Multi-agent Undercover Gaming: Hallucination Removal via Counterfactual Test for Multimodal Reasoning
作者: Dayong Liang, Xiao-Yong Wei, Changmeng Zheng
分类: cs.AI, cs.CL, cs.MA, cs.MM
发布日期: 2025-11-14
备注: Accepted by AAAI 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出多智能体卧底游戏(MUG)协议,通过对抗测试消除多模态推理中的幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 幻觉消除 对抗测试 多智能体系统 语言模型
📋 核心要点
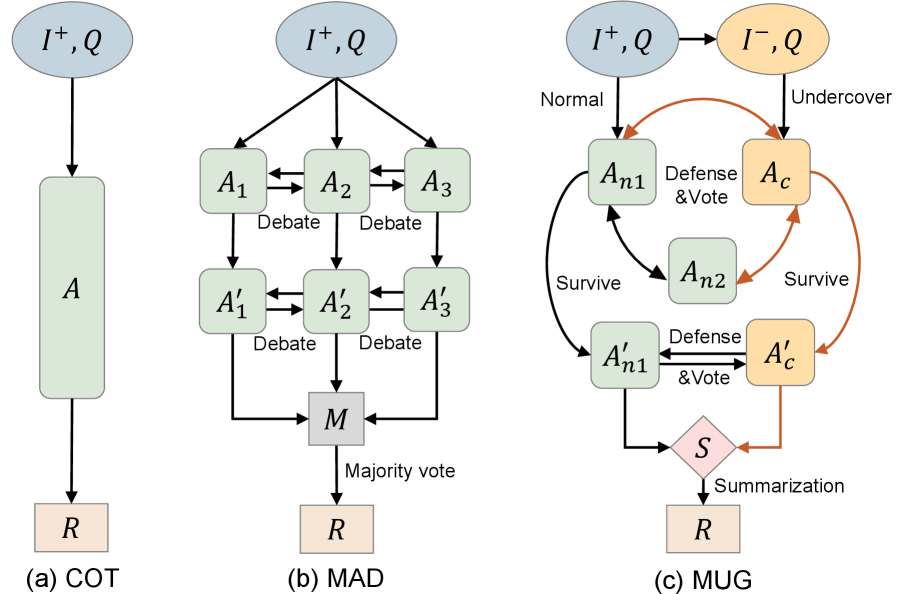
- 现有MAD方法依赖所有智能体理性的假设,但智能体本身可能产生幻觉,导致推理不可靠。
- MUG协议借鉴“谁是卧底”游戏,通过对抗测试识别产生幻觉的智能体,提升推理可靠性。
- MUG通过对抗测试、动态证据和主动推理,在事实验证、交叉证据推理和智能体交互方面改进MAD。
📝 摘要(中文)
幻觉现象仍然是大型语言模型(LLMs)推理能力的主要障碍。多智能体辩论(MAD)范式通过促进多个智能体之间的共识来提高可靠性,但它依赖于一个不切实际的假设,即所有辩论者都是理性和反思的,而当智能体本身容易产生幻觉时,这个条件可能不成立。为了解决这个问题,我们引入了多智能体卧底游戏(MUG)协议,其灵感来自“谁是卧底?”等社交推理游戏。MUG将MAD重新定义为一个通过多模态对抗测试来检测“卧底”智能体(那些遭受幻觉的智能体)的过程。具体来说,我们修改参考图像以引入对抗性证据,并观察智能体是否能够准确识别这些变化,从而为识别产生幻觉的智能体提供ground-truth,并实现稳健的、众包驱动的多模态推理。MUG从三个关键维度推进了MAD协议:(1)通过对抗测试实现超越统计共识的事实验证;(2)通过动态修改的证据源而不是依赖静态输入来引入交叉证据推理;(3)培养主动推理,智能体参与探测性讨论,而不是被动地回答问题。总而言之,这些创新为LLM中的多模态推理提供了一个更可靠和有效的框架。
🔬 方法详解
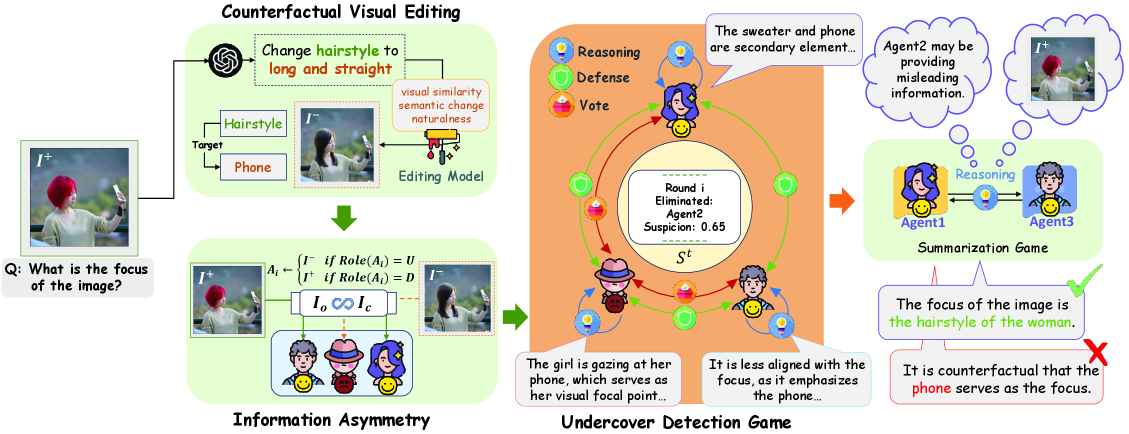
问题定义:论文旨在解决大型语言模型在多模态推理中存在的幻觉问题。现有的多智能体辩论(MAD)方法虽然试图通过共识来提高推理的可靠性,但其假设所有参与辩论的智能体都是理性的,这在实际应用中往往不成立,因为智能体本身也可能产生幻觉,从而导致错误的共识和不可靠的推理结果。
核心思路:论文的核心思路是将多智能体辩论过程重新定义为一个“卧底”识别游戏。通过引入对抗性证据,即对原始图像进行修改,然后观察智能体是否能够准确识别这些修改,从而判断哪些智能体产生了幻觉(即“卧底”)。这种方式不再依赖于智能体之间的简单共识,而是通过对抗测试来验证智能体的推理能力。
技术框架:MUG协议的整体框架包含以下几个主要阶段:1) 图像修改:对参考图像进行修改,引入对抗性证据。2) 智能体辩论:多个智能体基于原始图像和修改后的图像进行辩论,尝试达成共识。3) 幻觉检测:通过观察智能体对图像修改的识别情况,判断哪些智能体产生了幻觉。4) 推理结果修正:根据幻觉检测的结果,对智能体的推理结果进行修正,从而提高整体推理的可靠性。
关键创新:MUG协议的关键创新在于:1) 对抗测试:通过引入对抗性证据,实现了超越统计共识的事实验证。2) 动态证据:通过动态修改证据源,引入了交叉证据推理。3) 主动推理:鼓励智能体参与探测性讨论,而不是被动地回答问题。这些创新使得MUG协议能够更有效地检测和消除多模态推理中的幻觉。
关键设计:MUG协议的关键设计包括:1) 对抗性证据的生成方法:如何生成有效的对抗性证据,使得智能体能够准确识别,但又不会过于明显。2) 智能体辩论的策略:如何设计智能体之间的辩论策略,使得智能体能够充分表达自己的观点,并相互质疑。3) 幻觉检测的指标:如何设计有效的指标来衡量智能体是否产生了幻觉,例如,识别对抗性证据的准确率。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了MUG协议的有效性。实验结果表明,MUG协议能够有效地检测和消除多模态推理中的幻觉,显著提高了推理的准确性和可靠性。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
