DialogGraph-LLM: Graph-Informed LLMs for End-to-End Audio Dialogue Intent Recognition
作者: HongYu Liu, Junxin Li, Changxi Guo, Hao Chen, Yaqian Huang, Yifu Guo, Huan Yang, Lihua Cai
分类: cs.SD, cs.AI
发布日期: 2025-11-14 (更新: 2025-11-17)
备注: 8 pages, 2 figures. To appear in: Proceedings of the 28th European Conference on Artificial Intelligence (ECAI 2025), Frontiers in Artificial Intelligence and Applications, Vol. 413. DOI: 10.3233/FAIA251182
DOI: 10.3233/FAIA251182
🔗 代码/项目: GITHUB
💡 一句话要点
提出DialogGraph-LLM,结合图结构和LLM解决端到端音频对话意图识别问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频对话意图识别 图神经网络 大型语言模型 半监督学习 多模态融合 端到端学习 对话建模
📋 核心要点
- 现有方法难以有效捕捉说话者语句间的复杂依赖关系,且标注数据稀缺,限制了音频对话意图识别的性能。
- DialogGraph-LLM结合多关系对话注意力网络和多模态基础模型,实现声学到意图的直接推断,并利用半监督学习提升性能。
- 在MarketCalls和MIntRec 2.0数据集上,DialogGraph-LLM显著优于现有音频和文本驱动的基线方法,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为DialogGraph-LLM的端到端框架,用于识别多说话者长音频对话中的说话者意图。该框架结合了新颖的多关系对话注意力网络(MR-DAN)架构和多模态基础模型(如Qwen2.5-Omni-7B),用于直接的声学到意图的推断。此外,还设计了一种自适应半监督学习策略,该策略利用LLM和置信度感知的伪标签生成机制,该机制基于使用全局和类置信度的双阈值过滤,以及基于熵的样本选择过程,该过程优先考虑高信息量的未标记实例。在专有的MarketCalls语料库和公开的MIntRec 2.0基准上的大量评估表明,DialogGraph-LLM优于强大的音频和文本驱动的基线。该框架在真实场景音频对话中的意图识别方面表现出强大的性能和效率,证明了其在监督有限的音频丰富领域的实际价值。
🔬 方法详解
