An Analysis of Architectural Impact on LLM-based Abstract Visual Reasoning: A Systematic Benchmark on RAVEN-FAIR
作者: Sinan Urgun, Seçkin Arı
分类: cs.AI
发布日期: 2025-11-14
备注: 23 pages, 9 figures
💡 一句话要点
系统性评估LLM在抽象视觉推理中的架构影响,基于RAVEN-FAIR数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 视觉推理 推理架构 RAVEN-FAIR数据集 模型评估
📋 核心要点
- 现有方法在评估LLM视觉推理能力时,缺乏对不同推理架构影响的系统性分析。
- 论文核心在于探索不同推理架构如何影响LLM在抽象视觉推理任务中的表现,并分析模型间的差异。
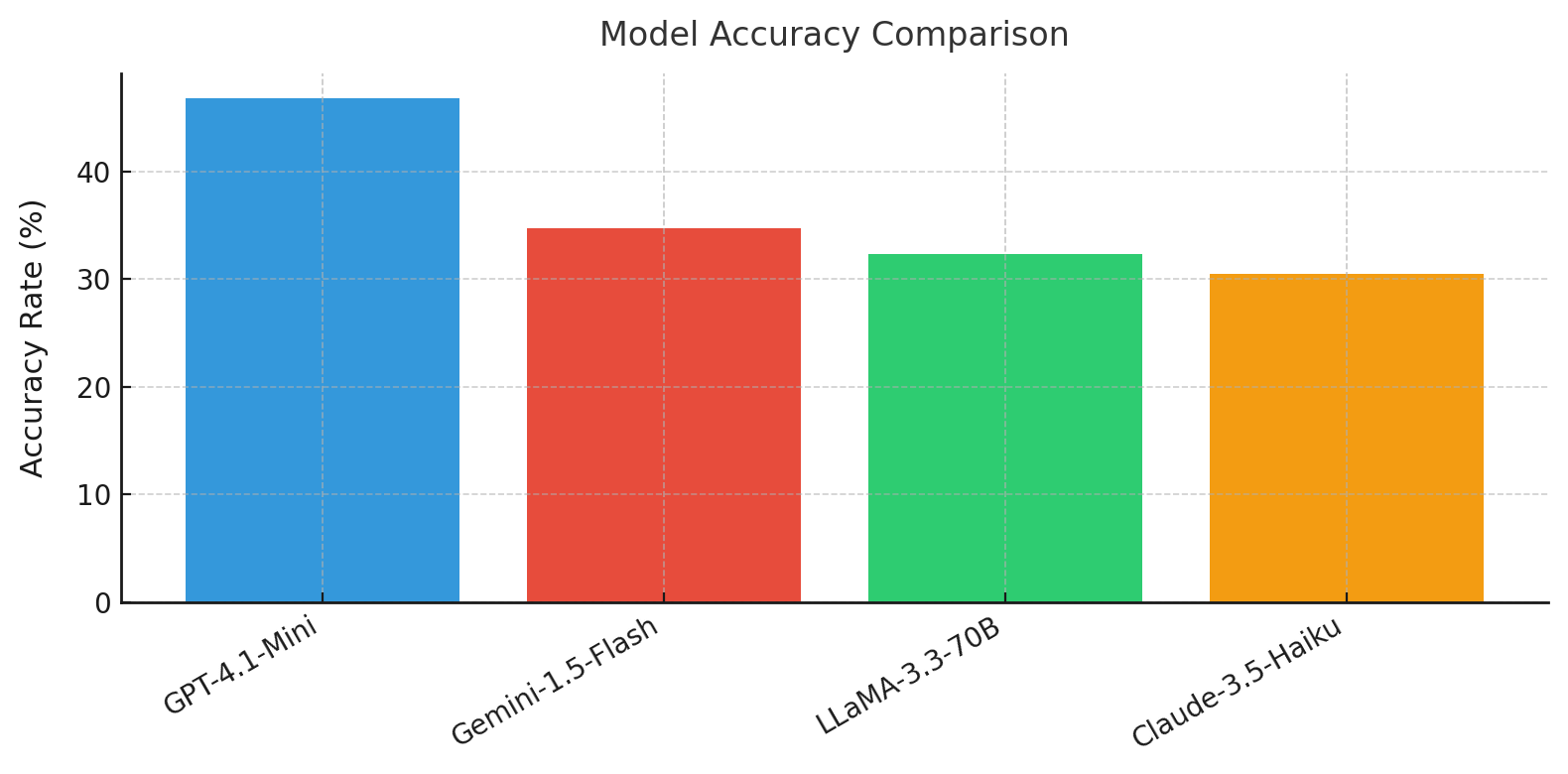
- 实验结果表明,GPT-4.1-Mini在RAVEN-FAIR数据集上表现最佳,且模型对架构设计的敏感性各不相同。
📝 摘要(中文)
本研究旨在系统性地评估大型语言模型(LLM)在抽象视觉推理问题中的性能。我们考察了四种LLM模型(GPT-4.1-Mini、Claude-3.5-Haiku、Gemini-1.5-Flash、Llama-3.3-70b),并结合四种不同的推理架构(单次推理、嵌入控制重复、自我反思和多智能体),在RAVEN-FAIR数据集上进行了实验。通过三阶段过程(JSON提取、LLM推理和工具函数)生成视觉响应,并使用SSIM和LPIPS指标进行评估;分析了思维链得分和错误类型(语义幻觉、数字误解)。结果表明,GPT-4.1-Mini在所有架构中始终获得最高的总体准确率,表明其具有强大的推理能力。虽然多智能体架构偶尔会改变模型间的语义和数字平衡,但这些影响并非普遍有益。相反,每个模型都表现出对架构设计的独特敏感性,强调了推理有效性仍然是模型特定的。响应覆盖率的变化进一步成为混淆因素,使直接的跨架构比较变得复杂。为了估计每种配置的性能上限,我们报告了五次独立运行中的最佳结果,代表最佳情况而非平均结果。这种多运行策略符合最近的建议,这些建议强调单次运行评估是脆弱的,可能导致不可靠的结论。
🔬 方法详解
问题定义:论文旨在解决如何系统性地评估不同推理架构对LLM在抽象视觉推理任务(如RAVEN-FAIR)性能的影响。现有方法通常只关注单一架构或少量模型,缺乏对架构选择的深入分析,难以确定最佳的架构选择策略。此外,单次实验结果的随机性较大,难以得出可靠的结论。
核心思路:论文的核心思路是通过系统性地组合不同的LLM模型和推理架构,并在RAVEN-FAIR数据集上进行大量实验,分析不同架构对模型性能的影响。通过多次独立运行取最佳结果的方式,降低随机性,更可靠地评估模型的性能上限。
技术框架:整体框架包含三个主要阶段:1) JSON提取:将视觉输入转换为LLM可理解的JSON格式;2) LLM推理:使用不同的LLM模型和推理架构进行推理,生成视觉响应;3) 工具函数:将LLM的输出转换为最终的视觉结果。使用了四种推理架构:单次推理、嵌入控制重复、自我反思和多智能体。
关键创新:论文的关键创新在于系统性地研究了不同推理架构对LLM视觉推理性能的影响,并揭示了模型对架构设计的敏感性差异。此外,采用了多次独立运行取最佳结果的评估方法,提高了评估的可靠性。
关键设计:论文使用了SSIM和LPIPS指标来评估视觉响应的质量,并分析了思维链得分和错误类型(语义幻觉、数字误解)。为了估计每种配置的性能上限,进行了五次独立运行,并报告了最佳结果。具体参数设置和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GPT-4.1-Mini在所有架构中始终获得最高的总体准确率,表明其具有强大的推理能力。不同模型对推理架构的敏感性各不相同,多智能体架构的影响并非普遍有益。通过多次独立运行取最佳结果,可以更可靠地评估模型的性能上限。
