Large-scale modality-invariant foundation models for brain MRI analysis: Application to lesion segmentation
作者: Petros Koutsouvelis, Matej Gazda, Leroy Volmer, Sina Amirrajab, Kamil Barbierik, Branislav Setlak, Jakub Gazda, Peter Drotar
分类: eess.IV, cs.AI, cs.CV, cs.LG
发布日期: 2025-11-14 (更新: 2026-01-14)
备注: Submitted to IEEE ISBI 2026
💡 一句话要点
提出大规模模态不变脑MRI分析基础模型,应用于病灶分割
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑MRI分析 病灶分割 自监督学习 模态不变表征 深度学习
📋 核心要点
- 现有自监督学习框架在处理多模态MRI信息方面存在不足,无法充分利用脑MRI数据的多模态特性。
- 提出一种模态不变的表征学习方法,旨在学习跨模态的通用解剖先验知识,提升神经影像任务的性能。
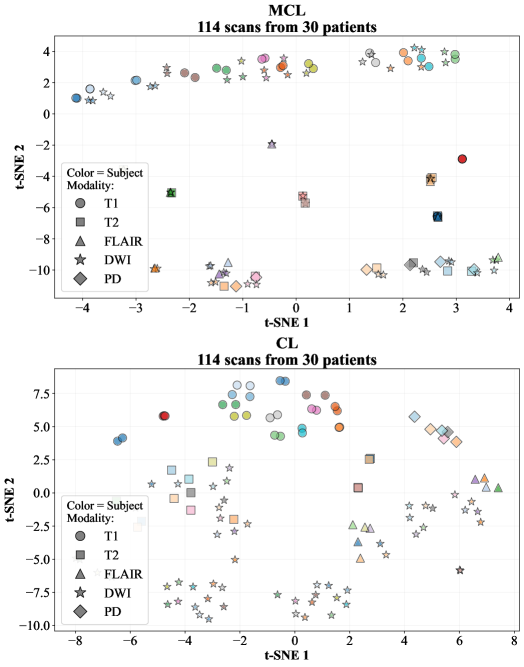
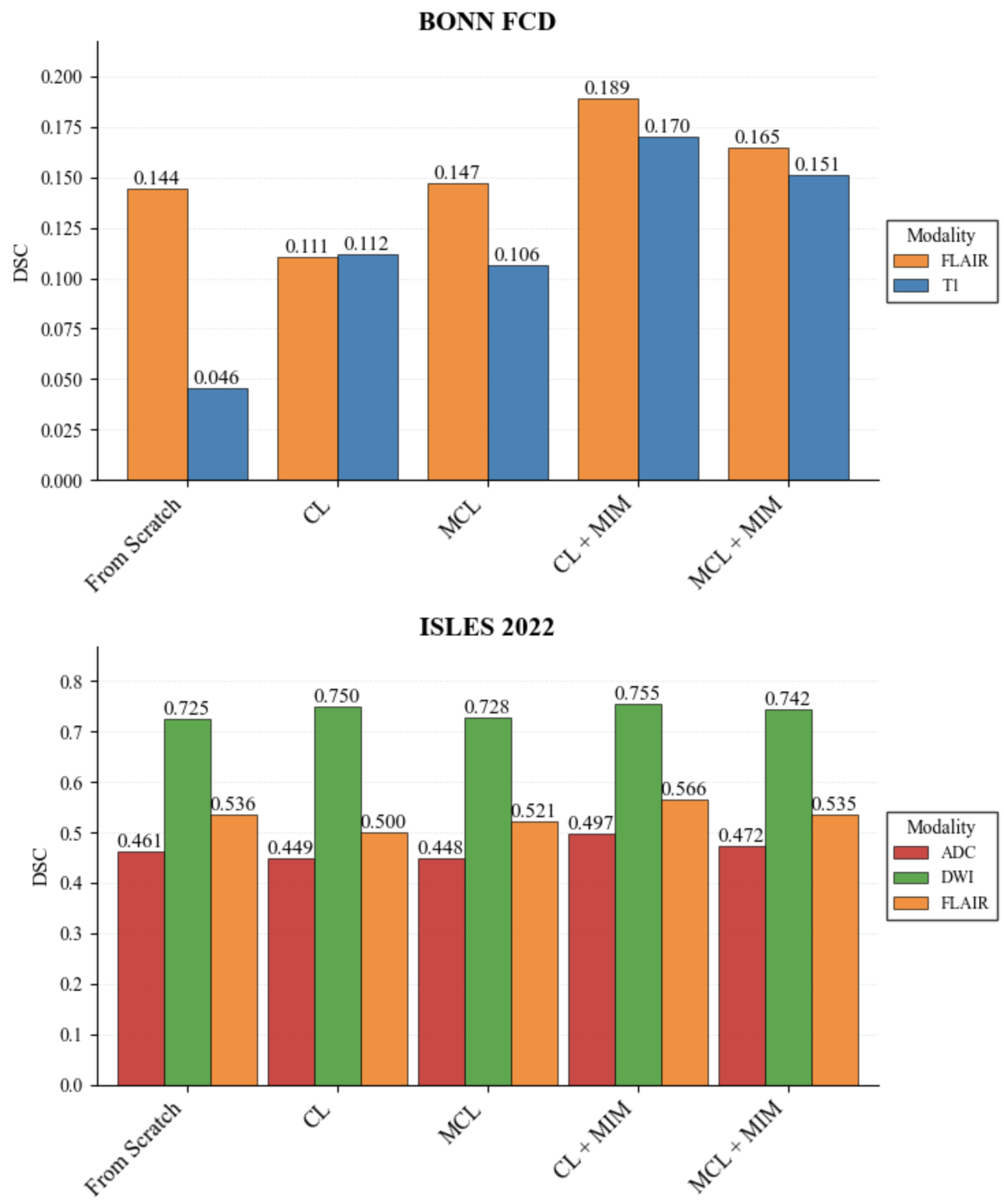
- 实验结果表明,病灶分割任务更依赖于模态特定的细粒度特征,而非跨模态的通用表征。
📝 摘要(中文)
计算机视觉领域正经历向大规模基础模型预训练的范式转变,这种转变通过自监督学习(SSL)实现。本文利用大量未标记的脑MRI数据,此类模型可以学习解剖先验知识,从而提高各种神经影像任务中的少样本性能。然而,大多数SSL框架都是为自然图像量身定制的,它们在捕获多模态MRI信息方面的适应性仍未得到充分探索。本文提出了一种模态不变的表征学习设置,并评估了其在大规模预训练后在卒中和癫痫病灶分割中的有效性。实验结果表明,尽管跨模态对齐成功,但病灶分割主要受益于保留细粒度的模态特定特征。模型检查点和代码已公开。