问题定义:论文旨在解决多说话者长音频对话中的说话者意图识别问题。现有方法主要面临两个痛点:一是难以捕捉说话者语句之间复杂的相互依赖关系,二是标注数据稀缺,导致模型训练困难。
核心思路:论文的核心思路是将对话建模成图结构,利用图神经网络捕捉语句间的关系,并结合大型语言模型(LLM)的强大语义理解能力,实现更准确的意图识别。此外,利用LLM生成伪标签进行半监督学习,缓解数据稀缺问题。
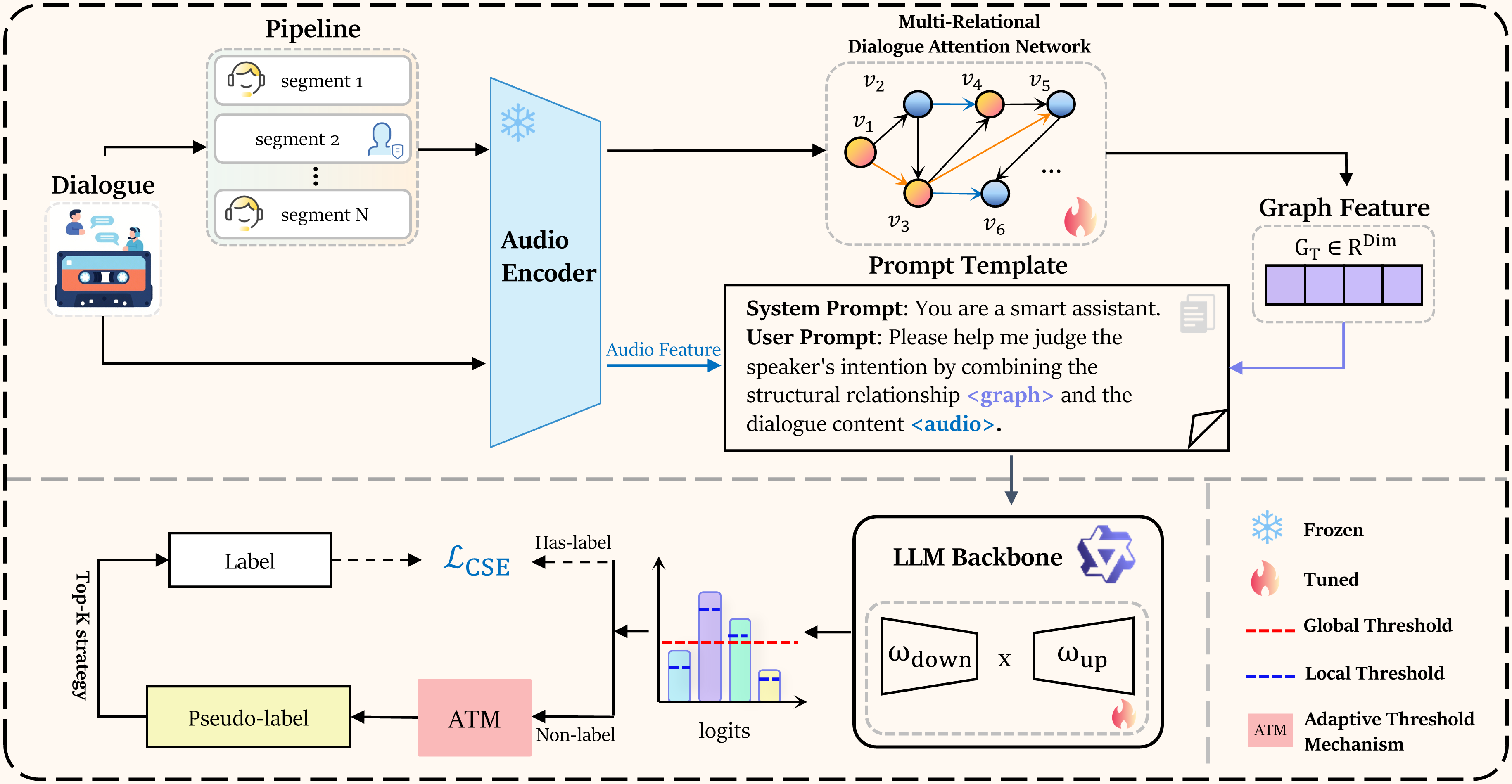
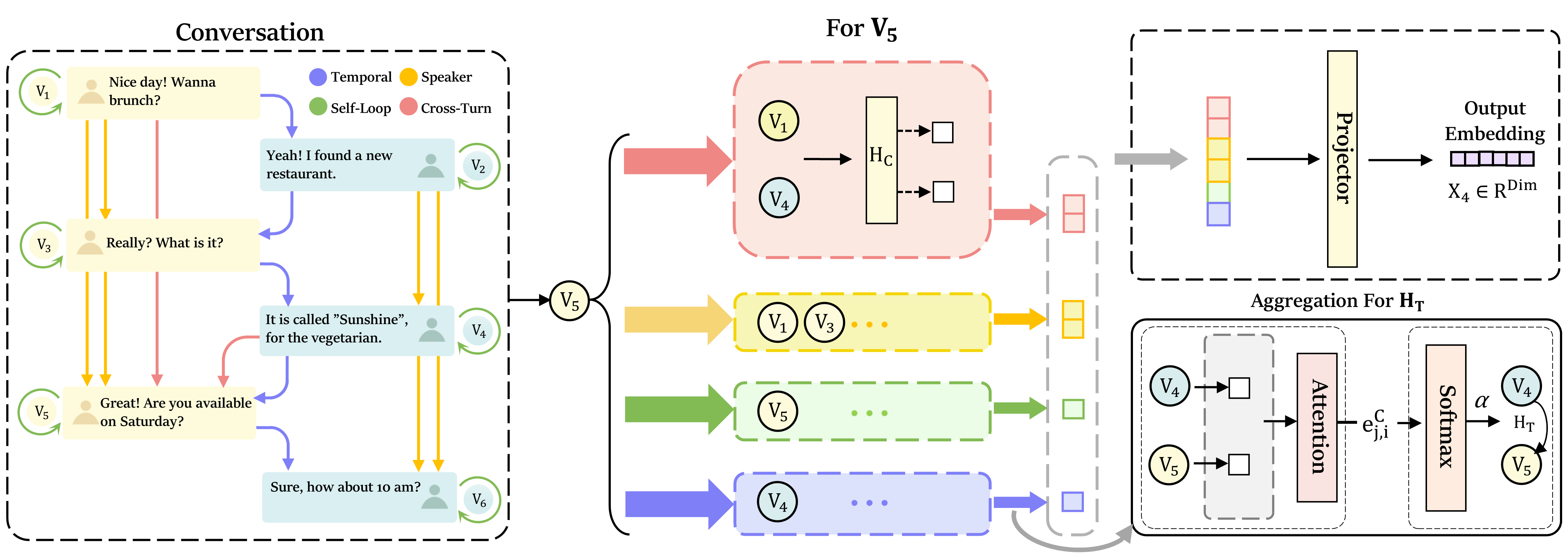
技术框架:DialogGraph-LLM框架主要包含以下几个模块:1) 多关系对话注意力网络(MR-DAN):用于将音频特征编码成节点表示,并学习节点之间的多关系图结构。2) 多模态基础模型:使用预训练的LLM(如Qwen2.5-Omni-7B)进行意图分类。3) 自适应半监督学习:利用LLM生成伪标签,并采用置信度过滤和熵选择策略,选择高质量的未标注样本进行训练。
关键创新:论文的关键创新在于:1) 提出了MR-DAN,能够有效建模对话中语句之间的复杂关系。2) 设计了自适应半监督学习策略,利用LLM生成高质量的伪标签,缓解了数据稀缺问题。3) 实现了端到端的音频对话意图识别,避免了对文本转录的依赖。
关键设计:MR-DAN使用多头注意力机制学习节点之间的关系,并采用不同的关系类型(如时间关系、语义关系)进行建模。半监督学习中,使用双阈值过滤(全局置信度和类别置信度)和熵选择策略,选择置信度高且信息量大的未标注样本。损失函数包括交叉熵损失和一致性损失,用于监督有标注数据和未标注数据的训练。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DialogGraph-LLM在MarketCalls数据集和MIntRec 2.0数据集上均取得了显著的性能提升。在MarketCalls数据集上,DialogGraph-LLM的准确率比最强的基线方法提高了5%以上。在MIntRec 2.0数据集上,DialogGraph-LLM也取得了 comparable 的结果,证明了其在不同数据集上的泛化能力。
🎯 应用场景
DialogGraph-LLM可应用于客户服务、会议记录、在线教育等多个领域。例如,在客户服务中,可以自动识别客户的意图,从而快速分配给合适的客服人员。在会议记录中,可以自动提取会议的关键议题和决策。在在线教育中,可以分析学生的提问,了解学生的学习难点,从而提供个性化的辅导。该研究具有重要的实际应用价值,能够提高工作效率和服务质量。
📄 摘要(原文)
Recognizing speaker intent in long audio dialogues among speakers has a wide range of applications, but is a non-trivial AI task due to complex inter-dependencies in speaker utterances and scarce annotated data. To address these challenges, an end-to-end framework, namely DialogGraph-LLM, is proposed in the current work. DialogGraph-LLM combines a novel Multi-Relational Dialogue Attention Network (MR-DAN) architecture with multimodal foundation models (e.g., Qwen2.5-Omni-7B) for direct acoustic-to-intent inference. An adaptive semi-supervised learning strategy is designed using LLM with a confidence-aware pseudo-label generation mechanism based on dual-threshold filtering using both global and class confidences, and an entropy-based sample selection process that prioritizes high-information unlabeled instances. Extensive evaluations on the proprietary MarketCalls corpus and the publicly available MIntRec 2.0 benchmark demonstrate DialogGraph-LLM's superiority over strong audio and text-driven baselines. The framework demonstrates strong performance and efficiency in intent recognition in real world scenario audio dialogues, proving its practical value for audio-rich domains with limited supervision. Our code is available at https://github.com/david188888/DialogGraph-LLM.