Generating Software Architecture Description from Source Code using Reverse Engineering and Large Language Model
作者: Ahmad Hatahet, Christoph Knieke, Andreas Rausch
分类: cs.SE, cs.AI
发布日期: 2025-11-07
💡 一句话要点
提出一种基于逆向工程和大型语言模型的软件架构描述自动生成方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 软件架构描述 逆向工程 大型语言模型 组件图 状态机图
📋 核心要点
- 当前软件架构描述(SADs)常缺失或过时,导致开发人员需耗时地从代码中推导架构,增加认知负担。
- 该方法结合逆向工程和大型语言模型,从源代码半自动生成SADs,提取组件图并建模组件行为。
- 通过C++示例验证,表明LLM能有效抽象组件图,准确表示复杂行为,减少人工干预并提升系统可维护性。
📝 摘要(中文)
软件架构描述(SADs)对于管理现代软件系统固有的复杂性至关重要。它们支持高层次的架构推理,指导设计决策,并促进不同利益相关者之间的有效沟通。然而,在实践中,SADs常常缺失、过时或与系统的实际实现不一致。因此,开发人员不得不直接从源代码中获取架构信息,这是一个耗时的过程,增加了认知负担,减缓了新开发人员的入职速度,并导致系统清晰度随着时间的推移而逐渐降低。为了解决这些问题,我们提出了一种通过将逆向工程(RE)技术与大型语言模型(LLM)相结合,从源代码中半自动生成SADs的方法。我们的方法通过提取全面的组件图,通过提示工程过滤架构上重要的元素(核心组件),并生成状态机图来建模基于底层代码逻辑的组件行为(通过少量样本提示),从而恢复静态和行为架构视图。由此产生的视图表示提供了一种可扩展且可维护的替代传统手动架构文档的方法。该方法使用C++示例进行了演示,突出了LLM的强大能力:1) 抽象组件图,从而减少对人类专家参与的依赖;2) 准确地表示复杂的软件行为,特别是当通过少量样本提示丰富领域特定知识时。这些发现表明,在显著减少人工工作量的同时,增强系统理解和长期可维护性是可行的。
🔬 方法详解
问题定义:论文旨在解决软件架构描述(SADs)缺失、过时或与实际代码不符的问题。现有方法依赖人工从代码中提取架构信息,费时费力,且易出错,难以维护。这增加了开发人员的认知负担,减缓了新成员的加入,并降低了系统的可理解性。
核心思路:论文的核心思路是利用逆向工程技术从源代码中提取架构信息,并借助大型语言模型(LLM)的抽象和推理能力,自动生成软件架构描述。通过逆向工程获取组件及其关系,再利用LLM对组件进行抽象和行为建模,从而减轻人工负担,提高SADs的准确性和可维护性。
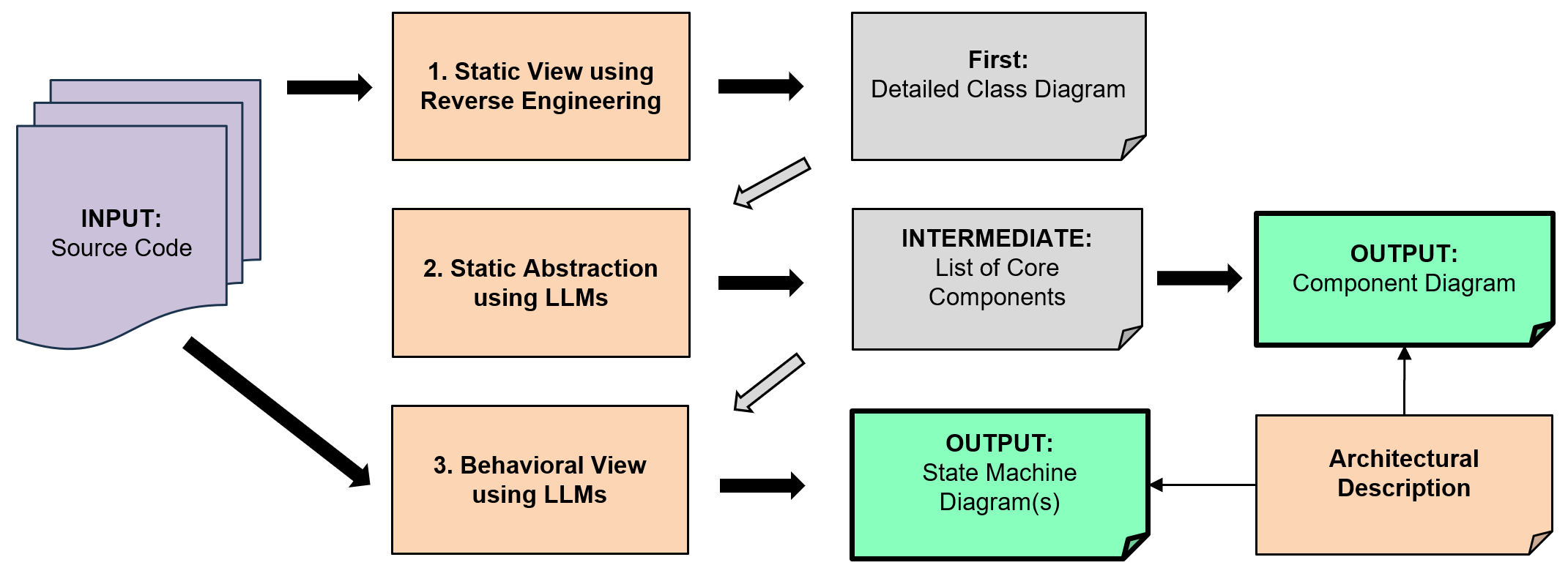
