Differences in the Moral Foundations of Large Language Models
作者: Peter Kirgis
分类: cs.CY, cs.AI
发布日期: 2025-11-14
💡 一句话要点
利用道德基础理论分析大型语言模型伦理判断差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 道德基础理论 伦理对齐 价值判断 道德心理学
📋 核心要点
- 大型语言模型伦理判断的本质尚不明确,现有对齐研究未能充分利用道德心理学的理论指导。
- 该研究采用道德基础理论(MFT)分析LLM的价值判断,揭示不同模型在道德基础上的差异。
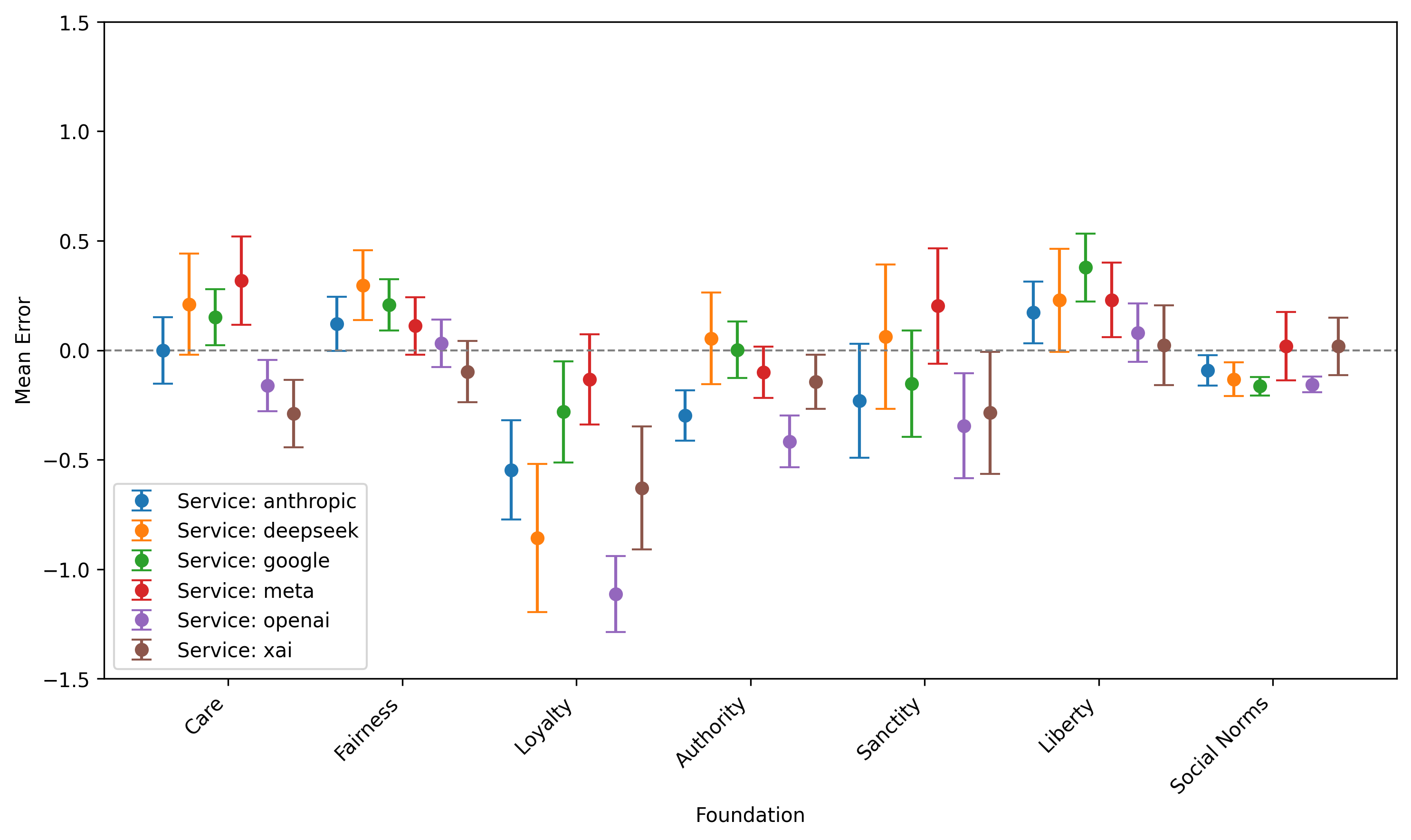
- 实验结果表明,不同LLM依赖不同的道德基础,且与人类基线存在差异,这种差异随模型能力增强而增大。
📝 摘要(中文)
大型语言模型越来越多地应用于政治、商业和教育等关键领域,但其规范伦理判断的本质仍然不明确。迄今为止,对齐研究尚未充分利用道德心理学领域的视角和见解来指导前沿模型的训练和评估。本文使用Jonathan Haidt颇具影响力的道德基础理论(MFT),对来自大多数主要模型提供商的各种模型进行了一项综合实验,以引出LLM的不同价值判断。使用多种描述性统计方法,记录了相对于原始调查中的人类基线,大型语言模型响应的偏差和方差。结果表明,模型依赖于彼此以及与具有全国代表性的人类基线不同的道德基础,并且这些差异随着模型能力的提高而增加。这项工作旨在促进使用MFT对LLM的进一步分析,包括对开源模型进行微调,以及政策制定者对道德基础对于LLM对齐的重要性的更多审议。