Enhancing Public Speaking Skills in Engineering Students Through AI
作者: Amol Harsh, Brainerd Prince, Siddharth Siddharth, Deepan Raj Prabakar Muthirayan, Kabir S Bhalla, Esraaj Sarkar Gupta, Siddharth Sahu
分类: cs.HC, cs.AI, cs.CL
发布日期: 2025-11-07
💡 一句话要点
提出基于多模态AI的公共演讲评估系统,提升工科学生沟通能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 公共演讲 AI评估 多模态融合 语音分析 计算机视觉 情感检测 Gemini Pro
📋 核心要点
- 工科学生普遍缺乏有效的公共演讲能力,而传统教学方式难以提供个性化和持续的训练。
- 论文提出一种多模态AI系统,融合语音分析、计算机视觉和情感检测,对学生的口头和非语言表达进行综合评估。
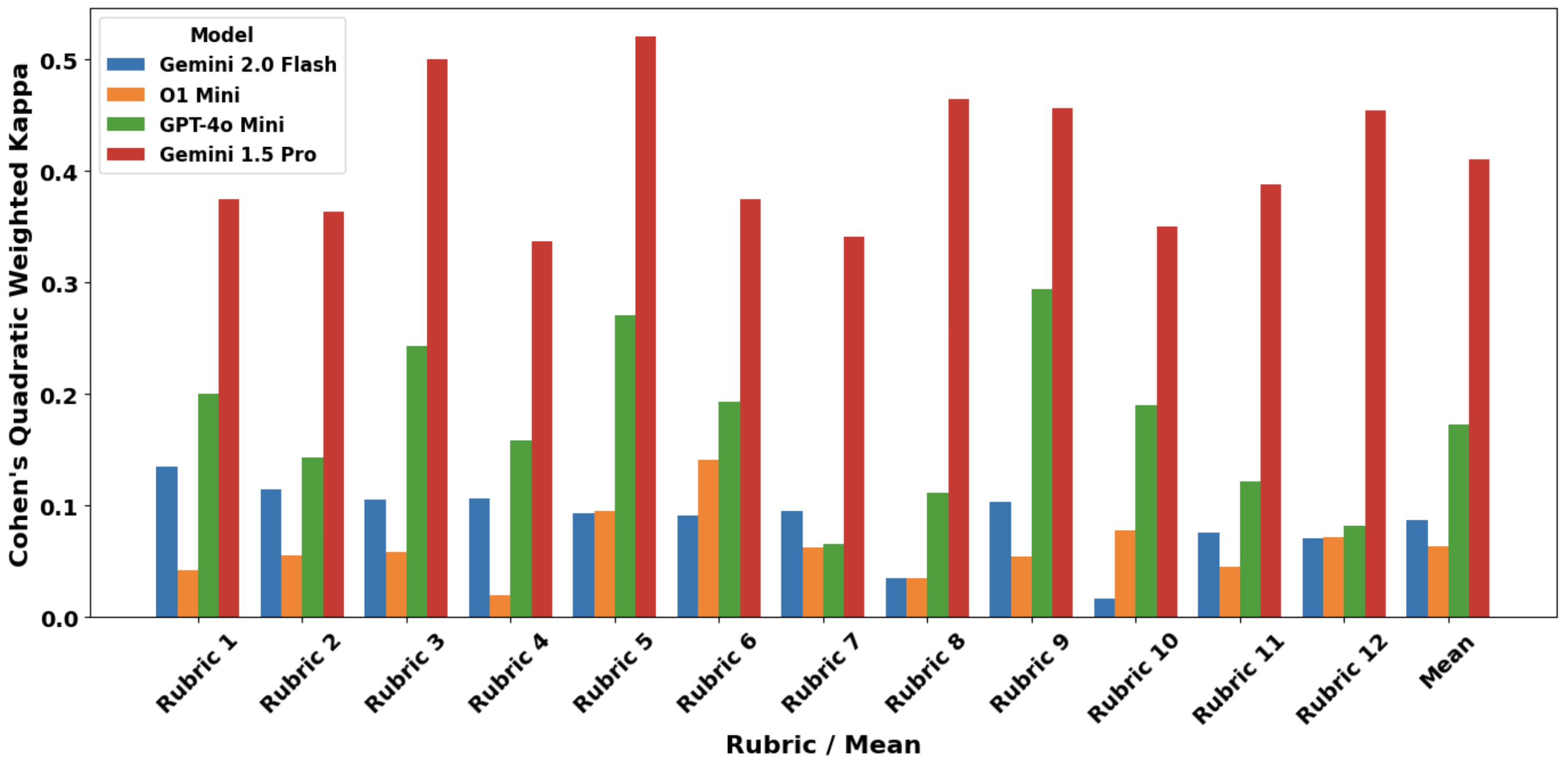
- 初步实验表明,该AI系统生成的反馈与专家评估具有一定程度的一致性,Gemini Pro模型表现最佳。
📝 摘要(中文)
本研究旨在解决工科学生有效沟通的挑战。公共演讲是未来工程师必备技能,但高校难以提供持续和个性化的训练。人工评估耗时且难以规模化。本研究融合语音分析、计算机视觉和情感检测,开发了一个多模态AI评估模型,用于评估学生的公共演讲能力。该模型评估(1)口头交流(音高、响度、节奏、语调),(2)非语言交流(面部表情、手势、姿势),以及(3)表达连贯性,即言语和肢体语言的一致性。与以往独立评估这些方面的系统不同,该模型融合多种模态,提供个性化、可扩展的反馈。初步测试表明,AI生成的反馈与专家评估具有中等程度的一致性。在包括Gemini和OpenAI模型在内的多个大型语言模型(LLM)中,Gemini Pro表现最佳,与人类标注者的一致性最高。该AI驱动的公共演讲训练器无需人工评估,使学生能够重复练习,自然地协调言语、肢体语言和情感,这对有效和专业的沟通至关重要。
🔬 方法详解
问题定义:工程专业的学生在公共演讲方面面临挑战,他们需要向不同的利益相关者传达技术知识。然而,传统的教学方法,如课程或研讨会,无法提供持续和个性化的训练。人工评估需要大量时间,并且难以对学生的口头和非语言表达进行全面评估。
核心思路:本研究的核心思路是利用人工智能技术,特别是多模态融合的方法,构建一个能够自动评估学生公共演讲能力并提供个性化反馈的系统。通过整合语音分析、计算机视觉和情感检测等技术,系统可以全面地评估学生的口头表达、非语言表达以及表达的连贯性。
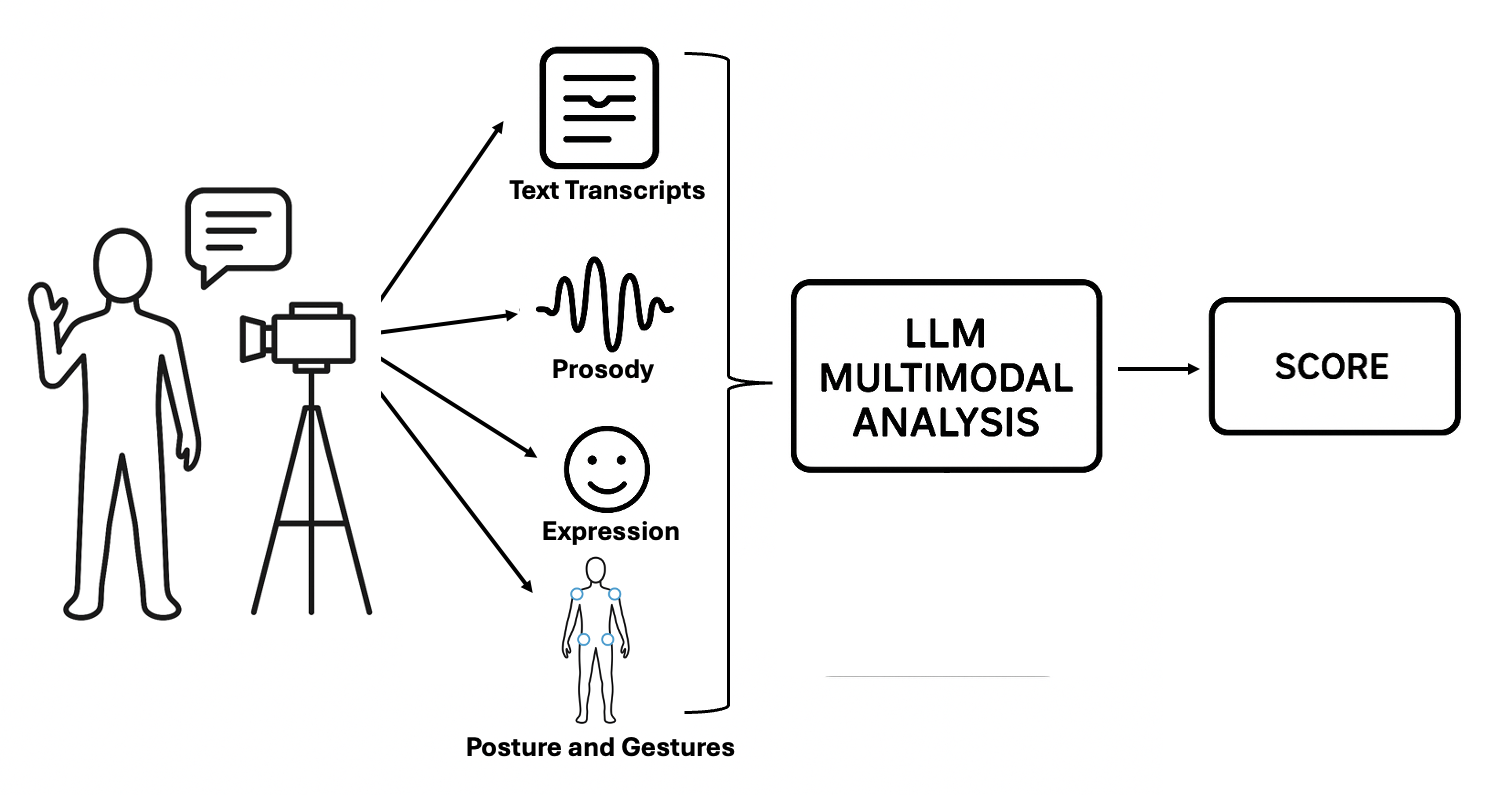