技术框架:该方法包含以下主要阶段:1) 逆向工程:从源代码中提取组件图,包括组件及其之间的依赖关系。2) 架构元素过滤:通过提示工程,利用LLM识别并过滤出架构上重要的核心组件。3) 行为建模:基于底层代码逻辑,使用少量样本提示,利用LLM生成状态机图来建模组件的行为。4) SADs生成:将提取的组件图和状态机图整合,生成最终的软件架构描述。
关键创新:该方法最重要的创新点在于将逆向工程与大型语言模型相结合,实现了软件架构描述的半自动生成。与传统的手动方法相比,该方法能够显著减少人工工作量,提高SADs的生成效率和准确性。此外,利用LLM进行组件抽象和行为建模,能够更好地捕捉软件系统的复杂性。
关键设计:在架构元素过滤阶段,通过精心设计的提示(prompt)引导LLM识别核心组件。在行为建模阶段,采用少量样本提示(few-shot prompting)的方式,向LLM提供一些示例代码和对应的状态机图,以提高LLM生成状态机图的准确性。具体使用的LLM模型和逆向工程工具未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
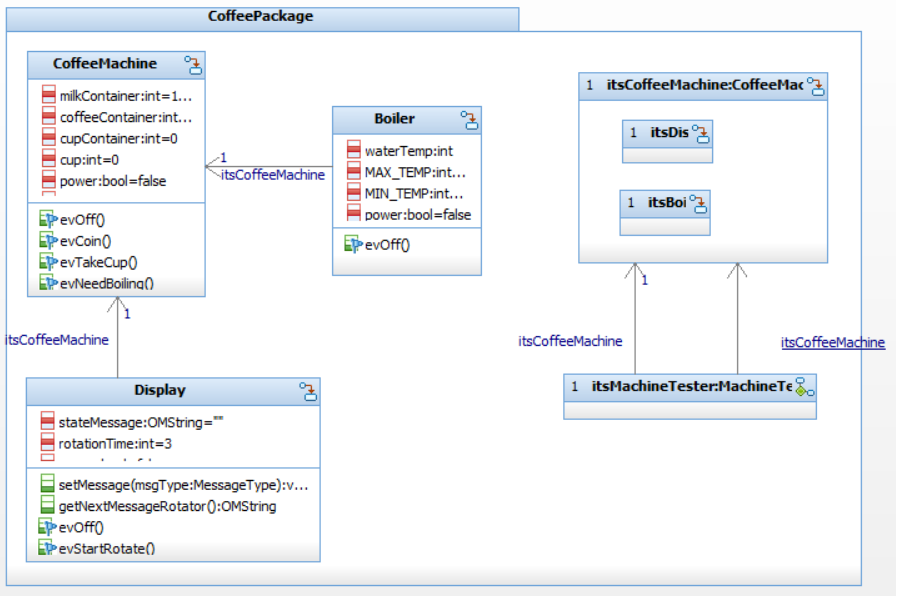
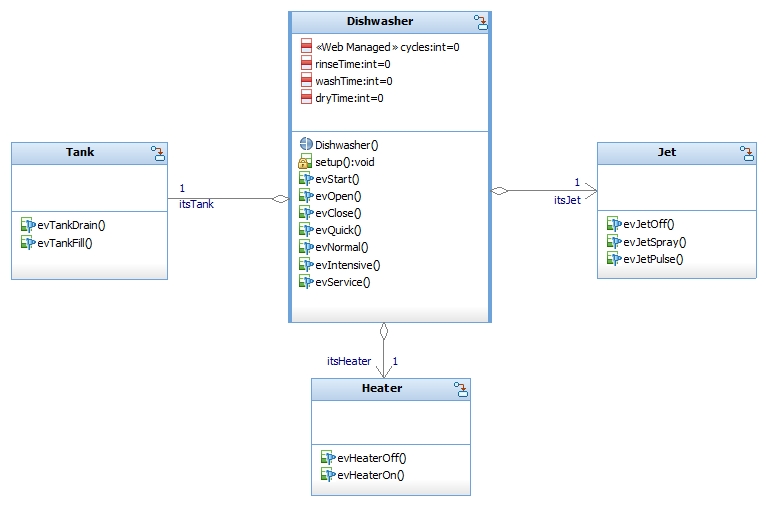
论文通过C++示例验证了该方法的有效性,表明LLM能够有效地抽象组件图,减少对人工专家的依赖。同时,通过少量样本提示,LLM能够准确地表示复杂的软件行为。虽然论文没有提供具体的性能数据和对比基线,但实验结果表明该方法能够显著减少人工工作量,并提高软件架构描述的准确性和可维护性。
🎯 应用场景
该研究成果可应用于软件开发和维护的各个阶段。在软件开发初期,可辅助架构师快速生成初始的架构描述。在软件维护阶段,可帮助开发人员理解现有系统的架构,并及时更新架构文档,确保其与代码保持一致。此外,该方法还可用于软件架构的自动化评估和重构,提高软件质量和可维护性。
📄 摘要(原文)
Software Architecture Descriptions (SADs) are essential for managing the inherent complexity of modern software systems. They enable high-level architectural reasoning, guide design decisions, and facilitate effective communication among diverse stakeholders. However, in practice, SADs are often missing, outdated, or poorly aligned with the system's actual implementation. Consequently, developers are compelled to derive architectural insights directly from source code-a time-intensive process that increases cognitive load, slows new developer onboarding, and contributes to the gradual degradation of clarity over the system's lifetime. To address these issues, we propose a semi-automated generation of SADs from source code by integrating reverse engineering (RE) techniques with a Large Language Model (LLM). Our approach recovers both static and behavioral architectural views by extracting a comprehensive component diagram, filtering architecturally significant elements (core components) via prompt engineering, and generating state machine diagrams to model component behavior based on underlying code logic with few-shots prompting. This resulting views representation offer a scalable and maintainable alternative to traditional manual architectural documentation. This methodology, demonstrated using C++ examples, highlights the potent capability of LLMs to: 1) abstract the component diagram, thereby reducing the reliance on human expert involvement, and 2) accurately represent complex software behaviors, especially when enriched with domain-specific knowledge through few-shot prompting. These findings suggest a viable path toward significantly reducing manual effort while enhancing system understanding and long-term maintainability.