SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
作者: Jingxuan Xu, Ken Deng, Weihao Li, Songwei Yu, Huaixi Tang, Haoyang Huang, Zhiyi Lai, Zizheng Zhan, Yanan Wu, Chenchen Zhang, Kepeng Lei, Yifan Yao, Xinping Lei, Wenqiang Zhu, Zongxian Feng, Han Li, Junqi Xiong, Dailin Li, Zuchen Gao, Kun Wu, Wen Xiang, Ziqi Zhan, Yuanxing Zhang, Wuxuan Gong, Ziyuan Gao, Guanxiang Wang, Yirong Xue, Mengtong Li, Mengfei Xie, Xiaojiang Zhang, Jinghui Wang, Wenhao Zhuang, Zheng Lin, Huiming Wang, Zhaoxiang Zhang, Yuqun Zhang, Haotian Zhang, Bin Chen, Jiaheng Liu
分类: cs.SE, cs.AI
发布日期: 2025-11-07 (更新: 2025-11-11)
💡 一句话要点
提出SWE-Compass,用于全面评估大型语言模型在软件工程中的智能编码能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 软件工程 代码生成 代码修复 基准测试 智能编码 代码评估
📋 核心要点
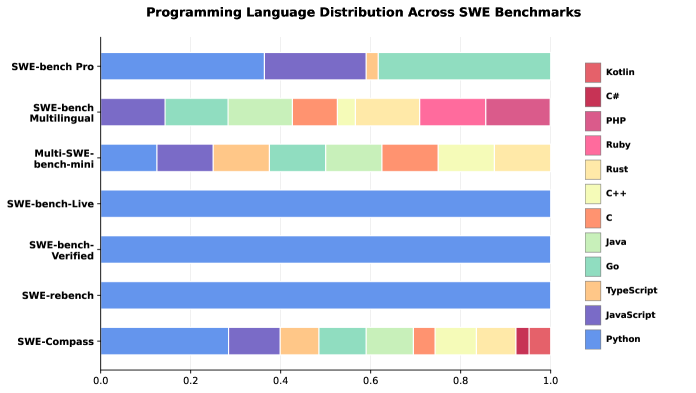
- 现有软件工程LLM评估benchmark在任务覆盖、语言支持和真实工作流对齐方面存在不足。
- SWE-Compass通过统一异构代码评估,构建结构化、生产对齐的综合性评测框架。
- 实验结果揭示了不同任务、语言和场景下的难度层级,为诊断和提升LLM智能编码能力奠定基础。
📝 摘要(中文)
现有的大型语言模型(LLMs)软件工程评估受限于任务覆盖范围窄、语言偏差以及与真实开发者工作流程的不充分对齐。现有基准测试通常侧重于算法问题或以Python为中心的错误修复,而忽略了软件工程的关键维度。为了解决这些差距,我们引入了SWE-Compass,这是一个全面的基准测试,将异构的代码相关评估统一到一个结构化且与生产对齐的框架中。SWE-Compass涵盖8种任务类型、8种编程场景和10种编程语言,包含2000个高质量实例,这些实例来自真实的GitHub pull requests,并通过系统的过滤和验证进行改进。我们使用SWE-Agent和Claude Code两个智能框架对十个最先进的LLM进行了基准测试,揭示了任务类型、语言和场景之间清晰的难度等级。此外,通过将评估与真实的开发者实践对齐,SWE-Compass为诊断和提升大型语言模型中的智能编码能力提供了严谨且可复现的基础。
🔬 方法详解
问题定义:现有的大型语言模型在软件工程领域的评估存在局限性,主要体现在任务类型单一(集中于算法问题或Python bug修复)、语言支持不足(主要针对Python)以及与真实开发者工作流程脱节。这些局限性使得我们难以全面评估LLM在实际软件开发中的能力。
核心思路:SWE-Compass的核心思路是构建一个更全面、更贴近实际软件开发场景的评估基准。通过覆盖多种任务类型、编程场景和编程语言,并使用来自真实GitHub pull requests的数据,SWE-Compass旨在更准确地反映LLM在真实软件开发环境中的表现。
技术框架:SWE-Compass框架包含以下几个主要组成部分:1) 任务类型:定义了8种不同的软件工程任务,例如代码生成、代码修复、代码翻译等。2) 编程场景:定义了8种不同的编程场景,例如Web开发、移动开发、数据科学等。3) 编程语言:支持10种不同的编程语言,包括Python、Java、C++等。4) 数据集:包含2000个高质量实例,这些实例来自真实的GitHub pull requests,并经过系统的过滤和验证。5) 评估指标:使用多种评估指标来衡量LLM在不同任务、场景和语言下的表现。
关键创新:SWE-Compass的关键创新在于其全面性和真实性。它不仅覆盖了更广泛的任务类型、编程场景和编程语言,而且使用了来自真实GitHub pull requests的数据,从而更准确地反映了LLM在实际软件开发环境中的表现。此外,SWE-Compass还提供了一个结构化的评估框架,使得研究人员可以更方便地比较不同LLM的性能。
关键设计:SWE-Compass的数据集构建过程包括以下关键步骤:1) 从GitHub pull requests中收集候选实例。2) 使用一系列过滤规则来筛选高质量的实例。3) 对筛选后的实例进行人工验证,以确保其质量和准确性。此外,SWE-Compass还定义了一套详细的评估指标,用于衡量LLM在不同任务、场景和语言下的表现。具体的参数设置和损失函数取决于所评估的LLM和任务类型,论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
该论文通过SWE-Compass基准测试,对10个先进的LLM在SWE-Agent和Claude Code框架下进行了评估。实验结果揭示了不同任务类型、语言和场景下的难度层级,为理解和提升LLM的智能编码能力提供了重要数据。具体的性能数据和提升幅度在摘要和方法部分未详细说明,属于未知信息。
🎯 应用场景
SWE-Compass可用于评估和比较不同大型语言模型在软件工程领域的智能编码能力,帮助开发者选择合适的模型。同时,该基准测试也能促进LLM在软件开发自动化方面的应用,例如自动代码生成、代码修复和代码审查,从而提高软件开发效率和质量。未来,SWE-Compass可以扩展到更多任务类型和编程语言,并与实际开发工具集成。
📄 摘要(原文)
Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.