🔬 方法详解
问题定义:论文旨在解决脑MRI图像病灶分割问题,现有方法难以有效利用大规模未标注的多模态MRI数据,无法充分学习解剖结构先验知识,导致在少样本情况下分割精度不高。现有自监督学习方法主要针对自然图像设计,难以直接应用于多模态MRI数据。
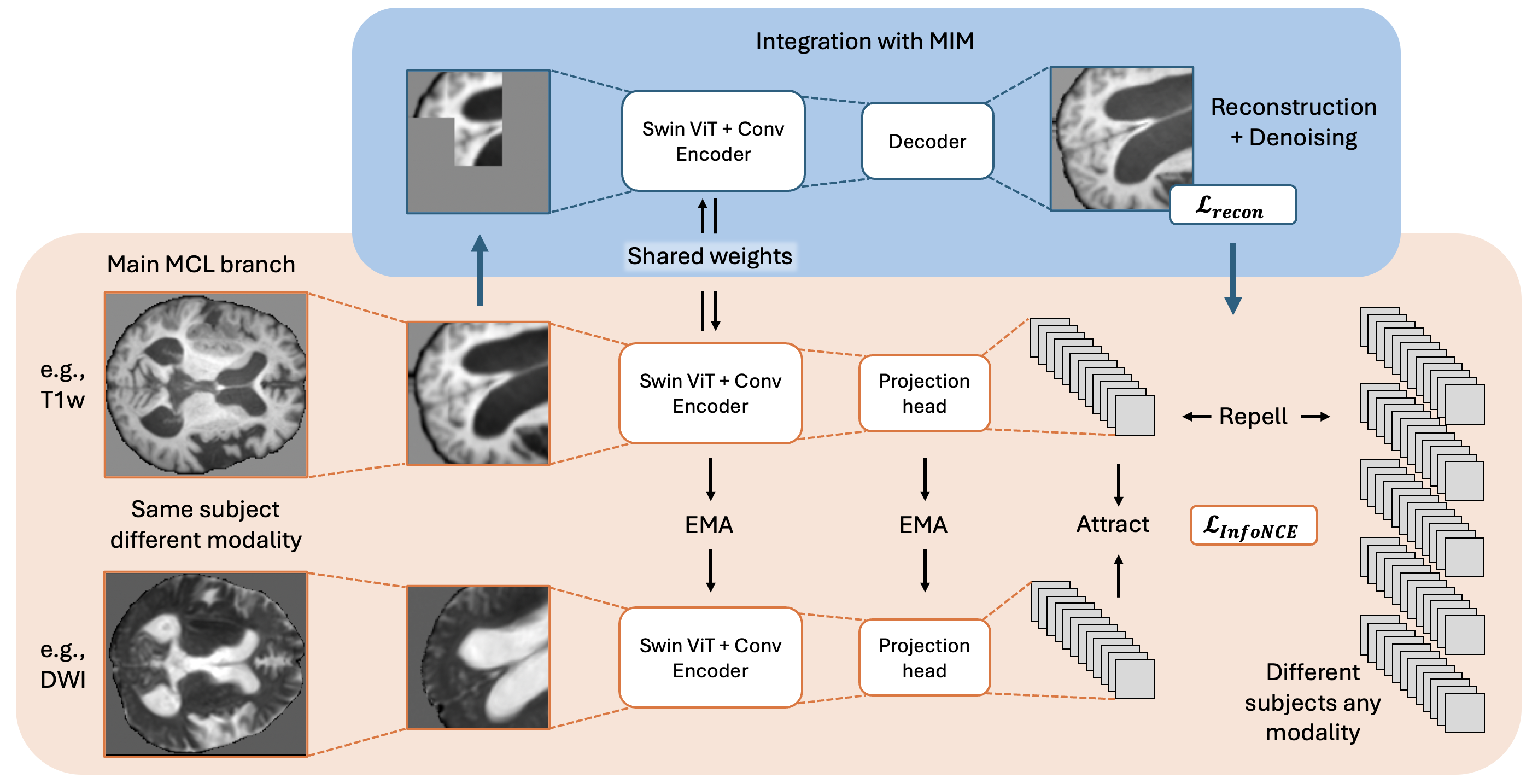
核心思路:论文的核心思路是设计一种模态不变的表征学习框架,通过自监督学习,使模型能够从大规模未标注的脑MRI数据中学习到通用的解剖结构先验知识。同时,考虑到病灶分割任务对模态特定特征的依赖性,在模型设计中保留了对细粒度模态特征的提取能力。
技术框架:整体框架包含预训练和微调两个阶段。在预训练阶段,模型使用大规模未标注的脑MRI数据进行自监督学习,学习模态不变的表征。在微调阶段,使用少量标注数据对模型进行微调,以适应特定的病灶分割任务。模型主体采用Transformer架构,并针对多模态MRI数据进行了改进。
关键创新:论文的关键创新在于提出了一种模态不变的表征学习方法,该方法能够有效地从多模态MRI数据中学习到通用的解剖结构先验知识。同时,论文强调了模态特定特征在病灶分割任务中的重要性,并在模型设计中保留了对这些特征的提取能力。
关键设计:论文采用对比学习作为自监督学习的目标函数,通过最大化同一解剖结构的跨模态表征之间的相似性,来学习模态不变的表征。同时,为了保留模态特定特征,模型在Transformer编码器的不同层级提取特征,并将这些特征用于下游任务。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,预训练模型在卒中和癫痫病灶分割任务中取得了良好的性能。尽管跨模态对齐成功,但实验结果强调了保留细粒度模态特定特征的重要性。模型和代码已公开,方便其他研究者复现和改进。
🎯 应用场景
该研究成果可应用于多种脑部疾病的诊断和治疗,例如卒中、癫痫、阿尔茨海默病等。通过提高病灶分割的精度和效率,可以辅助医生进行更准确的诊断和治疗方案制定。此外,该研究提出的模态不变表征学习方法也可以推广到其他医学影像领域,例如CT、PET等。
📄 摘要(原文)
The field of computer vision is undergoing a paradigm shift toward large-scale foundation model pre-training via self-supervised learning (SSL). Leveraging large volumes of unlabeled brain MRI data, such models can learn anatomical priors that improve few-shot performance in diverse neuroimaging tasks. However, most SSL frameworks are tailored to natural images, and their adaptation to capture multi-modal MRI information remains underexplored. This work proposes a modality-invariant representation learning setup and evaluates its effectiveness in stroke and epilepsy lesion segmentation, following large-scale pre-training. Experimental results suggest that despite successful cross-modality alignment, lesion segmentation primarily benefits from preserving fine-grained modality-specific features. Model checkpoints and code are made publicly available.