TeaRAG: A Token-Efficient Agentic Retrieval-Augmented Generation Framework
作者: Chao Zhang, Yuhao Wang, Derong Xu, Haoxin Zhang, Yuanjie Lyu, Yuhao Chen, Shuochen Liu, Tong Xu, Xiangyu Zhao, Yan Gao, Yao Hu, Enhong Chen
分类: cs.IR, cs.AI
发布日期: 2025-11-07
备注: 32 pages
🔗 代码/项目: GITHUB
💡 一句话要点
TeaRAG通过压缩检索内容和推理步骤,提升Agentic RAG的token效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 Agentic RAG 知识图谱 个性化PageRank 直接偏好优化 token效率 语言模型
📋 核心要点
- 现有Agentic RAG方法在提升准确率的同时,引入了大量的token开销,导致效率降低。
- TeaRAG通过压缩检索内容(知识图谱+PageRank)和推理步骤(IP-DPO)来提升token效率。
- 实验结果表明,TeaRAG在多个数据集上显著降低了token使用量,同时保持甚至提升了准确率。
📝 摘要(中文)
检索增强生成(RAG)利用外部知识来提高大型语言模型(LLM)的可靠性。为了灵活性,Agentic RAG采用自主的、多轮的检索和推理来解决查询。虽然最近的Agentic RAG通过强化学习得到了改进,但它们通常会因搜索和推理过程而产生大量的token开销。这种权衡优先考虑了准确性而非效率。为了解决这个问题,本文提出了TeaRAG,一个token高效的Agentic RAG框架,能够压缩检索内容和推理步骤。首先,通过使用简洁的三元组增强基于块的语义检索的图检索来压缩检索到的内容。然后,从语义相似性和共现性构建知识关联图。最后,利用个性化PageRank来突出该图中的关键知识,从而减少每次检索的token数量。此外,为了减少推理步骤,提出了迭代过程感知直接偏好优化(IP-DPO)。具体来说,我们的奖励函数通过知识匹配机制评估知识的充分性,同时惩罚过多的推理步骤。这种设计可以产生高质量的偏好对数据集,支持迭代DPO以提高推理的简洁性。在六个数据集上,TeaRAG在Llama3-8B-Instruct和Qwen2.5-14B-Instruct上分别提高了4%和2%的平均精确匹配率,同时减少了61%和59%的输出token。
🔬 方法详解
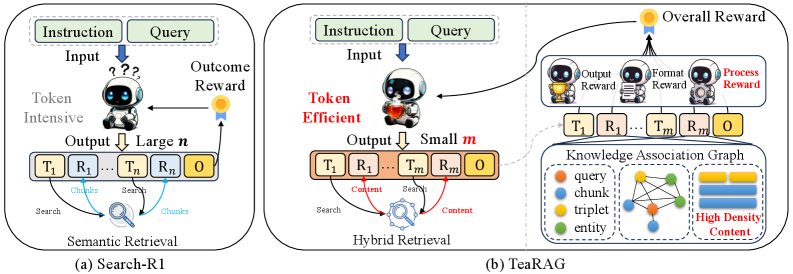
问题定义:Agentic RAG旨在通过自主多轮检索和推理增强LLM的性能,但现有方法在检索和推理过程中产生大量token开销,导致效率低下。如何在保证准确性的前提下,降低token消耗是亟待解决的问题。
核心思路:TeaRAG的核心思路是双管齐下,一方面压缩检索到的知识内容,另一方面减少推理所需的步骤。通过知识图谱和PageRank算法提取关键知识,减少检索token;通过IP-DPO优化推理过程,减少推理步骤。
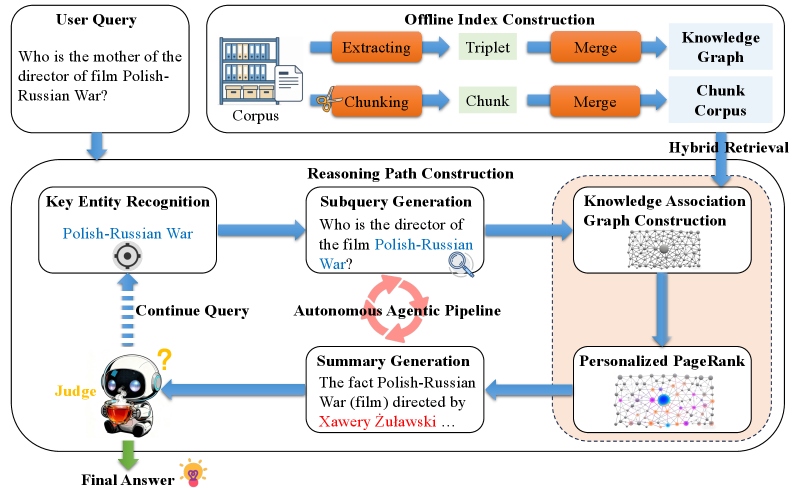
技术框架:TeaRAG框架主要包含两个阶段:知识压缩和推理优化。知识压缩阶段,首先进行基于chunk的语义检索,然后构建知识关联图,并利用个性化PageRank提取关键知识。推理优化阶段,使用IP-DPO方法,通过奖励函数引导模型生成更简洁的推理过程。
关键创新:TeaRAG的关键创新在于结合了知识图谱和个性化PageRank进行知识压缩,以及提出了IP-DPO方法来优化推理过程。IP-DPO通过知识匹配机制评估知识充分性,并惩罚冗余推理步骤,从而生成高质量的偏好对数据集,迭代提升推理简洁性。
关键设计:知识图谱构建基于语义相似性和共现性,个性化PageRank用于突出关键知识节点。IP-DPO的奖励函数设计是关键,它需要准确评估知识充分性并有效惩罚冗余步骤。具体参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
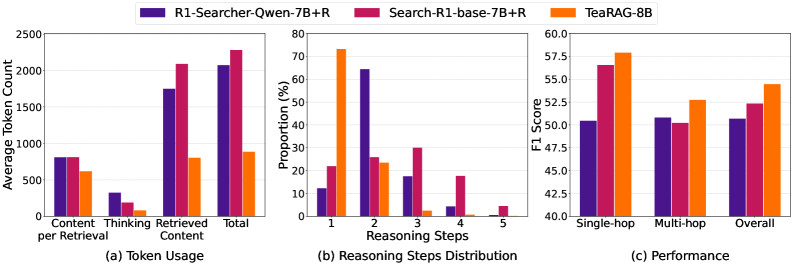
