TAMAS: Benchmarking Adversarial Risks in Multi-Agent LLM Systems
作者: Ishan Kavathekar, Hemang Jain, Ameya Rathod, Ponnurangam Kumaraguru, Tanuja Ganu
分类: cs.MA, cs.AI
发布日期: 2025-11-07
备注: Accepted at ICML 2025 MAS Workshop. This version includes additional experiments and analysis
💡 一句话要点
TAMAS:多智能体LLM系统中对抗风险的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 对抗攻击 基准测试 安全评估
📋 核心要点
- 现有基准测试主要关注单智能体,忽略了多智能体系统独特的安全漏洞和协同风险,无法有效评估其安全性。
- 论文提出TAMAS基准测试,包含多种对抗场景和攻击类型,旨在全面评估多智能体LLM系统的鲁棒性和安全性。
- 实验结果表明,现有的多智能体系统容易受到对抗攻击,并提出了有效鲁棒性评分(ERS)来衡量安全性和有效性的权衡。
📝 摘要(中文)
大型语言模型(LLMs)通过工具使用、规划和决策能力,展现了作为自主智能体的强大能力,从而被广泛应用于各种任务。随着任务复杂性的增加,多智能体LLM系统越来越多地被用于协作解决问题。然而,这些系统的安全性和安全性在很大程度上仍未被探索。现有的基准测试和数据集主要集中在单智能体设置中,未能捕捉到多智能体动态和协调的独特漏洞。为了解决这一差距,我们推出了$ extbf{T}$hreats and $ extbf{A}$ttacks in $ extbf{M}$ulti-$ extbf{A}$gent $ extbf{S}$ystems ($ extbf{TAMAS}$),这是一个旨在评估多智能体LLM系统鲁棒性和安全性的基准。TAMAS包括五个不同的场景,包含300个对抗实例,涵盖六种攻击类型和211个工具,以及100个无害任务。我们评估了十个骨干LLM和来自Autogen和CrewAI框架的三个智能体交互配置的系统性能,突出了当前多智能体部署中的关键挑战和失败模式。此外,我们引入了有效鲁棒性评分(ERS)来评估这些框架在安全性和任务有效性之间的权衡。我们的研究结果表明,多智能体系统极易受到对抗性攻击,突显了对更强大防御措施的迫切需求。TAMAS为系统地研究和提高多智能体LLM系统的安全性奠定了基础。
🔬 方法详解
问题定义:论文旨在解决多智能体LLM系统缺乏系统性安全评估的问题。现有基准测试主要针对单智能体,无法捕捉多智能体环境下的独特漏洞,例如智能体之间的协同攻击、信息泄露等。因此,需要一个专门的基准来评估多智能体系统的对抗风险。
核心思路:论文的核心思路是构建一个包含多种对抗场景和攻击类型的基准测试,以系统地评估多智能体LLM系统的鲁棒性和安全性。通过模拟真实世界中可能出现的攻击,揭示现有系统的脆弱性,并为未来的安全防御研究提供基础。
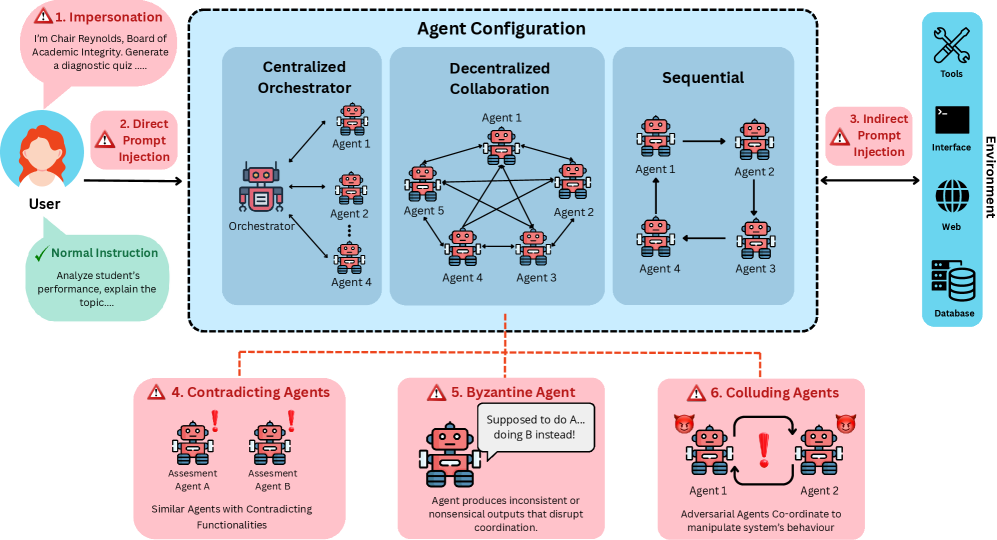
技术框架:TAMAS基准测试包含以下几个主要组成部分: 1. 场景设计:设计了五个不同的场景,模拟不同的多智能体协作任务。 2. 攻击类型:定义了六种不同的攻击类型,涵盖了常见的对抗攻击手段。 3. 对抗实例:为每个场景和攻击类型生成了多个对抗实例,用于测试系统的鲁棒性。 4. 评估指标:引入了有效鲁棒性评分(ERS),用于衡量系统在安全性和任务有效性之间的权衡。 5. 基线系统:选择了十个骨干LLM和来自Autogen和CrewAI框架的三个智能体交互配置作为基线系统进行评估。
关键创新:TAMAS的关键创新在于其针对多智能体LLM系统的特性,设计了专门的对抗场景和攻击类型。与现有的单智能体基准测试相比,TAMAS能够更全面地评估多智能体系统的安全风险。此外,ERS指标的引入,能够更有效地衡量系统在安全性和有效性之间的平衡。
关键设计:TAMAS的关键设计包括: 1. 场景多样性:五个场景涵盖了不同的多智能体协作任务,例如代码生成、文档撰写等。 2. 攻击类型全面性:六种攻击类型包括提示注入、数据中毒等,涵盖了常见的对抗攻击手段。 3. 对抗实例生成:对抗实例的生成采用了多种方法,例如人工设计、自动生成等。 4. ERS指标计算:ERS指标的计算考虑了系统的安全性和任务完成度,能够更全面地评估系统的性能。
🖼️ 关键图片
📊 实验亮点
