MalDataGen: A Modular Framework for Synthetic Tabular Data Generation in Malware Detection
作者: Kayua Oleques Paim, Angelo Gaspar Diniz Nogueira, Diego Kreutz, Weverton Cordeiro, Rodrigo Brandao Mansilha
分类: cs.CR, cs.AI, cs.LG
发布日期: 2025-11-01
备注: 10 pages, 6 figures, 2 tables. Published at the Brazilian Symposium on Cybersecurity (SBSeg 2025)
DOI: 10.5753/sbseg_estendido.2025.12113
💡 一句话要点
提出MalDataGen框架,用于生成高质量恶意软件检测合成表格数据。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 恶意软件检测 合成数据生成 深度学习 WGAN-GP VQ-VAE 数据增强 网络安全
📋 核心要点
- 恶意软件检测受限于高质量数据的匮乏,严重影响机器学习模型的检测效果。
- MalDataGen框架通过模块化的深度学习模型,生成高保真度的合成表格数据,缓解数据稀缺问题。
- 实验结果表明,MalDataGen在数据效用性上优于现有基准方法,并能有效提升恶意软件检测性能。
📝 摘要(中文)
恶意软件检测面临高质量数据稀缺的挑战,这限制了机器学习模型的性能。本文介绍MalDataGen,一个开源的模块化框架,用于生成高保真度的合成表格数据。该框架采用模块化的深度学习模型(例如WGAN-GP、VQ-VAE)。通过双重验证(TR-TS/TS-TR)、七种分类器和效用指标进行评估,MalDataGen在保持数据效用的同时,优于SDV等基准方法。其灵活的设计使其能够无缝集成到检测流程中,为网络安全应用提供了一个实用的解决方案。
🔬 方法详解
问题定义:恶意软件检测领域面临着高质量数据稀缺的挑战。现有的真实恶意软件数据集往往难以获取,且可能存在偏差。直接使用这些数据训练的模型泛化能力有限。因此,需要一种方法来生成高质量的合成数据,以扩充训练集,提高模型的鲁棒性和泛化能力。
核心思路:MalDataGen的核心思路是利用深度生成模型,学习真实恶意软件数据的分布,并生成具有相似特征的合成数据。通过模块化的设计,允许用户灵活选择不同的生成模型(如WGAN-GP、VQ-VAE),并针对特定数据集进行定制。这种方法旨在生成既能保持数据效用,又能避免泄露敏感信息的合成数据。
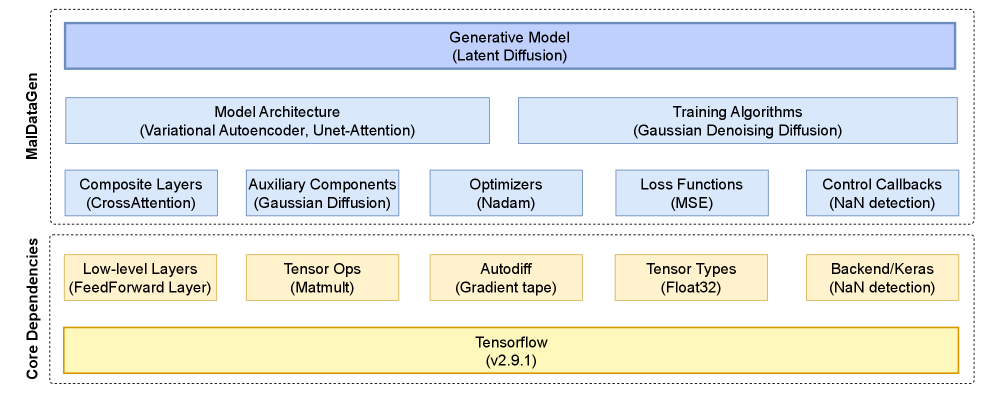
技术框架:MalDataGen框架主要包含以下几个模块:数据预处理模块、生成模型选择模块、模型训练模块和数据评估模块。首先,对真实恶意软件数据进行预处理,包括特征选择、数据清洗等。然后,用户可以根据需求选择合适的生成模型,例如WGAN-GP或VQ-VAE。接下来,使用预处理后的真实数据训练选定的生成模型。最后,使用多种指标评估生成数据的质量和效用,例如通过训练分类器进行双重验证(TR-TS/TS-TR)。
关键创新:MalDataGen的关键创新在于其模块化的设计和对深度生成模型的灵活应用。传统的合成数据生成方法往往依赖于特定的模型或算法,缺乏灵活性。MalDataGen通过模块化的设计,允许用户根据具体任务和数据集的特点,选择最合适的生成模型。此外,该框架还提供了多种评估指标,帮助用户评估生成数据的质量和效用。
关键设计:MalDataGen框架支持多种深度生成模型,例如WGAN-GP和VQ-VAE。对于WGAN-GP,关键的设计包括梯度惩罚项的设置,以保证训练的稳定性。对于VQ-VAE,关键的设计包括码本大小的选择和损失函数的设置,以平衡重构误差和码本利用率。此外,框架还提供了多种数据预处理方法,例如特征缩放和离散化,以提高生成模型的训练效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MalDataGen生成的合成数据在双重验证(TR-TS/TS-TR)中,使用七种分类器进行评估,其性能优于SDV等基准方法。这表明MalDataGen能够生成高质量的合成数据,并有效提升恶意软件检测模型的性能。具体的性能提升幅度取决于所使用的生成模型和数据集。
🎯 应用场景
MalDataGen可应用于恶意软件检测模型的训练数据增强,提高模型检测率和泛化能力。此外,该框架还可用于生成对抗样本,评估模型的鲁棒性。在网络安全教育领域,MalDataGen可以用于创建模拟的恶意软件数据集,供学生学习和实践。
📄 摘要(原文)
High-quality data scarcity hinders malware detection, limiting ML performance. We introduce MalDataGen, an open-source modular framework for generating high-fidelity synthetic tabular data using modular deep learning models (e.g., WGAN-GP, VQ-VAE). Evaluated via dual validation (TR-TS/TS-TR), seven classifiers, and utility metrics, MalDataGen outperforms benchmarks like SDV while preserving data utility. Its flexible design enables seamless integration into detection pipelines, offering a practical solution for cybersecurity applications.