Scalable Processing-Near-Memory for 1M-Token LLM Inference: CXL-Enabled KV-Cache Management Beyond GPU Limits
作者: Dowon Kim, MinJae Lee, Janghyeon Kim, HyuckSung Kwon, Hyeonggyu Jeong, Sang-Soo Park, Minyong Yoon, Si-Dong Roh, Yongsuk Kwon, Jinin So, Jungwook Choi
分类: cs.AR, cs.AI
发布日期: 2025-10-31
💡 一句话要点
提出基于CXL的PNM架构,加速百万Token LLM推理,突破GPU显存限制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文LLM 近内存计算 CXL KV缓存 推理加速
📋 核心要点
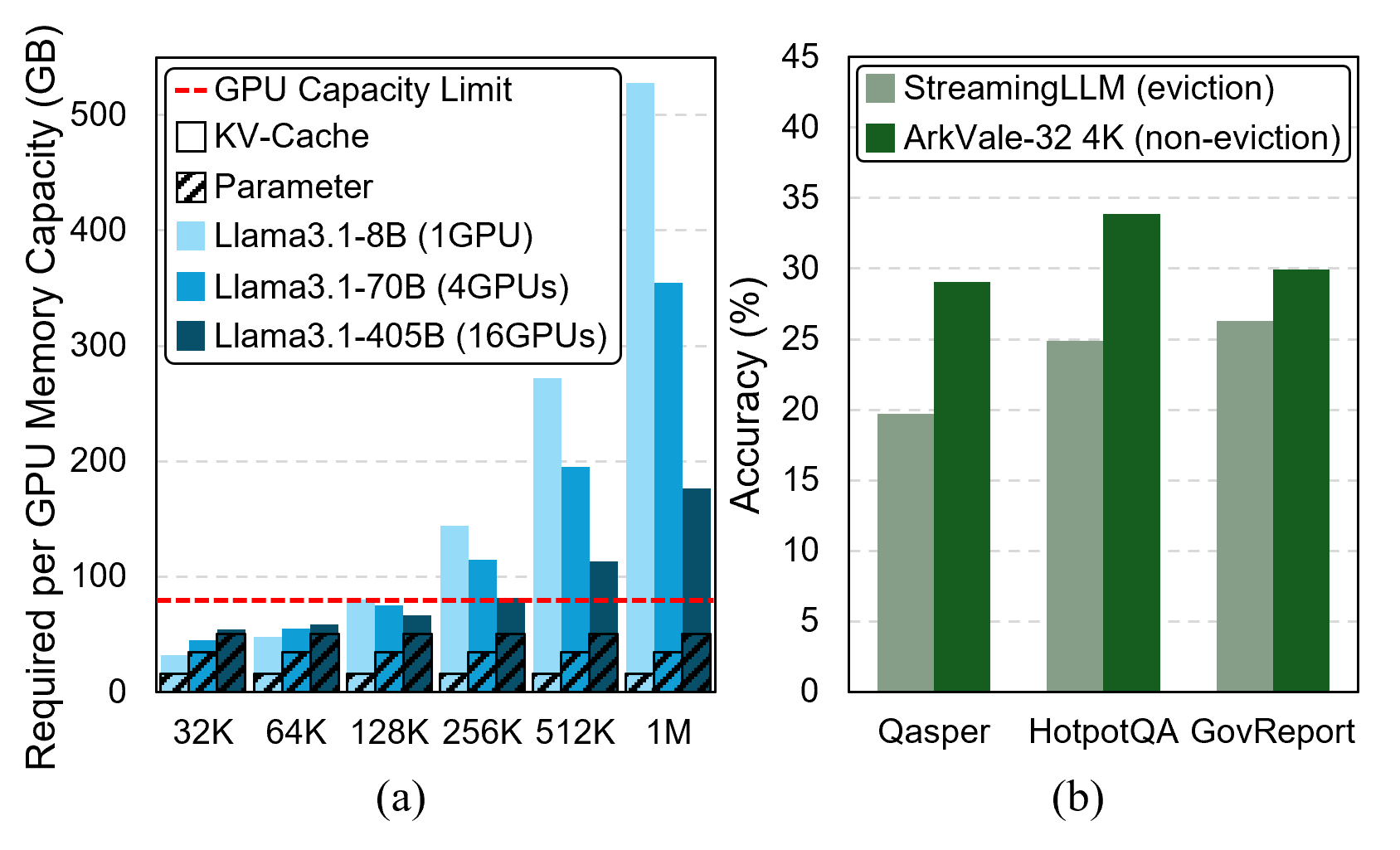
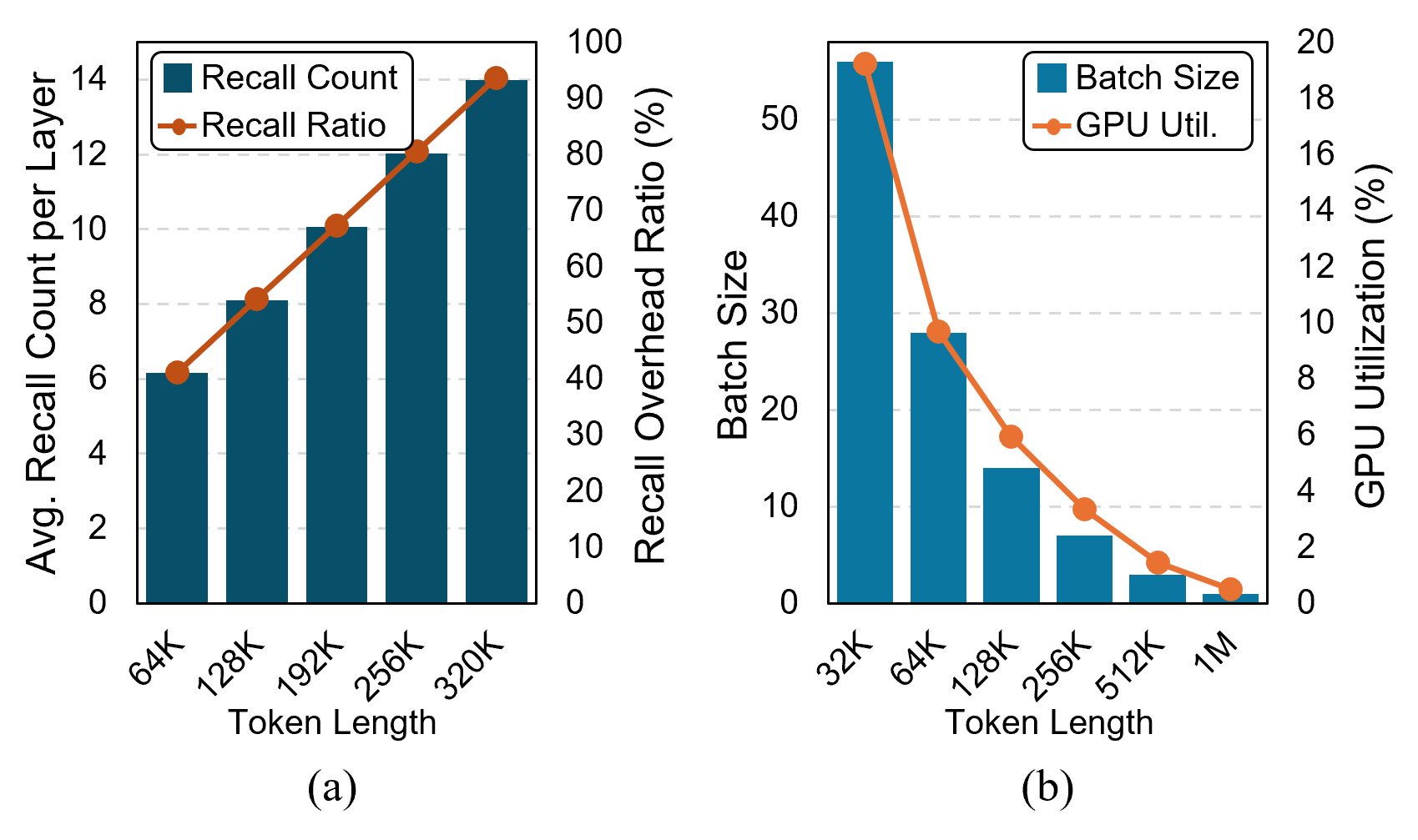