实验结果表明,TeaRAG在六个数据集上,使用Llama3-8B-Instruct和Qwen2.5-14B-Instruct模型时,平均精确匹配率分别提高了4%和2%,同时输出token分别减少了61%和59%。这表明TeaRAG在显著降低token消耗的同时,还能保持甚至提升模型的准确性。
🎯 应用场景
TeaRAG框架可应用于各种需要检索增强生成的大型语言模型应用场景,例如问答系统、知识库构建、智能客服等。通过降低token消耗,可以显著降低部署成本,提高响应速度,并使得Agentic RAG更易于在资源受限的环境中使用。该研究对于推动RAG技术在实际应用中的普及具有重要意义。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) utilizes external knowledge to augment Large Language Models' (LLMs) reliability. For flexibility, agentic RAG employs autonomous, multi-round retrieval and reasoning to resolve queries. Although recent agentic RAG has improved via reinforcement learning, they often incur substantial token overhead from search and reasoning processes. This trade-off prioritizes accuracy over efficiency. To address this issue, this work proposes TeaRAG, a token-efficient agentic RAG framework capable of compressing both retrieval content and reasoning steps. 1) First, the retrieved content is compressed by augmenting chunk-based semantic retrieval with a graph retrieval using concise triplets. A knowledge association graph is then built from semantic similarity and co-occurrence. Finally, Personalized PageRank is leveraged to highlight key knowledge within this graph, reducing the number of tokens per retrieval. 2) Besides, to reduce reasoning steps, Iterative Process-aware Direct Preference Optimization (IP-DPO) is proposed. Specifically, our reward function evaluates the knowledge sufficiency by a knowledge matching mechanism, while penalizing excessive reasoning steps. This design can produce high-quality preference-pair datasets, supporting iterative DPO to improve reasoning conciseness. Across six datasets, TeaRAG improves the average Exact Match by 4% and 2% while reducing output tokens by 61% and 59% on Llama3-8B-Instruct and Qwen2.5-14B-Instruct, respectively. Code is available at https://github.com/Applied-Machine-Learning-Lab/TeaRAG.