MarsRL: Advancing Multi-Agent Reasoning System via Reinforcement Learning with Agentic Pipeline Parallelism
作者: Shulin Liu, Dong Du, Tao Yang, Yang Li, Boyu Qiu
分类: cs.AI
发布日期: 2025-11-14
备注: 10 pages
💡 一句话要点
MarsRL:通过强化学习与Agentic流水线并行提升多智能体推理系统
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 强化学习 流水线并行 大型语言模型 推理系统 开源模型 奖励机制
📋 核心要点
- 现有大型语言模型推理深度受限,多智能体系统虽有潜力,但在开源模型上泛化性不足。
- MarsRL提出agentic流水线并行强化学习框架,联合优化多智能体,提升开源模型推理能力。
- 实验表明,MarsRL显著提升了Qwen3模型在AIME2025和BeyondAIME数据集上的准确率,超越了更大规模的模型。
📝 摘要(中文)
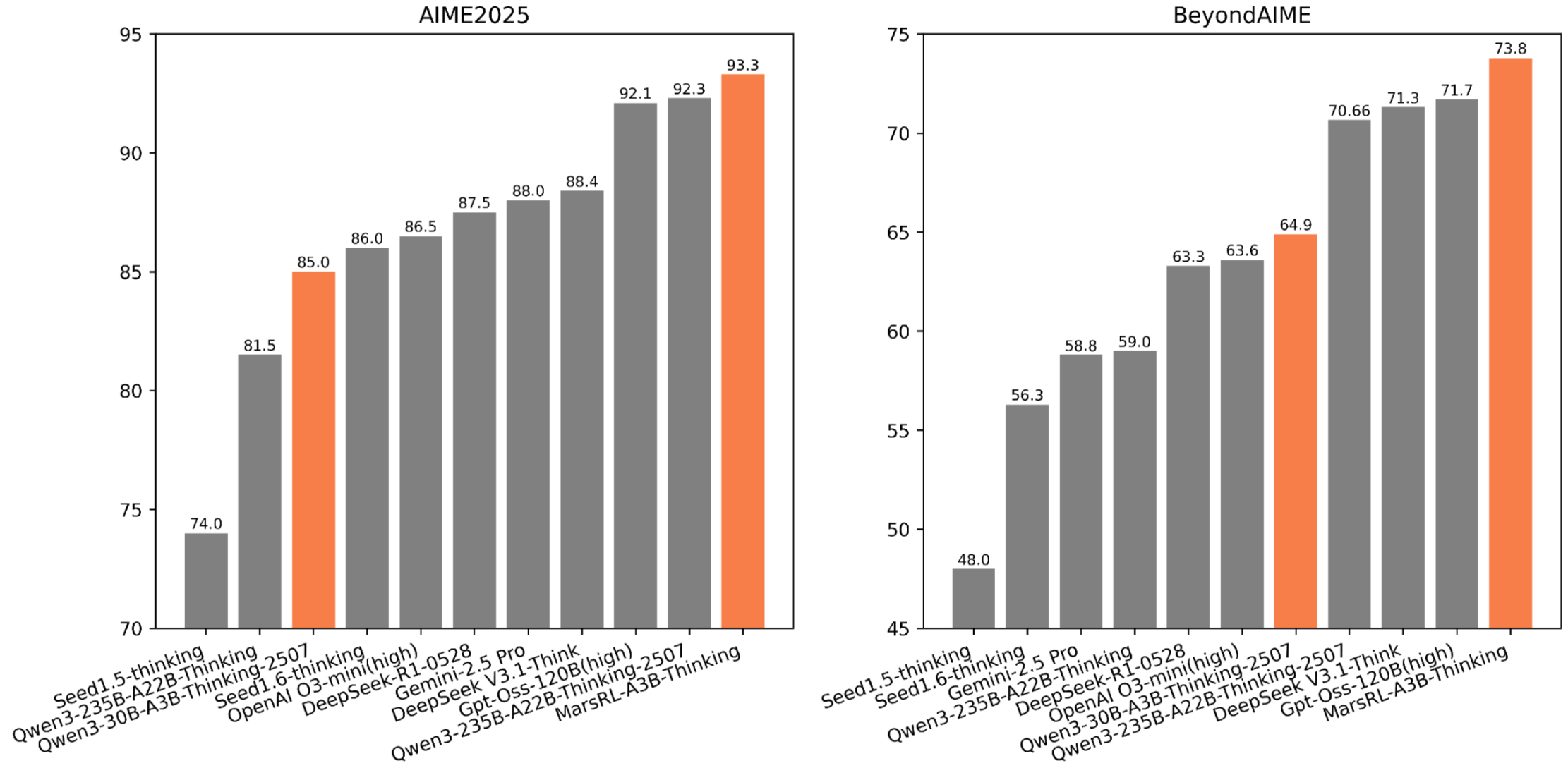
大型语言模型(LLMs)的最新进展得益于具有可验证奖励的强化学习(RLVR)和测试时扩展。然而,LLM有限的输出长度限制了单次推理过程所能达到的推理深度。多智能体推理系统提供了一种有前景的替代方案,它采用包括Solver、Verifier和Corrector在内的多个智能体来迭代地改进解决方案。虽然在Gemini 2.5 Pro等闭源模型中有效,但由于评论和纠正能力不足,它们难以推广到开源模型。为了解决这个问题,我们提出了一种新的强化学习框架MarsRL,它具有agentic流水线并行性,旨在联合优化系统中的所有智能体。MarsRL引入了特定于智能体的奖励机制,以减轻奖励噪声,并采用受流水线启发的训练来提高处理长轨迹的效率。应用于Qwen3-30B-A3B-Thinking-2507,MarsRL将AIME2025的准确率从86.5%提高到93.3%,将BeyondAIME的准确率从64.9%提高到73.8%,甚至超过了Qwen3-235B-A22B-Thinking-2507。这些发现突出了MarsRL在推进多智能体推理系统和扩大其在各种推理任务中的适用性方面的潜力。
🔬 方法详解
问题定义:论文旨在解决开源大型语言模型在多智能体推理系统中表现不佳的问题。现有方法,如直接应用闭源模型训练的多智能体系统,在开源模型上泛化能力弱,主要原因是开源模型的评论(critic)和纠正(correction)能力不足,导致推理过程容易出错。
核心思路:论文的核心思路是通过强化学习(RL)来联合优化多智能体系统中的所有智能体,使其能够更好地适应开源模型。通过设计agentic流水线并行训练机制,提高训练效率,并减轻奖励噪声,从而提升整体推理性能。
技术框架:MarsRL框架包含多个智能体,如Solver、Verifier和Corrector,它们通过流水线的方式协同工作。Solver负责生成解决方案,Verifier负责评估解决方案的质量,Corrector负责根据评估结果对解决方案进行修正。整个框架通过强化学习进行训练,目标是最大化整体推理性能。训练过程采用agentic流水线并行,即每个智能体并行地进行训练,并通过共享信息来协同优化。
关键创新:MarsRL的关键创新在于agentic流水线并行训练机制和agent-specific的奖励机制。Agentic流水线并行训练机制通过并行训练多个智能体,提高了训练效率,并能够更好地处理长轨迹。Agent-specific的奖励机制则针对每个智能体设计不同的奖励函数,从而减轻奖励噪声,提高训练的稳定性。
关键设计:在奖励函数设计上,针对Solver、Verifier和Corrector分别设计了不同的奖励信号,例如Solver的奖励可以是解决方案的正确率,Verifier的奖励可以是评估的准确率,Corrector的奖励可以是修正后的解决方案的质量提升。在训练过程中,采用了PPO(Proximal Policy Optimization)算法进行策略优化。此外,还使用了经验回放(Experience Replay)技术来提高样本利用率。
