LLM2IR: simple unsupervised contrastive learning makes long-context LLM great retriever
作者: Xiaocong Yang
分类: cs.IR, cs.AI, cs.CL
发布日期: 2025-10-31
备注: MS Thesis
💡 一句话要点
LLM2IR:简单无监督对比学习使长文本LLM成为卓越的检索器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息检索 大型语言模型 对比学习 无监督学习 长文本检索
📋 核心要点
- 现代稠密信息检索模型通常依赖于昂贵的大规模预训练,成本高昂且效率较低。
- LLM2IR框架通过简单的无监督对比学习,将任意仅解码器LLM转化为信息检索模型。
- 实验表明,该方法在多个IR基准测试中有效,且更长的上下文长度往往带来更强的IR能力。
📝 摘要(中文)
本文介绍了一种名为LLM2IR的高效无监督对比学习框架,该框架可以将任何仅解码器的大型语言模型(LLM)转换为信息检索模型。尽管其方法简单,但其有效性已在包括LoCo、LongEmbed和BEIR在内的多个IR基准测试中得到了不同LLM的验证。我们还发现,通过比较同一模型系列中模型的任务性能,具有更长上下文长度的模型往往具有更强的IR能力。我们的工作不仅提供了一种在最先进的LLM上构建IR模型的有效方法,而且揭示了信息检索能力和模型上下文长度之间的关系,这有助于设计更好的信息检索器。
🔬 方法详解
问题定义:现有稠密信息检索模型依赖大规模预训练,计算成本高昂。如何高效地利用现有的大型语言模型(LLM)构建高性能的信息检索模型,同时降低训练成本,是本文要解决的核心问题。现有方法难以充分利用LLM的上下文理解能力,且训练过程复杂。
核心思路:LLM2IR的核心思路是利用无监督对比学习,将LLM转化为信息检索模型。通过对比学习,模型学习区分相似和不相似的文档,从而获得更好的检索能力。这种方法避免了大规模的标注数据需求,降低了训练成本。
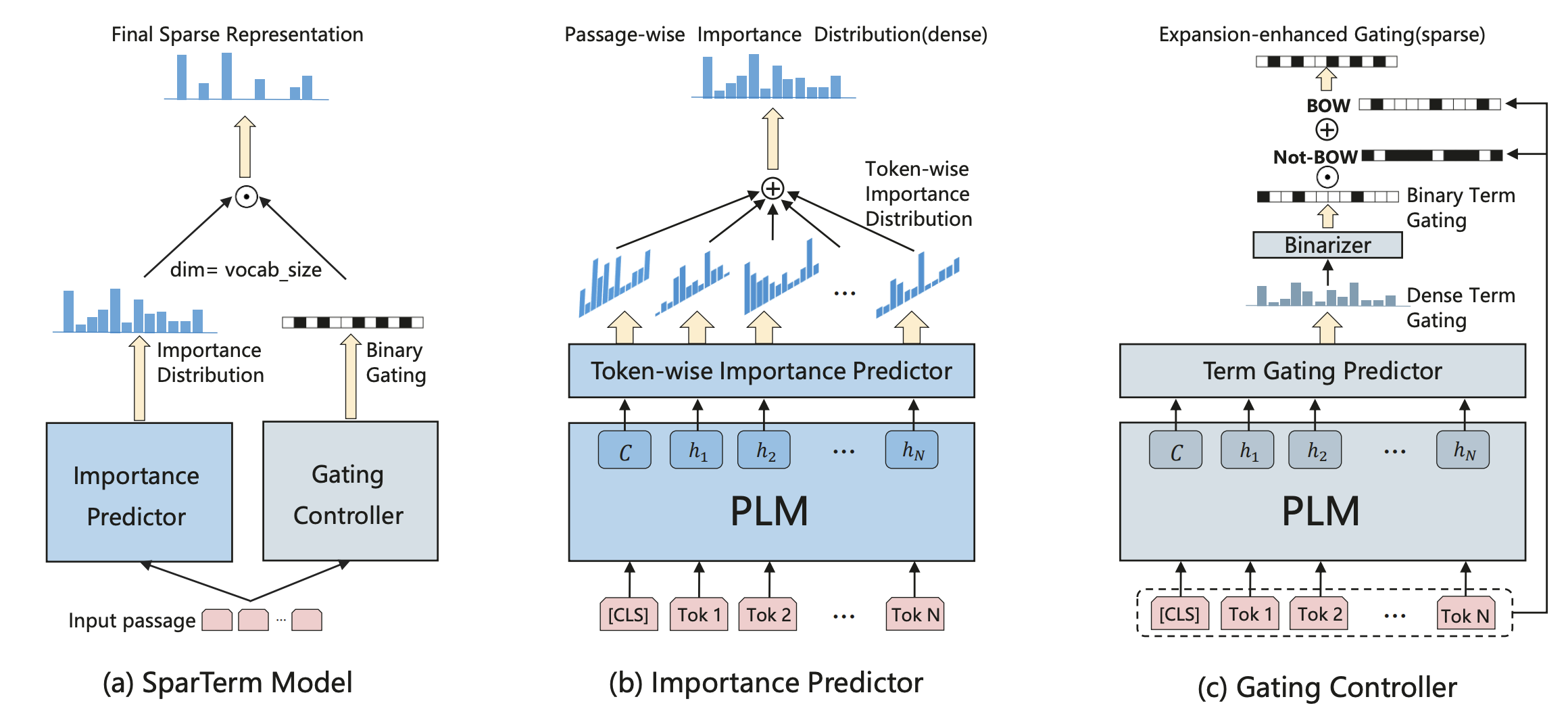
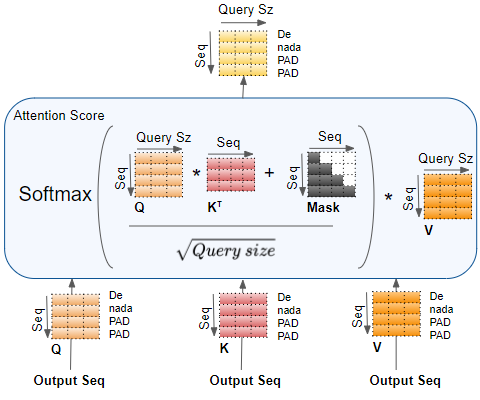
技术框架:LLM2IR框架主要包含以下几个阶段:1) 使用LLM对文档进行编码,生成文档的向量表示。2) 构建正负样本对,正样本通常是同一文档的不同片段,负样本是随机选择的其他文档片段。3) 使用对比损失函数训练模型,目标是拉近正样本对的距离,推远负样本对的距离。4) 使用训练好的模型进行信息检索,通过计算查询和文档向量的相似度来排序文档。
关键创新:LLM2IR的关键创新在于其简单性和有效性。它无需复杂的预训练过程,仅通过无监督对比学习即可将LLM转化为高性能的信息检索模型。此外,该研究还揭示了模型上下文长度与信息检索能力之间的关系,为设计更好的信息检索器提供了新的思路。
