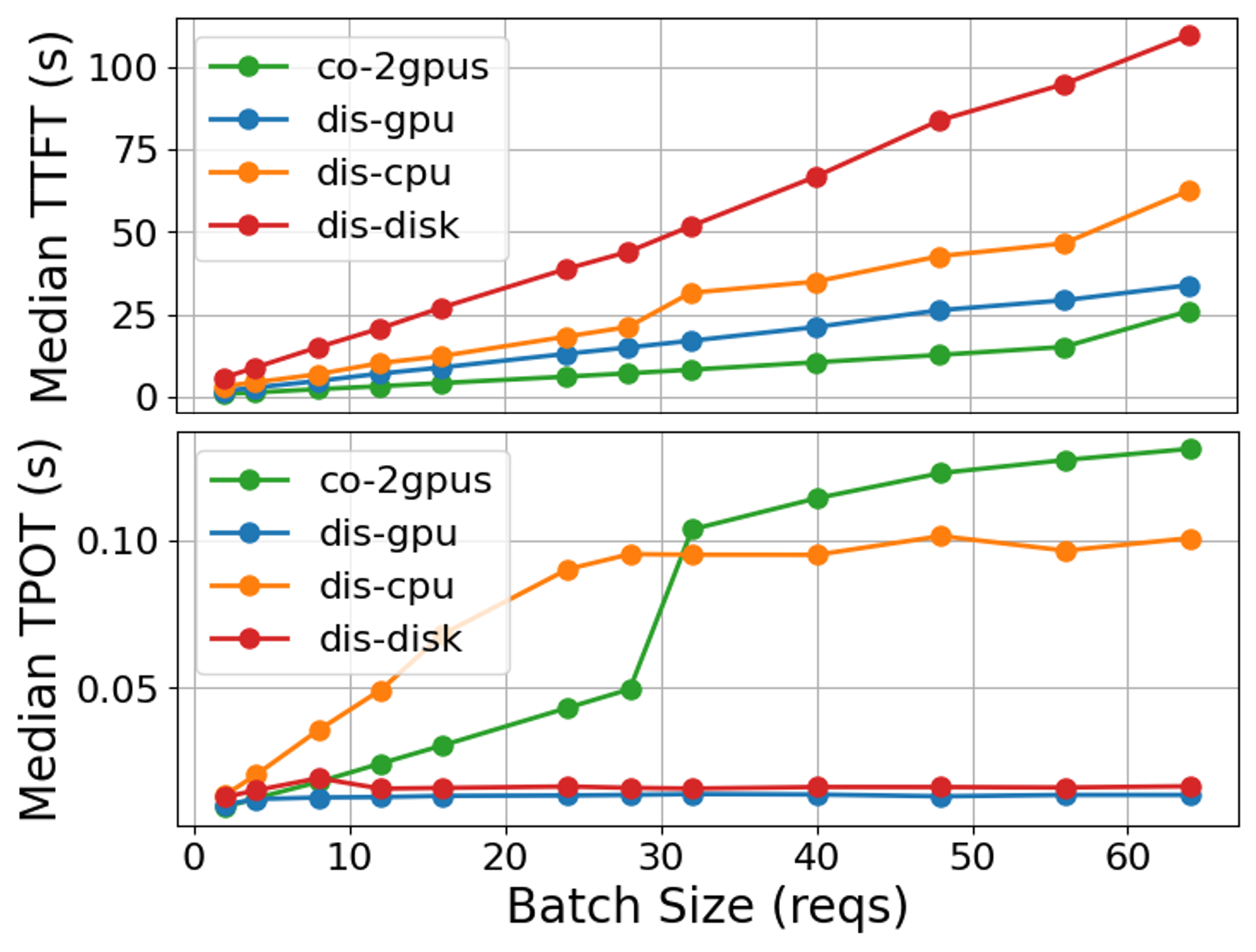
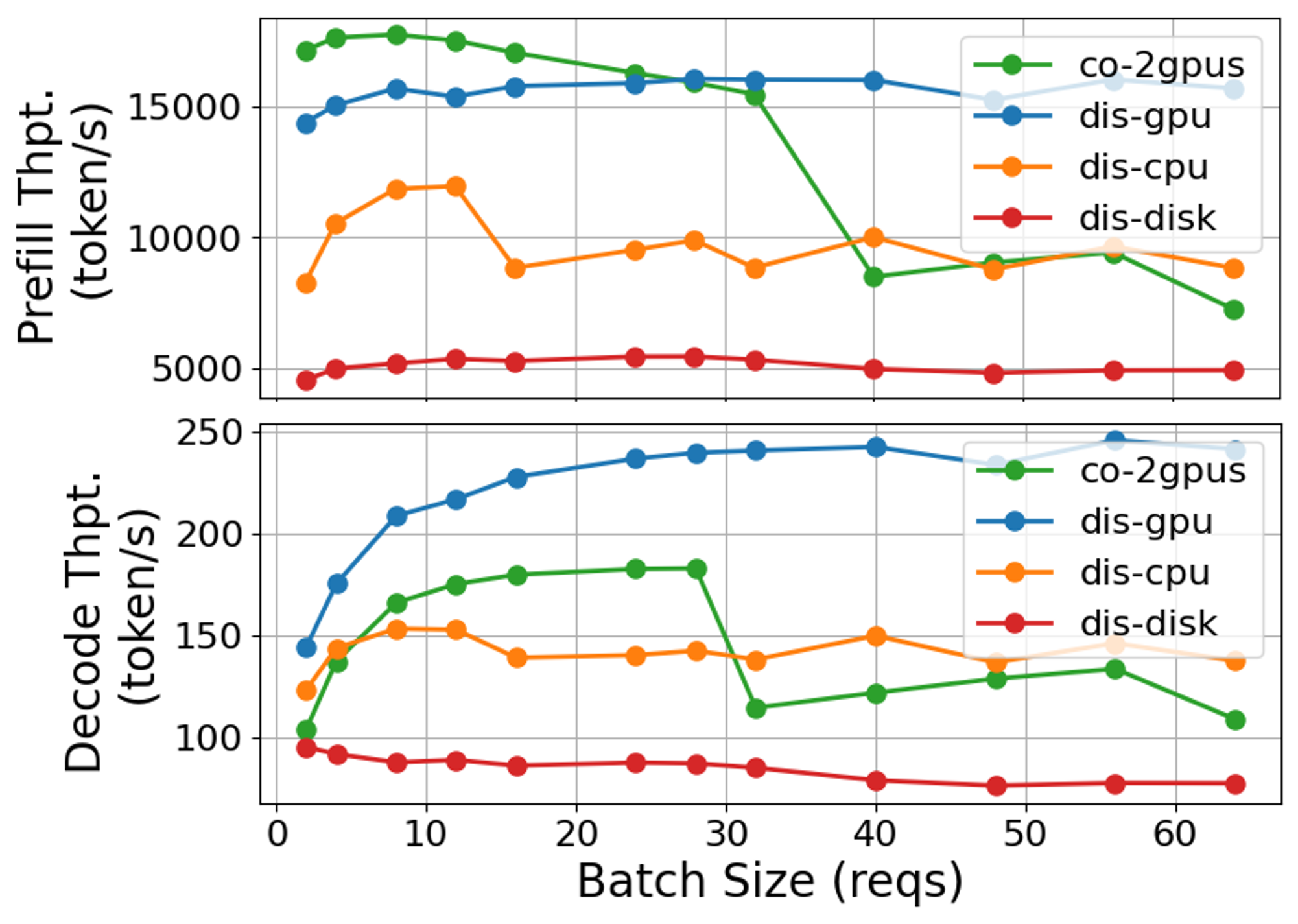
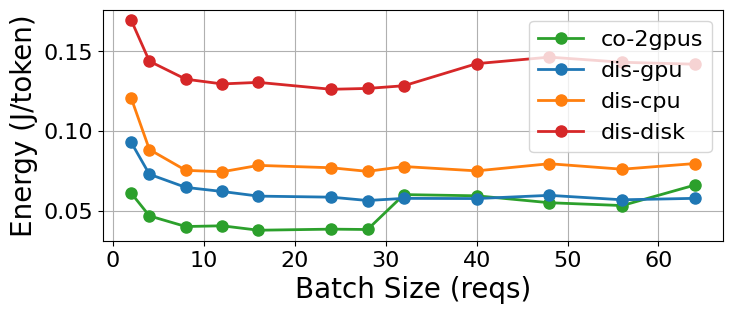
- 实验结果表明,解耦服务的性能优势依赖于请求负载和KV传输介质,且阶段性频率缩放不一定能带来节能效果。
📝 摘要(中文)
与传统的将预填充(prefill)和解码(decode)阶段置于同一GPU上的大型语言模型(LLM)服务不同,解耦服务将不同的GPU分别用于预填充和解码工作负载。一旦预填充GPU完成其任务,KV缓存必须传输到解码GPU。虽然现有的工作已经提出了各种跨不同内存和存储层的KV缓存传输路径,但仍然缺乏系统的基准测试来比较它们的性能和能源效率。同时,尽管诸如KV缓存重用和频率缩放等优化技术已被用于解耦服务,但它们的性能和能源影响尚未经过严格的基准测试。本文通过在不同的KV传输介质和优化策略下重新评估预填充-解码解耦来填补这一研究空白。具体来说,我们包括一个新的共址服务基线,并评估不同KV缓存传输路径下的解耦设置。通过使用动态电压和频率缩放(DVFS)的GPU分析,我们识别并比较所有设置中的性能-能量帕累托前沿,以评估解耦所实现的潜在节能。我们的结果表明,预填充-解码解耦的性能优势不能保证,并且取决于请求负载和KV传输介质。此外,由解耦实现的阶段性独立频率缩放不会导致节能,因为解耦服务本身具有更高的能耗。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)解耦服务中,不同KV缓存传输方式和优化策略对性能和能耗影响缺乏系统性评估的问题。现有方法主要痛点在于,虽然提出了多种KV缓存传输路径和优化技术,但缺乏充分的基准测试来指导实际部署,导致性能提升不确定,甚至可能增加能耗。
核心思路:论文的核心思路是通过构建一个全面的基准测试框架,系统性地评估不同KV缓存传输介质(例如,GPU内存、CPU内存、NVMe SSD等)和优化策略(例如,KV缓存重用、动态电压和频率缩放DVFS)对解耦LLM服务性能和能耗的影响。通过对比不同配置下的性能-能耗帕累托前沿,揭示解耦服务的潜在节能空间和性能瓶颈。
技术框架:论文构建了一个包含以下主要模块的基准测试框架:1) LLM服务引擎,支持共址服务和解耦服务两种模式;2) KV缓存传输模块,实现不同存储介质之间的KV缓存传输;3) 性能监控模块,用于收集延迟、吞吐量等性能指标;4) 功耗监控模块,用于测量GPU和CPU的功耗;5) DVFS控制模块,用于动态调整GPU的电压和频率。整体流程包括:配置LLM服务模式和KV缓存传输路径,运行LLM推理任务,收集性能和功耗数据,分析性能-能耗帕累托前沿。