技术框架:该AI系统的整体框架包含以下几个主要模块:1) 语音分析模块:用于分析学生的音高、响度、节奏和语调等口头表达特征。2) 计算机视觉模块:用于分析学生的面部表情、手势和姿势等非语言表达特征。3) 情感检测模块:用于检测学生在演讲过程中表达的情感。4) 表达连贯性评估模块:用于评估学生的言语和肢体语言是否一致。5) 反馈生成模块:根据评估结果,生成个性化的反馈报告。
关键创新:该研究的关键创新在于将多种模态的信息融合在一起,从而实现对学生公共演讲能力的全面评估。与以往的系统只关注口头表达或非语言表达不同,该系统能够同时评估这两个方面,并且能够评估学生的表达连贯性。此外,该系统还利用了最新的大型语言模型(LLM),如Gemini Pro,来提高评估的准确性。
关键设计:在语音分析模块中,使用了语音识别和语音特征提取技术。在计算机视觉模块中,使用了人脸检测、姿态估计和动作识别等技术。在情感检测模块中,使用了情感分类模型。表达连贯性评估模块的设计细节未知,但推测可能使用了某种对齐算法来比较语音和视觉信息。论文中提到Gemini Pro表现最佳,但没有详细说明如何将其集成到系统中。
🖼️ 关键图片
📊 实验亮点
初步测试表明,该AI系统生成的反馈与专家评估具有中等程度的一致性。在多个大型语言模型(LLM)的对比实验中,Gemini Pro表现最佳,与人类标注者的一致性最高。这表明该AI系统具有一定的实用价值,可以为学生提供有效的公共演讲训练。
🎯 应用场景
该研究成果可应用于高校的工程教育中,为学生提供个性化的公共演讲训练。此外,该系统还可以应用于企业培训、职业发展等领域,帮助员工提升沟通能力。未来,该系统可以进一步扩展,支持更多语言和文化背景,并提供更丰富的反馈形式。
📄 摘要(原文)
This research-to-practice full paper was inspired by the persistent challenge in effective communication among engineering students. Public speaking is a necessary skill for future engineers as they have to communicate technical knowledge with diverse stakeholders. While universities offer courses or workshops, they are unable to offer sustained and personalized training to students. Providing comprehensive feedback on both verbal and non-verbal aspects of public speaking is time-intensive, making consistent and individualized assessment impractical. This study integrates research on verbal and non-verbal cues in public speaking to develop an AI-driven assessment model for engineering students. Our approach combines speech analysis, computer vision, and sentiment detection into a multi-modal AI system that provides assessment and feedback. The model evaluates (1) verbal communication (pitch, loudness, pacing, intonation), (2) non-verbal communication (facial expressions, gestures, posture), and (3) expressive coherence, a novel integration ensuring alignment between speech and body language. Unlike previous systems that assess these aspects separately, our model fuses multiple modalities to deliver personalized, scalable feedback. Preliminary testing demonstrated that our AI-generated feedback was moderately aligned with expert evaluations. Among the state-of-the-art AI models evaluated, all of which were Large Language Models (LLMs), including Gemini and OpenAI models, Gemini Pro emerged as the best-performing, showing the strongest agreement with human annotators. By eliminating reliance on human evaluators, this AI-driven public speaking trainer enables repeated practice, helping students naturally align their speech with body language and emotion, crucial for impactful and professional communication.