Flash-Fusion: Enabling Expressive, Low-Latency Queries on IoT Sensor Streams with LLMs
作者: Kausar Patherya, Ashutosh Dhekne, Francisco Romero
分类: cs.DC, cs.AI, cs.DB
发布日期: 2025-11-14
备注: 12 pages, 5 figures. Under review
💡 一句话要点
Flash-Fusion:利用LLM对IoT传感器流进行低延迟、表达丰富的查询
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 物联网数据分析 大型语言模型 边缘计算 查询规划 低延迟 数据缩减 智能城市
📋 核心要点
- 现有方法直接将海量IoT原始数据输入LLM进行分析,面临数据量过大、token成本高昂以及延迟过高等挑战。
- Flash-Fusion通过边缘端的统计汇总减少数据量,并利用云端查询规划构建上下文丰富的提示,从而优化LLM的输入。
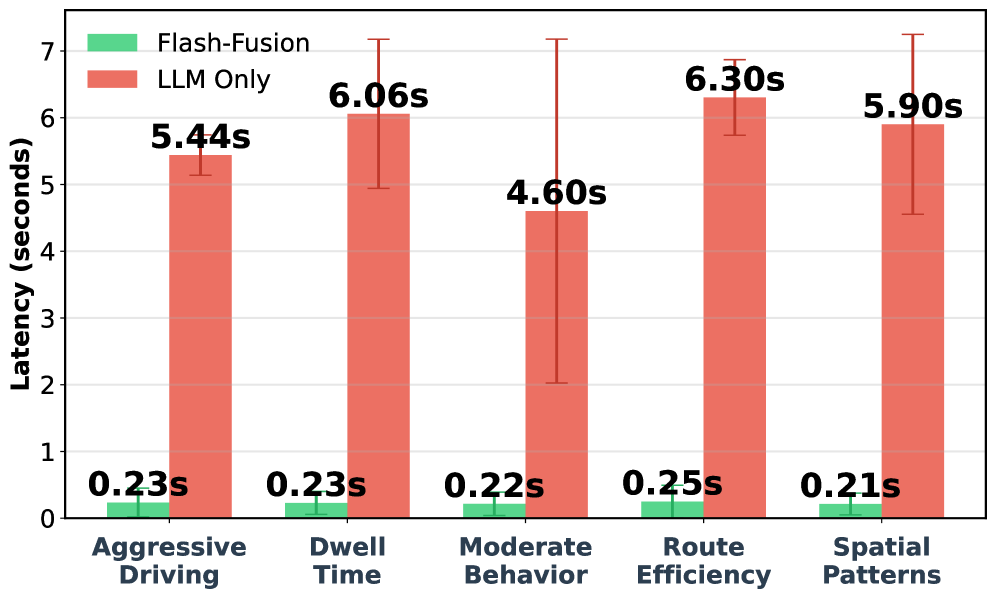
- 实验表明,Flash-Fusion在保持高质量响应的同时,显著降低了延迟(95%)和token使用量及成本(98%)。
📝 摘要(中文)
智能城市和普适的物联网部署激发了人们对交通和城市规划中物联网数据分析的兴趣。同时,大型语言模型为探索物联网数据提供了一种新的接口,特别是通过自然语言。目前,用户在使用LLM处理物联网数据时面临两个主要挑战:(1)数据收集基础设施成本高昂,产生TB级的低级传感器读数,这些读数过于精细,无法直接使用;(2)数据分析速度慢,需要迭代努力和技术专业知识。由于有限的上下文窗口、大规模的token成本以及非交互式延迟,直接将所有物联网遥测数据输入LLM是不切实际的。因此,需要一个系统,首先解析用户的查询以识别分析任务,然后选择相关的数据切片,最后选择正确的表示形式,然后再调用LLM。我们提出了Flash-Fusion,一个端到端的边缘-云系统,旨在减轻用户在物联网数据收集和分析方面的负担。其设计遵循两个原则:(1)基于边缘的统计汇总(实现73.5%的数据缩减)以解决数据量问题,以及(2)基于云的查询规划,该规划对行为数据进行聚类并组装上下文丰富的提示,以解决数据解释问题。我们在大学的巴士车队上部署了Flash-Fusion,并针对将原始数据馈送到最先进的LLM的基线进行了评估。Flash-Fusion实现了95%的延迟降低和98%的token使用量和成本降低,同时保持了高质量的响应。它使安全官员、城市规划者、车队管理者和数据科学家等跨学科人员能够有效地迭代物联网数据,而无需手动查询编写或预处理的负担。
🔬 方法详解
问题定义:论文旨在解决直接使用大型语言模型(LLM)分析物联网(IoT)传感器数据时面临的挑战。现有方法通常需要将大量的原始传感器数据直接输入LLM,这导致了高昂的计算成本、显著的延迟以及有限的上下文理解能力。此外,用户需要具备专业的技术知识才能有效地查询和分析这些数据。
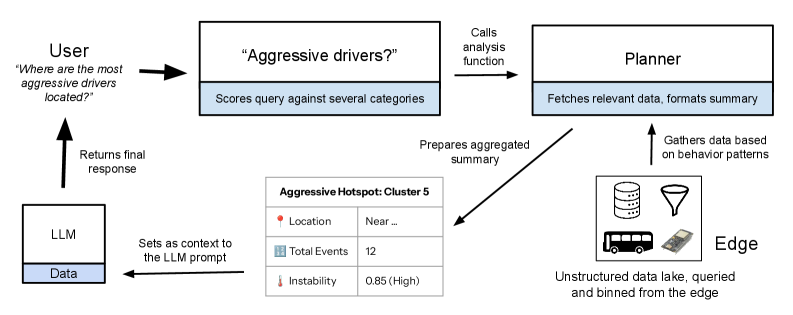
