Assessing the Reliability of Large Language Models in the Bengali Legal Context: A Comparative Evaluation Using LLM-as-Judge and Legal Experts
作者: Sabik Aftahee, A. F. M. Farhad, Arpita Mallik, Ratnajit Dhar, Jawadul Karim, Nahiyan Bin Noor, Ishmam Ahmed Solaiman
分类: cs.CY, cs.AI
发布日期: 2025-11-07
💡 一句话要点
评估大语言模型在孟加拉语法律场景下的可靠性:LLM-as-Judge与法律专家对比评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 法律咨询 孟加拉语 可靠性评估 LLM-as-Judge
📋 核心要点
- 孟加拉国法律援助面临费用高、语言复杂、律师短缺等挑战,现有方法难以有效解决。
- 利用大型语言模型提供法律咨询,通过LLM-as-Judge和法律专家双重评估确保可靠性。
- 实验表明AI模型虽能生成高质量回复,但也存在错误信息风险,需专家验证和安全保障。
📝 摘要(中文)
在孟加拉国,获取法律援助困难重重,包括高昂的费用、复杂的法律语言、律师短缺以及数百万未决诉讼案件。诸如OpenAI GPT-4.1 Mini、Gemini 2.0 Flash、Meta Llama 3 70B和DeepSeek R1等生成式AI模型,有可能通过提供快速且经济实惠的法律建议来普及法律援助。本研究从Facebook群组“了解你的权利”中收集了250个真实的法律问题,该群组由经过验证的法律专家定期提供权威解答。这些问题随后被提交给四个先进的AI模型,并使用一致的标准提示生成回复。采用了一种全面的双重评估框架,其中最先进的LLM模型充当法官,从事实准确性、法律适当性、完整性和清晰度四个关键维度评估每个AI生成的回复。随后,同一组问题由三位有执照的孟加拉国法律专业人士根据相同的标准进行评估。此外,还应用了包括BLEU分数在内的自动评估指标来评估回复的相似性。研究结果揭示了一个复杂的局面,即AI模型经常生成高质量、结构良好的法律回复,但也产生危险的错误信息,包括捏造的案例引用、不正确的法律程序和可能有害的建议。这些结果强调,在AI系统安全地部署到孟加拉国的法律咨询之前,迫切需要严格的专家验证和全面的保障措施。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在孟加拉语法律咨询场景下的可靠性。现有方法主要依赖人工法律专家,成本高昂且效率低下,无法满足大量民众的法律咨询需求。此外,直接使用未经评估的LLM可能导致错误或有害的法律建议,存在潜在风险。
核心思路:论文的核心思路是采用一种双重评估框架,结合LLM-as-Judge的自动评估和法律专家的手动评估,全面评估LLM在法律咨询中的表现。通过对比LLM和法律专家的评估结果,识别LLM的优势和不足,为安全部署LLM提供法律咨询服务提供依据。