🖼️ 关键图片


📊 实验亮点
MarsRL在Qwen3-30B-A3B-Thinking-2507模型上取得了显著的性能提升。在AIME2025数据集上,准确率从86.5%提高到93.3%,提升了6.8个百分点;在BeyondAIME数据集上,准确率从64.9%提高到73.8%,提升了8.9个百分点。值得注意的是,MarsRL甚至超越了更大规模的Qwen3-235B-A22B-Thinking-2507模型。
🎯 应用场景
MarsRL具有广泛的应用前景,可以应用于各种需要复杂推理的任务,如数学问题求解、代码生成、知识图谱推理等。该研究的实际价值在于提升了开源大型语言模型在多智能体推理系统中的性能,降低了使用高性能推理系统的门槛。未来,MarsRL可以进一步扩展到其他领域,如机器人控制、自动驾驶等,实现更智能化的决策和控制。
📄 摘要(原文)
Recent progress in large language models (LLMs) has been propelled by reinforcement learning with verifiable rewards (RLVR) and test-time scaling. However, the limited output length of LLMs constrains the depth of reasoning attainable in a single inference process. Multi-agent reasoning systems offer a promising alternative by employing multiple agents including Solver, Verifier, and Corrector, to iteratively refine solutions. While effective in closed-source models like Gemini 2.5 Pro, they struggle to generalize to open-source models due to insufficient critic and correction capabilities. To address this, we propose MarsRL, a novel reinforcement learning framework with agentic pipeline parallelism, designed to jointly optimize all agents in the system. MarsRL introduces agent-specific reward mechanisms to mitigate reward noise and employs pipeline-inspired training to enhance efficiency in handling long trajectories. Applied to Qwen3-30B-A3B-Thinking-2507, MarsRL improves AIME2025 accuracy from 86.5% to 93.3% and BeyondAIME from 64.9% to 73.8%, even surpassing Qwen3-235B-A22B-Thinking-2507. These findings highlight the potential of MarsRL to advance multi-agent reasoning systems and broaden their applicability across diverse reasoning tasks.