核心思路:Flash-Fusion的核心思路是通过边缘计算和云端查询规划相结合的方式,优化LLM的输入数据和查询方式。边缘计算用于对原始数据进行统计汇总,减少数据量,降低传输和处理成本。云端查询规划则负责理解用户的查询意图,选择相关的数据切片,并构建包含丰富上下文信息的提示,从而提高LLM的分析效率和准确性。
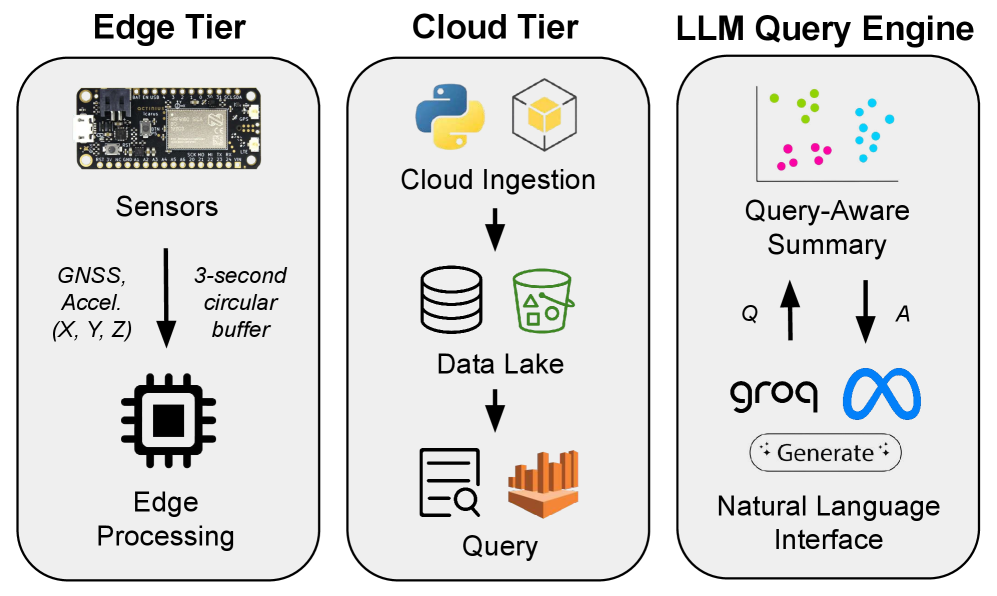
技术框架:Flash-Fusion是一个端到端的边缘-云系统,主要包含以下几个模块:1) 边缘数据汇总:在边缘设备上对传感器数据进行统计汇总,例如计算平均值、最大值、最小值等,从而减少数据量。2) 云端查询规划:接收用户的自然语言查询,并将其解析为可执行的分析任务。3) 数据切片选择:根据查询任务,选择与任务相关的数据切片。4) 提示构建:根据选择的数据切片和查询任务,构建包含丰富上下文信息的提示,用于输入LLM。5) LLM推理:使用LLM对构建的提示进行推理,生成分析结果。
关键创新:Flash-Fusion的关键创新在于其边缘-云协同的设计,以及针对IoT数据分析的提示构建方法。通过边缘计算减少数据量,降低了计算成本和延迟。通过云端查询规划和提示构建,提高了LLM的分析效率和准确性。与现有方法相比,Flash-Fusion能够更有效地利用LLM分析IoT数据,并降低了用户的使用门槛。
关键设计:边缘数据汇总采用统计方法,例如平均值、最大值、最小值等,以减少数据量。云端查询规划使用聚类算法对行为数据进行聚类,并根据聚类结果构建上下文丰富的提示。提示构建的关键在于选择与查询任务相关的数据切片,并将其以自然语言的形式融入提示中。论文中没有明确说明具体的参数设置、损失函数或网络结构,这部分细节可能依赖于具体的LLM和应用场景。
🖼️ 关键图片
📊 实验亮点
Flash-Fusion在大学巴士车队数据集上进行了评估,实验结果表明,与直接将原始数据输入LLM的基线方法相比,Flash-Fusion实现了95%的延迟降低和98%的token使用量和成本降低,同时保持了高质量的响应。这表明Flash-Fusion能够显著提高IoT数据分析的效率和降低成本。
🎯 应用场景
Flash-Fusion可应用于智能城市、交通运输、环境监测等领域。例如,它可以帮助城市规划者分析交通流量数据,优化交通路线;帮助车队管理者监控车辆运行状态,提高运营效率;帮助环境监测人员分析空气质量数据,预测污染事件。该研究降低了LLM应用于IoT数据分析的门槛,促进了跨学科人员对IoT数据的有效利用。
📄 摘要(原文)
Smart cities and pervasive IoT deployments have generated interest in IoT data analysis across transportation and urban planning. At the same time, Large Language Models offer a new interface for exploring IoT data - particularly through natural language. Users today face two key challenges when working with IoT data using LLMs: (1) data collection infrastructure is expensive, producing terabytes of low-level sensor readings that are too granular for direct use, and (2) data analysis is slow, requiring iterative effort and technical expertise. Directly feeding all IoT telemetry to LLMs is impractical due to finite context windows, prohibitive token costs at scale, and non-interactive latencies. What is missing is a system that first parses a user's query to identify the analytical task, then selects the relevant data slices, and finally chooses the right representation before invoking an LLM. We present Flash-Fusion, an end-to-end edge-cloud system that reduces the IoT data collection and analysis burden on users. Two principles guide its design: (1) edge-based statistical summarization (achieving 73.5% data reduction) to address data volume, and (2) cloud-based query planning that clusters behavioral data and assembles context-rich prompts to address data interpretation. We deploy Flash-Fusion on a university bus fleet and evaluate it against a baseline that feeds raw data to a state-of-the-art LLM. Flash-Fusion achieves a 95% latency reduction and 98% decrease in token usage and cost while maintaining high-quality responses. It enables personas across disciplines - safety officers, urban planners, fleet managers, and data scientists - to efficiently iterate over IoT data without the burden of manual query authoring or preprocessing.