Characterizing and Understanding Energy Footprint and Efficiency of Small Language Model on Edges
作者: Md Romyull Islam, Bobin Deng, Nobel Dhar, Tu N. Nguyen, Selena He, Yong Shi, Kun Suo
分类: cs.DC, cs.AI, cs.CL, cs.LG
发布日期: 2025-11-07
备注: Submitted version; 9 pages, 5 figures; presented at IEEE MASS 2025 (online publication pending)
💡 一句话要点
边缘设备上小型语言模型能耗与效率评估及优化策略研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 边缘计算 能耗效率 推理延迟 GPU加速 嵌入式系统 性能评估
📋 核心要点
- 云端大型语言模型虽强大,但边缘部署小型语言模型可降低延迟并摆脱网络依赖,然而边缘设备算力与能耗受限。
- 该研究旨在评估不同小型语言模型在边缘设备上的能耗效率,并分析影响能耗的关键因素,为边缘部署提供指导。
- 实验表明,Jetson Orin Nano GPU加速方案能耗比最高,Llama 3.2平衡了精度与能耗,TinyLlama适合低功耗场景。
📝 摘要(中文)
本文评估了五种代表性小型语言模型(SLM)——Llama 3.2、Phi-3 Mini、TinyLlama和Gemma 2在Raspberry Pi 5、Jetson Nano和Jetson Orin Nano(CPU和GPU配置)上的功耗效率。结果表明,采用GPU加速的Jetson Orin Nano实现了最高的能量-性能比,显著优于基于CPU的设置。Llama 3.2在准确性和功耗效率之间提供了最佳平衡,而TinyLlama在牺牲准确性的前提下,非常适合低功耗环境。相比之下,Phi-3 Mini消耗的能量最多,尽管其准确性很高。此外,GPU加速、内存带宽和模型架构是优化推理功耗效率的关键。我们的实证分析为人工智能、智能系统和移动自组织平台提供了实用见解,以便在能量受限的环境中权衡准确性、推理延迟和功耗效率。
🔬 方法详解
问题定义:论文旨在解决在边缘设备上部署小型语言模型时,如何评估和优化其能耗效率的问题。现有方法缺乏对不同模型和硬件平台的系统性分析,难以指导实际部署,尤其是在能量受限的场景下。现有方法没有充分考虑GPU加速、内存带宽和模型架构等因素对能耗的影响。
核心思路:论文的核心思路是通过实证分析,系统地评估不同小型语言模型在不同边缘设备上的能耗效率,并识别影响能耗的关键因素。通过对比不同模型和硬件配置的性能,为开发者提供在精度、延迟和功耗之间进行权衡的依据。
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 模型选择:选择Llama 3.2、Phi-3 Mini、TinyLlama和Gemma 2等具有代表性的小型语言模型。 2. 硬件平台选择:选择Raspberry Pi 5、Jetson Nano和Jetson Orin Nano等常见的边缘设备,并配置CPU和GPU两种运行模式。 3. 性能指标测量:测量模型在不同硬件平台上的推理延迟、准确性和功耗等指标。 4. 数据分析:分析实验数据,评估不同模型和硬件配置的能耗效率,并识别影响能耗的关键因素。
关键创新:该研究的关键创新在于: 1. 系统性地评估了多种小型语言模型在不同边缘设备上的能耗效率,填补了相关研究的空白。 2. 识别了GPU加速、内存带宽和模型架构等影响能耗的关键因素,为优化边缘部署提供了指导。 3. 为开发者提供了在精度、延迟和功耗之间进行权衡的依据,有助于在能量受限的环境中选择合适的模型和硬件配置。
关键设计:论文的关键设计包括: 1. 选择具有代表性的小型语言模型,覆盖不同大小和架构。 2. 选择常见的边缘设备,模拟实际部署环境。 3. 采用标准的性能指标,如推理延迟、准确性和功耗,进行客观评估。 4. 对实验数据进行统计分析,识别显著性差异。