关键设计:LLM2IR的关键设计包括:1) 使用余弦相似度作为文档向量之间的相似度度量。2) 采用InfoNCE损失函数作为对比损失函数,鼓励模型学习区分正负样本。3) 实验中探索了不同的LLM架构和上下文长度,以评估LLM2IR的性能。4) 负样本的选择策略对模型性能有重要影响,实验中采用了随机负采样策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM2IR在LoCo、LongEmbed和BEIR等多个IR基准测试中取得了显著的性能提升。特别是在长文本检索任务中,LLM2IR表现出强大的竞争力。研究还发现,具有更长上下文长度的LLM通常具有更强的IR能力,这为未来的模型设计提供了重要的指导。
🎯 应用场景
LLM2IR具有广泛的应用前景,可应用于搜索引擎、问答系统、推荐系统等领域。该方法可以帮助企业和研究机构快速构建高性能的信息检索系统,降低开发成本。此外,该研究对于理解LLM的内在能力以及如何更好地利用LLM进行信息检索具有重要的理论价值。
📄 摘要(原文)
Modern dense information retrieval (IR) models usually rely on costly large-scale pretraining. In this paper, we introduce LLM2IR, an efficient unsupervised contrastive learning framework to convert any decoder-only large language model (LLM) to an information retrieval model. Despite its simplicity, the effectiveness is proven among different LLMs on multiple IR benchmarks including LoCo, LongEmbed and BEIR. We also find that models with a longer context length tend to have a stronger IR capacity by comparing task performances of models in the same model family. Our work not only provides an effective way to build IR models on the state-of-the-art LLMs, but also shed light on the relationship between information retrieval ability and model context length, which helps the design of better information retrievers.