关键创新:论文的关键创新在于对LLM解耦服务进行了全面的性能和能耗分析,揭示了以下几个重要发现:1) 解耦服务的性能优势并非总是存在,取决于请求负载和KV缓存传输介质;2) 阶段性独立频率缩放并不一定能带来节能效果,因为解耦服务本身具有更高的能耗;3) 不同的KV缓存传输介质对性能和能耗的影响差异显著,需要根据实际应用场景进行选择。
关键设计:论文的关键设计包括:1) 选择了具有代表性的LLM模型(具体模型未知);2) 实现了多种KV缓存传输路径,包括GPU-GPU、GPU-CPU、GPU-NVMe SSD等;3) 采用了动态电压和频率缩放(DVFS)技术,以探索不同频率下的性能和能耗;4) 使用了标准的性能指标(例如,延迟、吞吐量)和功耗指标(例如,GPU功耗、CPU功耗)进行评估。
🖼️ 关键图片
📊 实验亮点
实验结果表明,解耦服务的性能优势并非总是存在,取决于请求负载和KV缓存传输介质。在某些情况下,共址服务甚至可以获得更好的性能。此外,阶段性独立频率缩放并不一定能带来节能效果,因为解耦服务本身具有更高的能耗。研究还发现,不同的KV缓存传输介质对性能和能耗的影响差异显著,例如,使用NVMe SSD作为KV缓存传输介质可能会导致显著的性能下降。
🎯 应用场景
该研究成果可应用于云服务提供商、AI芯片厂商和LLM开发者,帮助他们更好地理解和优化LLM解耦服务的性能和能耗。通过选择合适的KV缓存传输介质和优化策略,可以降低LLM服务的运营成本,提高服务质量,并促进LLM在资源受限环境中的部署。未来的研究可以进一步探索更高效的KV缓存压缩和传输技术,以及更智能的资源调度策略。
📄 摘要(原文)
Different from traditional Large Language Model (LLM) serving that colocates the prefill and decode stages on the same GPU, disaggregated serving dedicates distinct GPUs to prefill and decode workload. Once the prefill GPU completes its task, the KV cache must be transferred to the decode GPU. While existing works have proposed various KV cache transfer paths across different memory and storage tiers, there remains a lack of systematic benchmarking that compares their performance and energy efficiency. Meanwhile, although optimization techniques such as KV cache reuse and frequency scaling have been utilized for disaggregated serving, their performance and energy implications have not been rigorously benchmarked. In this paper, we fill this research gap by re-evaluating prefill-decode disaggregation under different KV transfer mediums and optimization strategies. Specifically, we include a new colocated serving baseline and evaluate disaggregated setups under different KV cache transfer paths. Through GPU profiling using dynamic voltage and frequency scaling (DVFS), we identify and compare the performance-energy Pareto frontiers across all setups to evaluate the potential energy savings enabled by disaggregation. Our results show that performance benefits from prefill-decode disaggregation are not guaranteed and depend on the request load and KV transfer mediums. In addition, stage-wise independent frequency scaling enabled by disaggregation does not lead to energy saving due to inherently higher energy consumption of disaggregated serving.