🖼️ 关键图片
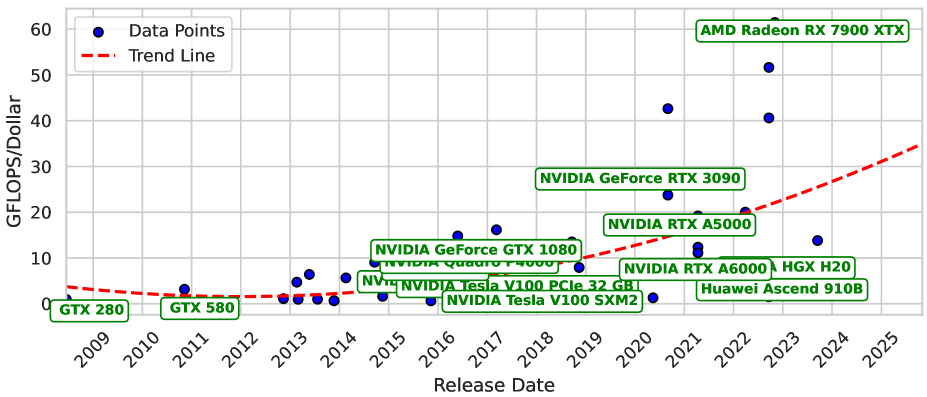
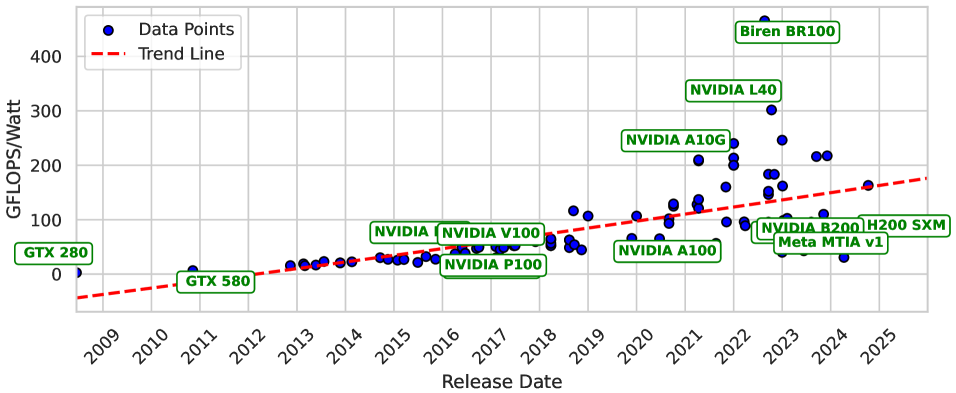

📊 实验亮点
实验结果表明,Jetson Orin Nano GPU加速方案能耗比最高,显著优于CPU方案。Llama 3.2在精度和能耗间取得最佳平衡,TinyLlama适合低功耗场景。Phi-3 Mini精度高但能耗也最高。研究还发现GPU加速、内存带宽和模型架构是优化能耗的关键因素。
🎯 应用场景
该研究成果可应用于各种边缘计算场景,例如智能家居、智能安防、自动驾驶、移动医疗等。通过选择合适的模型和硬件配置,可以在能量受限的环境中实现高效的AI推理,提升用户体验,降低运营成本。未来的研究可以进一步探索模型压缩、量化等技术,以进一步降低边缘设备的能耗。
📄 摘要(原文)
Cloud-based large language models (LLMs) and their variants have significantly influenced real-world applications. Deploying smaller models (i.e., small language models (SLMs)) on edge devices offers additional advantages, such as reduced latency and independence from network connectivity. However, edge devices' limited computing resources and constrained energy budgets challenge efficient deployment. This study evaluates the power efficiency of five representative SLMs - Llama 3.2, Phi-3 Mini, TinyLlama, and Gemma 2 on Raspberry Pi 5, Jetson Nano, and Jetson Orin Nano (CPU and GPU configurations). Results show that Jetson Orin Nano with GPU acceleration achieves the highest energy-to-performance ratio, significantly outperforming CPU-based setups. Llama 3.2 provides the best balance of accuracy and power efficiency, while TinyLlama is well-suited for low-power environments at the cost of reduced accuracy. In contrast, Phi-3 Mini consumes the most energy despite its high accuracy. In addition, GPU acceleration, memory bandwidth, and model architecture are key in optimizing inference energy efficiency. Our empirical analysis offers practical insights for AI, smart systems, and mobile ad-hoc platforms to leverage tradeoffs from accuracy, inference latency, and power efficiency in energy-constrained environments.