GGBench: A Geometric Generative Reasoning Benchmark for Unified Multimodal Models
作者: Jingxuan Wei, Caijun Jia, Xi Bai, Xinglong Xu, Siyuan Li, Linzhuang Sun, Bihui Yu, Conghui He, Lijun Wu, Cheng Tan
分类: cs.AI
发布日期: 2025-11-14 (更新: 2026-01-14)
备注: 35 pages, 22 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出GGBench:一个用于统一多模态模型几何生成推理的基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 生成式推理 几何构造 基准测试 统一多模态模型
📋 核心要点
- 现有基准测试主要关注判别理解或无约束图像生成,缺乏对多模态模型生成推理能力的综合评估。
- GGBench通过几何构造任务,融合语言理解和精确视觉生成,系统性地评估模型的生成推理能力。
- GGBench提供了一个全面的框架,可以诊断模型理解、推理和主动构建解决方案的能力,为智能系统设定更高标准。
📝 摘要(中文)
统一多模态模型(UMMs)的出现标志着人工智能领域从被动感知到主动跨模态生成的一种范式转变。尽管它们具有前所未有的信息综合能力,但在评估方面仍然存在一个关键缺口:现有的基准测试主要评估判别理解或无约束图像生成,而未能衡量生成推理的综合认知过程。为了弥合这一差距,我们提出几何构造提供了一个理想的测试平台,因为它本身需要语言理解和精确视觉生成的融合。我们引入了GGBench,这是一个专门为评估几何生成推理而设计的基准。它提供了一个全面的框架,用于系统地诊断模型不仅理解和推理,而且主动构建解决方案的能力,从而为下一代智能系统设定了更严格的标准。
🔬 方法详解
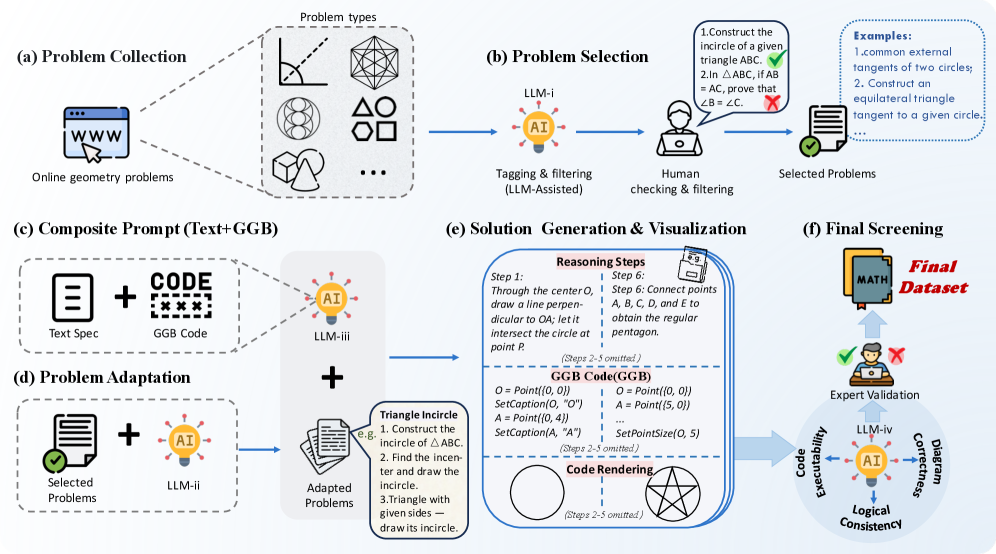
问题定义:现有统一多模态模型在生成式推理方面缺乏有效的评估基准。现有基准侧重于判别式理解或无约束图像生成,无法充分测试模型在理解语言描述后,精确生成对应几何图形的能力。因此,需要一个能够综合评估语言理解和视觉生成能力的基准测试。
核心思路:论文的核心思路是利用几何构造任务作为评估生成式推理能力的测试平台。几何构造天然需要模型理解语言指令,并将其转化为精确的视觉表征。通过设计一系列几何构造问题,可以系统性地评估模型在理解、推理和生成方面的能力。
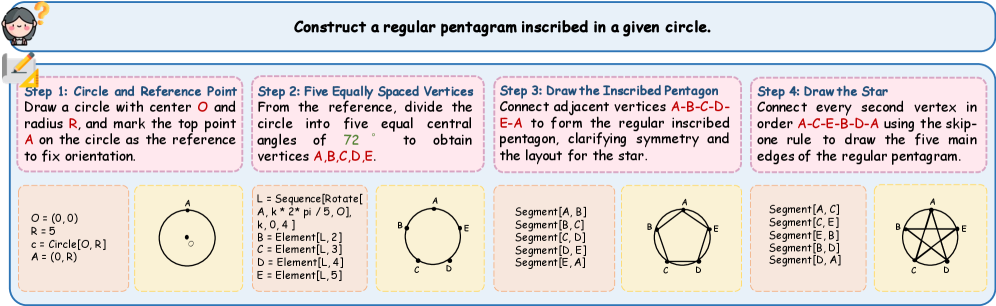
技术框架:GGBench包含一个几何构造任务数据集,每个任务包含一段描述几何图形的语言指令,以及对应的目标图形。模型的任务是根据语言指令生成相应的图像。评估指标包括生成图像的准确性、与目标图像的相似度等。该框架允许研究人员系统地评估模型在几何生成推理方面的能力,并诊断模型的优势和不足。
关键创新:GGBench的关键创新在于它将几何构造任务引入到多模态模型的评估中。与传统的判别式任务或无约束生成任务不同,几何构造任务需要模型进行更深层次的理解和推理,并将语言信息转化为精确的视觉表征。这使得GGBench能够更有效地评估模型的生成式推理能力。
关键设计:GGBench数据集包含多种类型的几何构造任务,例如绘制直线、圆、三角形等。每个任务都包含详细的语言描述,以及对应的目标图像。评估指标包括像素级别的准确率、结构相似性指标(SSIM)等。此外,GGBench还提供了一个评估平台,方便研究人员提交模型结果并进行比较。
🖼️ 关键图片

📊 实验亮点
GGBench提供了一个系统性的评估框架,能够诊断模型在几何生成推理方面的能力。通过在GGBench上进行评估,研究人员可以发现现有模型的不足之处,并开发出更强大的多模态模型。具体性能数据和对比基线需要在实际实验中获得,但该基准的提出本身就为未来的研究提供了方向。
🎯 应用场景
GGBench可用于评估和提升统一多模态模型在需要精确生成能力的场景中的表现,例如机器人操作、计算机辅助设计、教育软件等。通过提高模型在几何生成推理方面的能力,可以使其更好地理解和执行复杂的任务,从而在实际应用中发挥更大的作用。
📄 摘要(原文)
The advent of Unified Multimodal Models (UMMs) signals a paradigm shift in artificial intelligence, moving from passive perception to active, cross-modal generation. Despite their unprecedented ability to synthesize information, a critical gap persists in evaluation: existing benchmarks primarily assess discriminative understanding or unconstrained image generation separately, failing to measure the integrated cognitive process of generative reasoning. To bridge this gap, we propose that geometric construction provides an ideal testbed as it inherently demands a fusion of language comprehension and precise visual generation. We introduce GGBench, a benchmark designed specifically to evaluate geometric generative reasoning. It provides a comprehensive framework for systematically diagnosing a model's ability to not only understand and reason but to actively construct a solution, thereby setting a more rigorous standard for the next generation of intelligent systems. Project website: https://opendatalab-raiser.github.io/GGBench/.