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在伦理判断方面存在的偏差和差异问题。现有方法缺乏对LLM道德基础的深入理解,难以有效评估和对齐模型的伦理价值观。这导致LLM在关键领域的应用可能产生不可预测的伦理风险。
核心思路:论文的核心思路是借鉴道德心理学中的道德基础理论(MFT),将LLM的伦理判断分解为不同的道德维度,从而更细粒度地分析和比较不同模型之间的伦理差异。通过对比LLM与人类基线在不同道德维度上的表现,揭示LLM伦理价值观的偏差。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择Jonathan Haidt的道德基础理论(MFT)作为伦理分析的框架。2) 构建基于MFT的合成实验,设计一系列问题以引出LLM在不同道德维度上的价值判断。3) 选择来自不同提供商的多个大型语言模型作为实验对象。4) 使用描述性统计方法分析LLM的响应,计算其相对于人类基线的偏差和方差。
关键创新:该研究的关键创新在于将道德心理学理论引入LLM的伦理分析,提供了一种更细粒度、更系统化的方法来评估和比较LLM的伦理价值观。与以往主要关注有害内容检测的研究不同,该研究关注LLM内在的道德偏好和价值观差异。
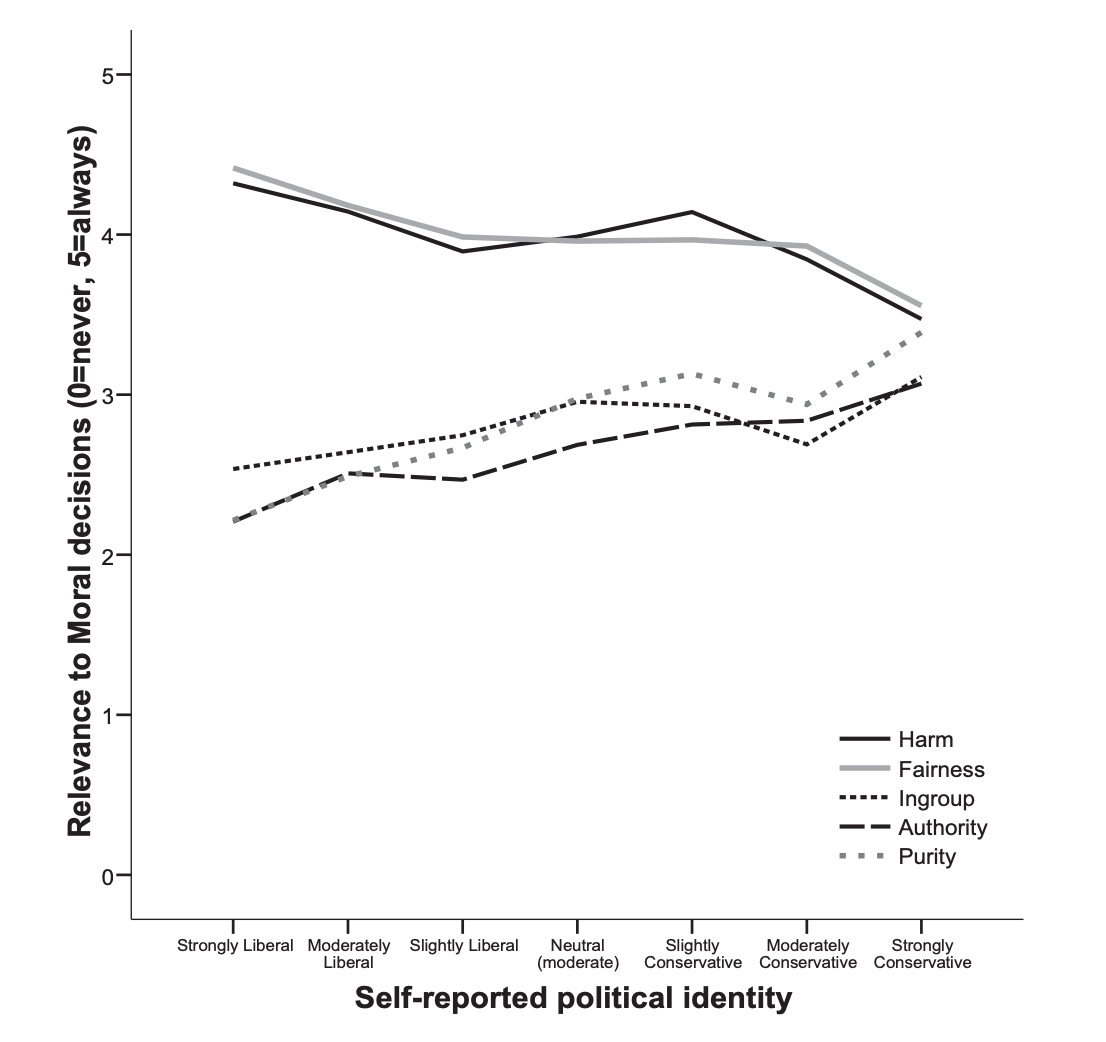
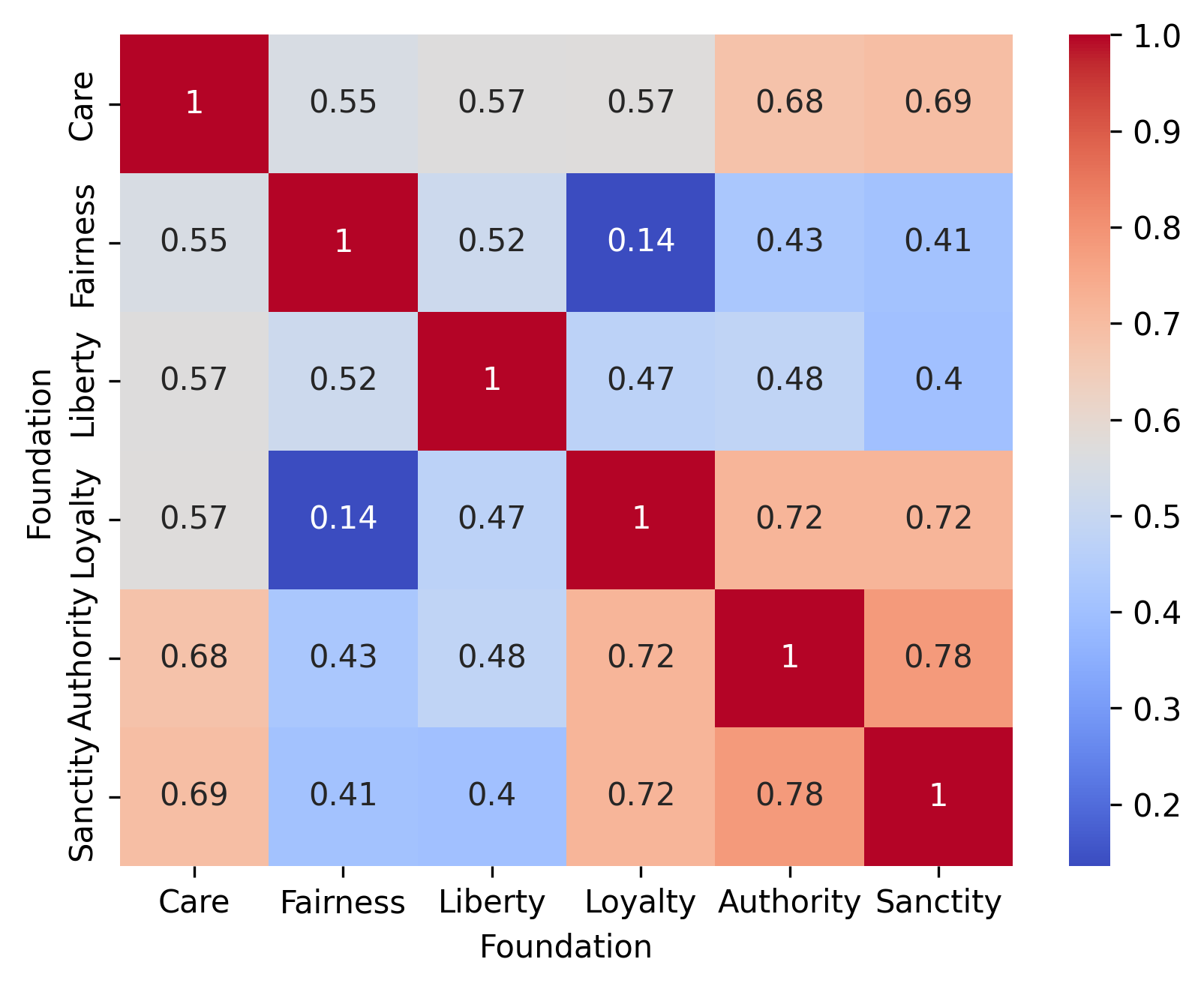
