Better Call CLAUSE: A Discrepancy Benchmark for Auditing LLMs Legal Reasoning Capabilities
作者: Manan Roy Choudhury, Adithya Chandramouli, Mannan Anand, Vivek Gupta
分类: cs.AI
发布日期: 2025-11-01 (更新: 2026-01-07)
备注: 42 pages, 4 images
💡 一句话要点
CLAUSE:用于审计LLM法律推理能力的差异性基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法律人工智能 大型语言模型 基准测试 合同分析 法律推理
📋 核心要点
- 现有法律领域的大语言模型缺乏针对合同中细微法律错误的系统性测试基准。
- CLAUSE基准通过生成包含多种异常的扰动合同,评估LLM检测和解释法律缺陷的能力。
- 实验表明,即使是领先的LLM也难以发现合同中的细微法律错误,并给出合理的法律解释。
📝 摘要(中文)
大型语言模型(LLM)正迅速融入高风险的法律工作中,但一个关键问题日益凸显:缺乏系统性的基准来测试它们在真实合同中存在的细微、对抗性和隐蔽缺陷面前的可靠性。为了解决这个问题,我们推出了CLAUSE,这是一个首创的基准,旨在评估LLM法律推理的脆弱性。我们通过从CUAD和ContractNLI等基础数据集中生成超过7500份真实扰动合同,研究LLM检测和推理细粒度差异的能力。我们新颖的、以角色驱动的流程生成10个不同的异常类别,然后使用检索增强生成(RAG)系统对照官方法规进行验证,以确保法律的准确性。我们使用CLAUSE来评估领先的LLM检测嵌入式法律缺陷并解释其重要性的能力。我们的分析显示了一个关键弱点:这些模型经常错过细微的错误,并且更难在法律上证明其合理性。我们的工作概述了一条识别和纠正法律AI中此类推理失败的途径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在法律领域应用时,缺乏有效评估其法律推理能力的基准测试的问题。现有方法无法充分测试LLM在处理真实合同中存在的细微、对抗性和隐蔽缺陷时的可靠性,这限制了LLM在法律领域的安全应用。
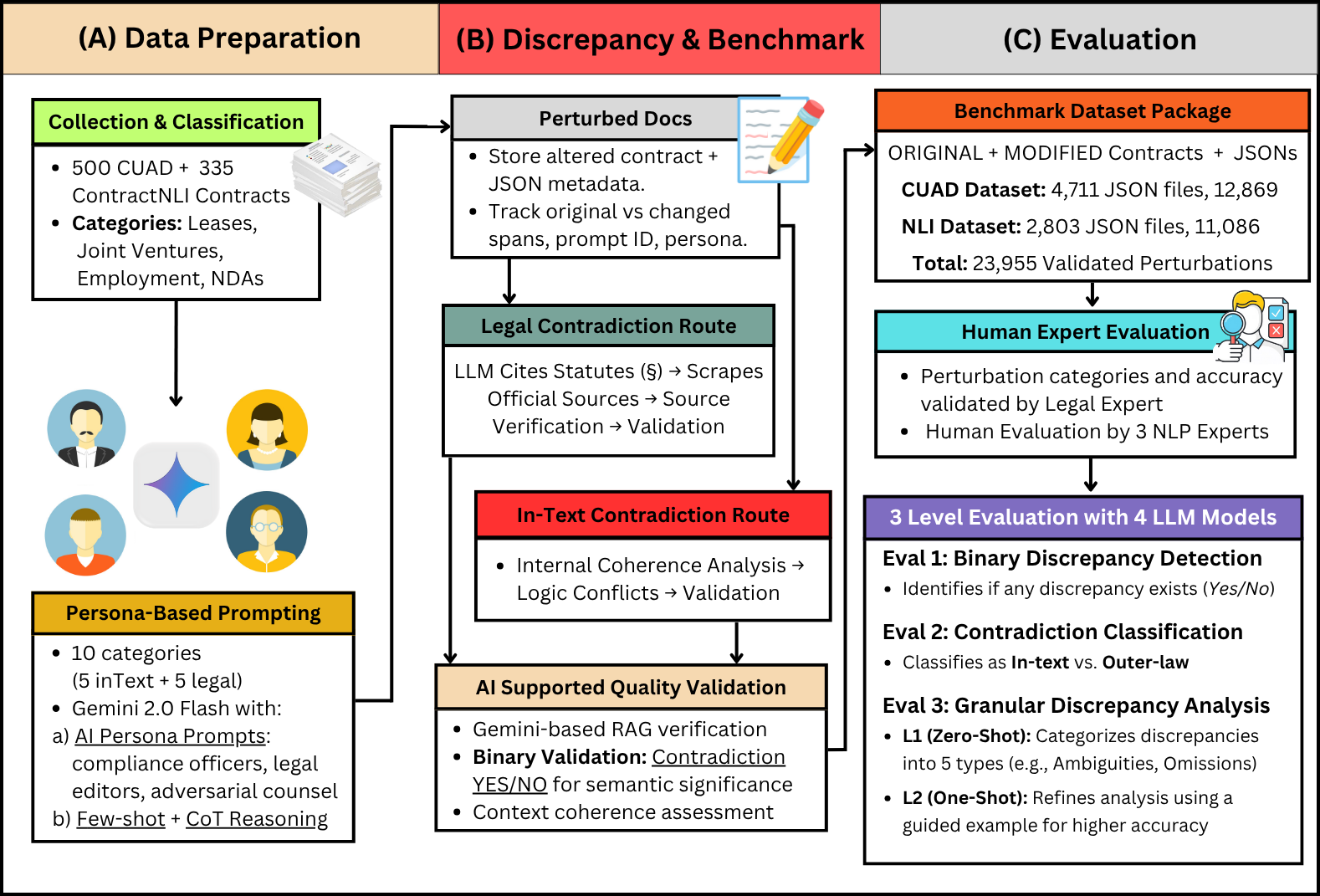