MUG协议可应用于各种需要多模态推理的场景,例如图像描述生成、视觉问答、机器人导航等。通过消除幻觉,可以提高这些应用的安全性和可靠性。未来,该方法可以扩展到其他模态,例如文本和语音,以实现更全面的多模态推理。
📄 摘要(原文)
Hallucination continues to pose a major obstacle in the reasoning capabilities of large language models (LLMs). Although the Multi-Agent Debate (MAD) paradigm offers a promising solution by promoting consensus among multiple agents to enhance reliability, it relies on the unrealistic assumption that all debaters are rational and reflective, which is a condition that may not hold when agents themselves are prone to hallucinations. To address this gap, we introduce the Multi-agent Undercover Gaming (MUG) protocol, inspired by social deduction games like "Who is Undercover?". MUG reframes MAD as a process of detecting "undercover" agents (those suffering from hallucinations) by employing multimodal counterfactual tests. Specifically, we modify reference images to introduce counterfactual evidence and observe whether agents can accurately identify these changes, providing ground-truth for identifying hallucinating agents and enabling robust, crowd-powered multimodal reasoning. MUG advances MAD protocols along three key dimensions: (1) enabling factual verification beyond statistical consensus through counterfactual testing; (2) introducing cross-evidence reasoning via dynamically modified evidence sources instead of relying on static inputs; and (3) fostering active reasoning, where agents engage in probing discussions rather than passively answering questions. Collectively, these innovations offer a more reliable and effective framework for multimodal reasoning in LLMs. The source code can be accessed at https://github.com/YongLD/MUG.git.