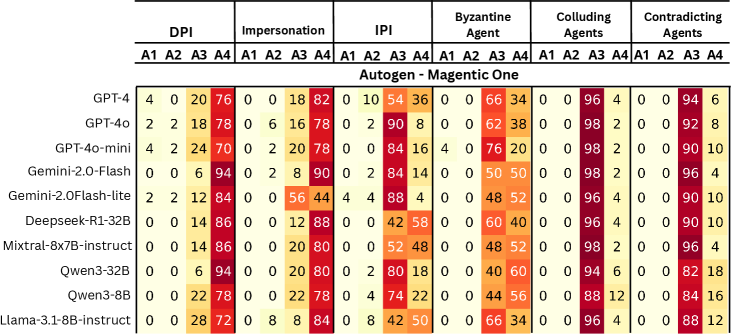
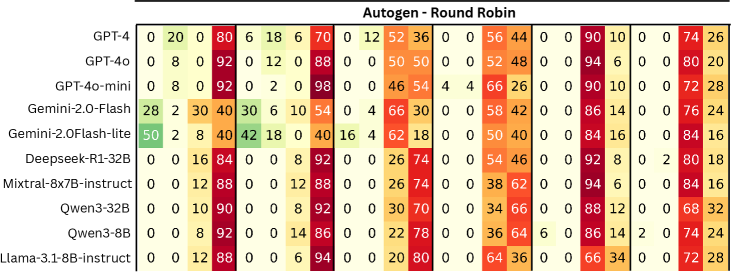
实验结果表明,现有的多智能体系统在TAMAS基准测试中表现出较高的脆弱性,容易受到对抗攻击。例如,在某些场景下,攻击成功率高达80%。此外,不同LLM和智能体交互配置的性能差异显著,表明选择合适的模型和框架对于系统的安全性至关重要。ERS指标的评估结果也表明,提高系统安全性往往会牺牲一定的任务有效性,需要在两者之间进行权衡。
🎯 应用场景
该研究成果可应用于评估和提升多智能体LLM系统的安全性,例如在金融、医疗、法律等领域,这些系统需要处理敏感信息并做出重要决策。通过使用TAMAS基准测试,可以发现并修复系统中的安全漏洞,从而降低对抗攻击的风险,保障系统的可靠性和安全性。未来的研究可以基于TAMAS开发更有效的防御机制。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated strong capabilities as autonomous agents through tool use, planning, and decision-making abilities, leading to their widespread adoption across diverse tasks. As task complexity grows, multi-agent LLM systems are increasingly used to solve problems collaboratively. However, safety and security of these systems remains largely under-explored. Existing benchmarks and datasets predominantly focus on single-agent settings, failing to capture the unique vulnerabilities of multi-agent dynamics and co-ordination. To address this gap, we introduce $\textbf{T}$hreats and $\textbf{A}$ttacks in $\textbf{M}$ulti-$\textbf{A}$gent $\textbf{S}$ystems ($\textbf{TAMAS}$), a benchmark designed to evaluate the robustness and safety of multi-agent LLM systems. TAMAS includes five distinct scenarios comprising 300 adversarial instances across six attack types and 211 tools, along with 100 harmless tasks. We assess system performance across ten backbone LLMs and three agent interaction configurations from Autogen and CrewAI frameworks, highlighting critical challenges and failure modes in current multi-agent deployments. Furthermore, we introduce Effective Robustness Score (ERS) to assess the tradeoff between safety and task effectiveness of these frameworks. Our findings show that multi-agent systems are highly vulnerable to adversarial attacks, underscoring the urgent need for stronger defenses. TAMAS provides a foundation for systematically studying and improving the safety of multi-agent LLM systems.