🎯 应用场景
该研究成果可应用于提升LLM在视觉推理任务中的性能,例如智能图像编辑、视觉问答系统、机器人导航等领域。通过选择合适的推理架构,可以提高LLM的准确性和可靠性,从而实现更智能化的应用。
📄 摘要(原文)
This study aims to systematically evaluate the performance of large language models (LLMs) in abstract visual reasoning problems. We examined four LLM models (GPT-4.1-Mini, Claude-3.5-Haiku, Gemini-1.5-Flash, Llama-3.3-70b) utilizing four different reasoning architectures (single-shot, embedding-controlled repetition, self-reflection, and multi-agent) on the RAVEN-FAIR dataset. Visual responses generated through a three-stage process (JSON extraction, LLM reasoning, and Tool Function) were evaluated using SSIM and LPIPS metrics; Chain-of-Thought scores and error types (semantic hallucination, numeric misperception) were analyzed. Results demonstrate that GPT-4.1-Mini consistently achieved the highest overall accuracy across all architectures, indicating a strong reasoning capability. While the multi-agent architecture occasionally altered semantic and numeric balance across models, these effects were not uniformly beneficial. Instead, each model exhibited distinct sensitivity patterns to architectural design, underscoring that reasoning effectiveness remains model-specific. Variations in response coverage further emerged as a confounding factor that complicates direct cross-architecture comparison. To estimate the upper-bound performance of each configuration, we report the best of five independent runs, representing a best-case scenario rather than an averaged outcome. This multi-run strategy aligns with recent recommendations, which emphasize that single-run evaluations are fragile and may lead to unreliable conclusions.