技术框架:整体框架包含以下几个主要阶段:1) 数据收集:从Facebook群组“了解你的权利”收集真实的孟加拉语法律问题。2) LLM回复生成:使用标准提示,让多个LLM(GPT-4.1 Mini, Gemini 2.0 Flash, Llama 3 70B, DeepSeek R1)对问题进行回复。3) LLM-as-Judge评估:使用先进的LLM作为法官,从事实准确性、法律适当性、完整性和清晰度四个维度评估LLM生成的回复。4) 法律专家评估:三位有执照的孟加拉国法律专业人士根据相同的标准评估LLM生成的回复。5) 自动评估:使用BLEU等指标评估回复的相似性。6) 结果分析:对比LLM-as-Judge、法律专家和自动评估的结果,分析LLM在法律咨询中的表现。
关键创新:论文的关键创新在于采用了LLM-as-Judge与法律专家相结合的双重评估框架。这种方法不仅可以降低评估成本,还可以更全面地评估LLM在法律咨询中的表现,识别潜在的风险。与现有方法相比,该方法更具可扩展性和可靠性。
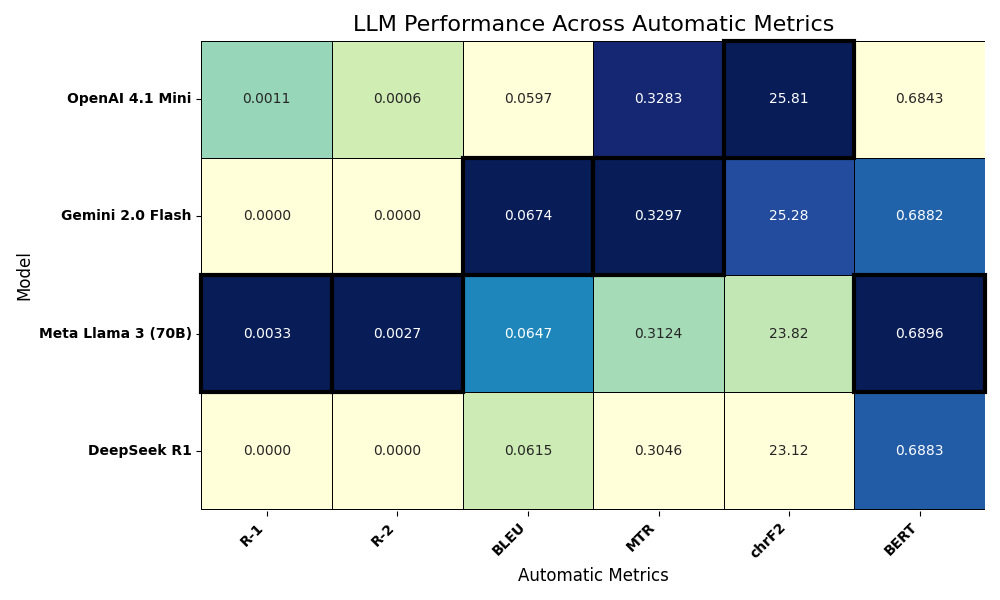
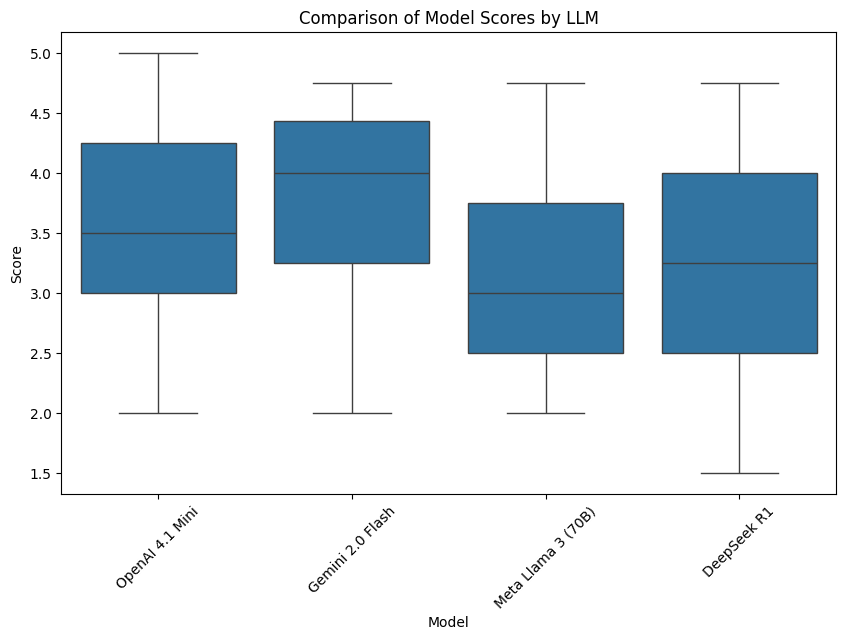
关键设计:在LLM-as-Judge评估中,选择了最先进的LLM模型作为法官,并设计了详细的评估标准,包括事实准确性、法律适当性、完整性和清晰度。在法律专家评估中,邀请了三位有执照的孟加拉国法律专业人士参与评估,确保评估结果的专业性和可靠性。此外,还使用了BLEU等自动评估指标,对回复的相似性进行量化分析。
🖼️ 关键图片
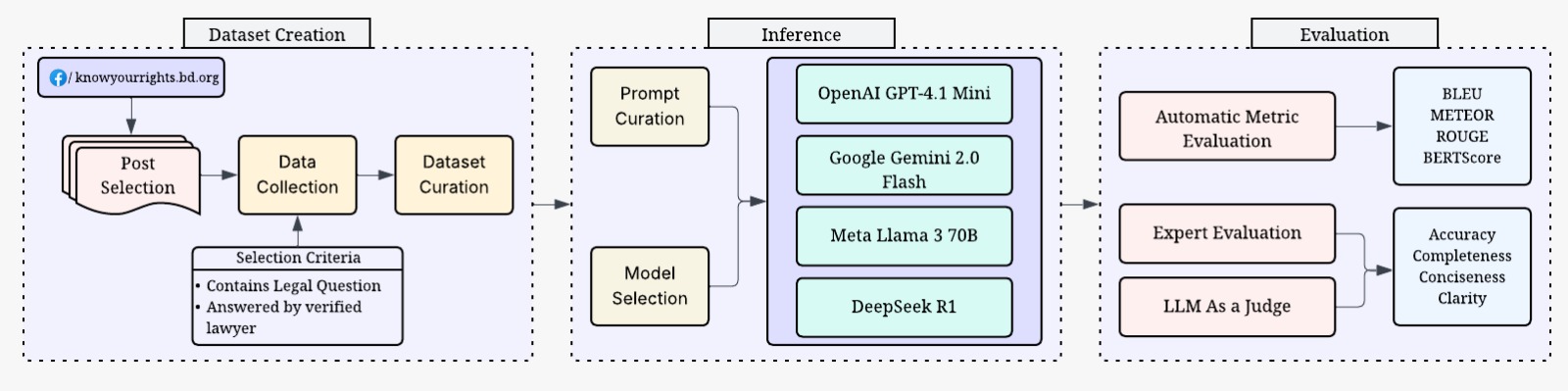
📊 实验亮点
实验结果表明,AI模型在生成高质量、结构良好的法律回复方面表现出色,但在事实准确性和法律适当性方面存在不足,例如捏造案例引用和提供不正确的法律程序。这强调了在实际应用中,必须进行严格的专家验证和安全保障,以避免潜在的法律风险。
🎯 应用场景
该研究成果可应用于开发智能法律咨询系统,为孟加拉国及其他发展中国家提供低成本、便捷的法律援助服务。通过结合LLM的快速响应能力和法律专家的专业知识,有望缓解法律资源短缺问题,促进社会公平正义。未来可进一步探索LLM在法律文书生成、案件分析等领域的应用。
📄 摘要(原文)
Accessing legal help in Bangladesh is hard. People face high fees, complex legal language, a shortage of lawyers, and millions of unresolved court cases. Generative AI models like OpenAI GPT-4.1 Mini, Gemini 2.0 Flash, Meta Llama 3 70B, and DeepSeek R1 could potentially democratize legal assistance by providing quick and affordable legal advice. In this study, we collected 250 authentic legal questions from the Facebook group "Know Your Rights," where verified legal experts regularly provide authoritative answers. These questions were subsequently submitted to four four advanced AI models and responses were generated using a consistent, standardized prompt. A comprehensive dual evaluation framework was employed, in which a state-of-the-art LLM model served as a judge, assessing each AI-generated response across four critical dimensions: factual accuracy, legal appropriateness, completeness, and clarity. Following this, the same set of questions was evaluated by three licensed Bangladeshi legal professionals according to the same criteria. In addition, automated evaluation metrics, including BLEU scores, were applied to assess response similarity. Our findings reveal a complex landscape where AI models frequently generate high-quality, well-structured legal responses but also produce dangerous misinformation, including fabricated case citations, incorrect legal procedures, and potentially harmful advice. These results underscore the critical need for rigorous expert validation and comprehensive safeguards before AI systems can be safely deployed for legal consultation in Bangladesh.