核心思路:论文的核心思路是构建一个专门用于评估LLM法律推理能力的差异性基准测试,即CLAUSE。该基准通过生成包含多种法律异常的扰动合同,来考察LLM识别和解释这些异常的能力。通过这种方式,可以系统性地评估LLM在处理真实法律文本时的脆弱性。
技术框架:CLAUSE基准的构建流程主要包括以下几个阶段:1) 从CUAD和ContractNLI等数据集收集真实合同文本;2) 通过一个以角色驱动的流程生成10种不同类型的法律异常,对合同文本进行扰动;3) 使用检索增强生成(RAG)系统,对照官方法规验证生成的异常的法律有效性;4) 使用生成的扰动合同作为测试用例,评估LLM检测和解释法律缺陷的能力。
关键创新:CLAUSE基准的关键创新在于其专门针对法律领域,并着重考察LLM对细微法律差异的识别和解释能力。与现有的通用型基准测试相比,CLAUSE更能够反映LLM在处理真实法律问题时的实际表现。此外,论文提出的基于角色驱动的异常生成流程和基于RAG的法律有效性验证方法,也为构建高质量的法律领域基准测试提供了新的思路。
关键设计:论文的关键设计包括:1) 10种不同类型的法律异常,涵盖了合同中常见的错误和漏洞;2) 基于角色驱动的异常生成流程,模拟了真实合同起草过程中的各种人为错误;3) 基于RAG的法律有效性验证方法,确保生成的异常在法律上是有效的,避免了引入无效的测试用例。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
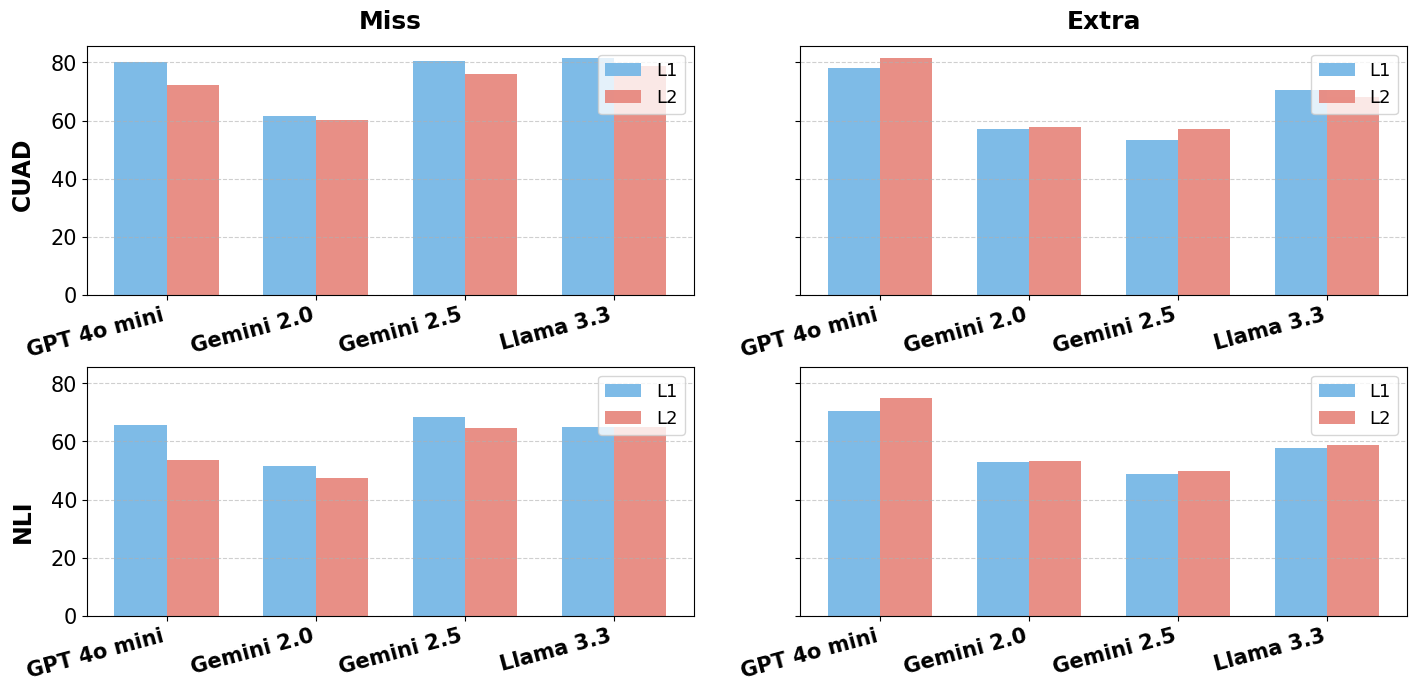
CLAUSE基准测试表明,即使是领先的LLM也难以准确检测和解释合同中细微的法律错误。实验结果显示,LLM在识别法律缺陷方面的能力远低于预期,并且在提供合理的法律解释方面表现更差。这些发现突显了当前LLM在法律推理方面的局限性,并为未来的研究方向提供了重要启示。
🎯 应用场景
该研究成果可应用于法律人工智能的开发与评估,帮助开发者识别和改进LLM在法律推理方面的不足。律师和法律从业者可以使用该基准来评估LLM在合同审查、法律咨询等方面的可靠性,从而更安全地利用AI技术提高工作效率。未来,该研究可以扩展到其他法律领域,例如知识产权、侵权责任等。
📄 摘要(原文)
The rapid integration of large language models (LLMs) into high-stakes legal work has exposed a critical gap: no benchmark exists to systematically stress-test their reliability against the nuanced, adversarial, and often subtle flaws present in real-world contracts. To address this, we introduce CLAUSE, a first-of-its-kind benchmark designed to evaluate the fragility of an LLM's legal reasoning. We study the capabilities of LLMs to detect and reason about fine-grained discrepancies by producing over 7500 real-world perturbed contracts from foundational datasets like CUAD and ContractNLI. Our novel, persona-driven pipeline generates 10 distinct anomaly categories, which are then validated against official statutes using a Retrieval-Augmented Generation (RAG) system to ensure legal fidelity. We use CLAUSE to evaluate leading LLMs' ability to detect embedded legal flaws and explain their significance. Our analysis shows a key weakness: these models often miss subtle errors and struggle even more to justify them legally. Our work outlines a path to identify and correct such reasoning failures in legal AI.