关键设计:实验设计基于MFT,包含五个道德维度:关怀/伤害、公平/欺骗、忠诚/背叛、权威/颠覆、圣洁/堕落。针对每个维度设计多个问题,以引出LLM的价值判断。使用Likert量表收集LLM的响应,并计算每个模型在不同道德维度上的平均得分。使用方差分析和t检验等统计方法比较不同模型之间的差异,以及模型与人类基线之间的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同LLM在道德基础上的表现存在显著差异,且与人类基线存在偏差。随着模型能力的提高,这种差异反而增大。例如,某些模型可能更倾向于强调忠诚和权威,而另一些模型可能更注重关怀和公平。这些发现强调了对LLM进行伦理评估和对齐的重要性。
🎯 应用场景
该研究成果可应用于LLM的伦理风险评估、对齐和治理。通过了解LLM在不同道德维度上的偏好,可以针对性地进行微调,使其更符合人类的伦理价值观。此外,该研究可以为政策制定者提供参考,帮助他们制定更合理的LLM监管政策,降低LLM在关键领域的应用风险。
📄 摘要(原文)
Large language models are increasingly being used in critical domains of politics, business, and education, but the nature of their normative ethical judgment remains opaque. Alignment research has, to date, not sufficiently utilized perspectives and insights from the field of moral psychology to inform training and evaluation of frontier models. I perform a synthetic experiment on a wide range of models from most major model providers using Jonathan Haidt's influential moral foundations theory (MFT) to elicit diverse value judgments from LLMs. Using multiple descriptive statistical approaches, I document the bias and variance of large language model responses relative to a human baseline in the original survey. My results suggest that models rely on different moral foundations from one another and from a nationally representative human baseline, and these differences increase as model capabilities increase. This work seeks to spur further analysis of LLMs using MFT, including finetuning of open-source models, and greater deliberation by policymakers on the importance of moral foundations for LLM alignment.