Anchors in the Machine: Behavioral and Attributional Evidence of Anchoring Bias in LLMs
作者: Felipe Valencia-Clavijo
分类: cs.AI, cs.CL, econ.GN
发布日期: 2025-11-07
💡 一句话要点
通过行为和归因分析揭示LLM中存在的锚定偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 锚定偏差 认知偏差 Shapley值 归因分析 行为分析 模型安全 可解释性
📋 核心要点
- 现有研究对LLM锚定偏差的分析主要依赖表面输出,缺乏对内部机制和归因贡献的深入探究。
- 论文提出一种基于对数概率的行为分析方法,并结合Shapley值归因,量化锚点对模型输出的影响。
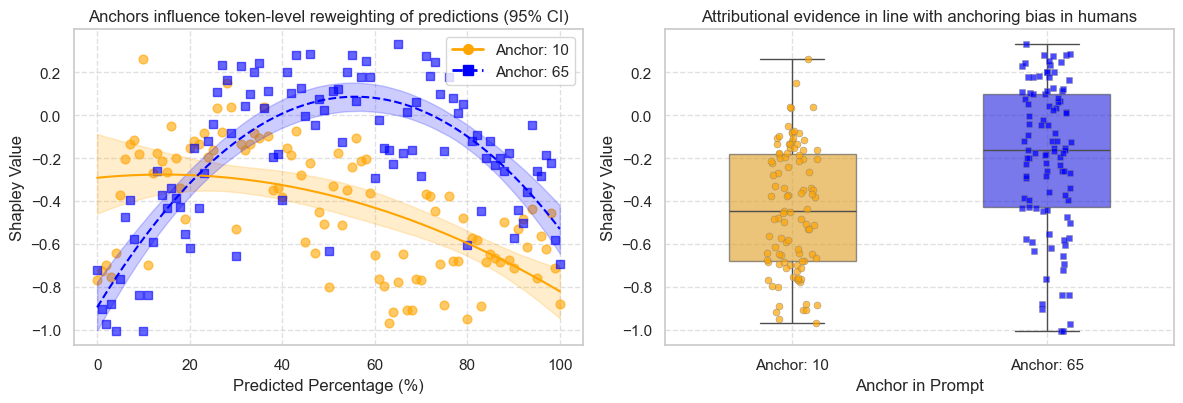
- 实验结果表明,Gemma-2B、Phi-2和Llama-2-7B等模型表现出显著的锚定效应,且锚点会影响模型的权重调整。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被视为行为主体和决策系统进行研究,但观察到的认知偏差是否反映了表面模仿或更深层次的概率转移仍不清楚。锚定偏差是一种经典的人类判断偏差,提供了一个关键的测试案例。虽然先前的工作表明LLM表现出锚定效应,但大多数证据依赖于表面层面的输出,而内部机制和归因贡献尚未得到探索。本文通过三个方面的贡献推进了LLM中锚定效应的研究:(1) 基于对数概率的行为分析,表明锚点会改变整个输出分布,并控制了训练数据污染;(2) 通过结构化提示字段的精确Shapley值归因,量化锚点对模型对数概率的影响;(3) 统一的锚定偏差敏感度评分,整合了六个开源模型的行为和归因证据。结果表明Gemma-2B、Phi-2和Llama-2-7B中存在强大的锚定效应,归因表明锚点影响了权重调整。GPT-2、Falcon-RW-1B和GPT-Neo-125M等较小模型表现出可变性,表明规模可能会调节敏感性。然而,归因效应因提示设计而异,突显了将LLM视为人类替代品的脆弱性。研究结果表明,LLM中的锚定偏差是稳健、可测量和可解释的,同时突出了应用领域的风险。更广泛地说,该框架连接了行为科学、LLM安全性和可解释性,为评估LLM中的其他认知偏差提供了一条可重复的路径。
🔬 方法详解
问题定义:论文旨在深入研究大型语言模型(LLM)中存在的锚定偏差,并探究其内部机制。现有研究主要关注LLM的表面输出,缺乏对锚定偏差的归因分析,无法确定锚点如何影响模型的决策过程。
核心思路:论文的核心思路是通过结合行为分析和归因分析,全面评估LLM中的锚定偏差。行为分析用于观察锚点对模型输出分布的影响,而归因分析则用于量化锚点对模型内部状态(如对数概率)的影响。这种双管齐下的方法可以更深入地了解LLM如何受到锚定偏差的影响。
技术框架:论文的技术框架主要包括三个阶段:(1) 行为分析:通过设计特定的提示,向LLM提供不同的锚点,并分析模型输出的概率分布变化。(2) 归因分析:使用Shapley值方法,量化提示中不同字段(包括锚点)对模型输出对数概率的贡献。(3) 锚定偏差敏感度评分:整合行为分析和归因分析的结果,为每个模型计算一个锚定偏差敏感度评分,用于比较不同模型对锚定偏差的敏感程度。
关键创新:论文的关键创新在于将Shapley值归因方法应用于LLM的锚定偏差分析。通过计算每个提示字段的Shapley值,可以精确地量化锚点对模型输出的影响,从而深入了解锚定偏差的内部机制。此外,论文还提出了一个统一的锚定偏差敏感度评分,用于比较不同模型对锚定偏差的敏感程度。
关键设计:在行为分析中,论文设计了多种提示模板,以控制训练数据污染的影响。在归因分析中,论文使用了精确的Shapley值计算方法,以确保归因结果的准确性。此外,论文还考虑了不同提示设计对归因结果的影响,并进行了相应的分析。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Gemma-2B、Phi-2和Llama-2-7B等模型表现出显著的锚定效应,且锚点会影响模型的权重调整。Shapley值归因分析表明,锚点对模型输出的对数概率有显著影响。较小模型(如GPT-2、Falcon-RW-1B和GPT-Neo-125M)表现出可变性,表明模型规模可能影响锚定偏差的敏感程度。
🎯 应用场景
该研究成果可应用于评估和改进LLM的可靠性和安全性,尤其是在金融、医疗等高风险决策领域。通过量化和理解LLM中的锚定偏差,可以开发相应的缓解策略,提高LLM决策的公正性和准确性。此外,该研究框架可推广到其他认知偏差的评估,促进LLM的负责任发展。
📄 摘要(原文)
Large language models (LLMs) are increasingly examined as both behavioral subjects and decision systems, yet it remains unclear whether observed cognitive biases reflect surface imitation or deeper probability shifts. Anchoring bias, a classic human judgment bias, offers a critical test case. While prior work shows LLMs exhibit anchoring, most evidence relies on surface-level outputs, leaving internal mechanisms and attributional contributions unexplored. This paper advances the study of anchoring in LLMs through three contributions: (1) a log-probability-based behavioral analysis showing that anchors shift entire output distributions, with controls for training-data contamination; (2) exact Shapley-value attribution over structured prompt fields to quantify anchor influence on model log-probabilities; and (3) a unified Anchoring Bias Sensitivity Score integrating behavioral and attributional evidence across six open-source models. Results reveal robust anchoring effects in Gemma-2B, Phi-2, and Llama-2-7B, with attribution signaling that the anchors influence reweighting. Smaller models such as GPT-2, Falcon-RW-1B, and GPT-Neo-125M show variability, suggesting scale may modulate sensitivity. Attributional effects, however, vary across prompt designs, underscoring fragility in treating LLMs as human substitutes. The findings demonstrate that anchoring bias in LLMs is robust, measurable, and interpretable, while highlighting risks in applied domains. More broadly, the framework bridges behavioral science, LLM safety, and interpretability, offering a reproducible path for evaluating other cognitive biases in LLMs.