- 现有LLM长上下文推理面临KV缓存管理的内存和计算瓶颈,频繁的数据传输导致性能下降。
- 提出一种基于CXL的PNM架构,将token选择卸载到PNM加速器,减少GPU数据传输,提高批处理大小。
- 实验结果表明,该方案在405B参数和1M token上下文的LLM上,吞吐量提升高达21.9倍,能耗降低高达60倍。
📝 摘要(中文)
大型语言模型(LLM)中上下文窗口扩展到数百万token,带来了严重的内存和计算瓶颈,尤其是在管理不断增长的Key-Value(KV)缓存时。虽然Compute Express Link(CXL)支持非驱逐框架,可以将完整的KV缓存卸载到可扩展的外部内存,但随着上下文长度的增加,当将非常驻KV token召回到有限的GPU内存时,这些框架仍然会遭受昂贵的数据传输。本文提出了一种可扩展的近内存处理(PNM)方案,用于百万Token LLM推理,这是一种基于CXL的KV缓存管理系统,可协调GPU限制之外的内存和计算。我们的设计将token页面选择卸载到CXL内存中的PNM加速器,消除了昂贵的召回,并实现了更大的GPU批处理大小。我们进一步引入了一种混合并行化策略和一种稳定token选择机制,以提高计算效率和可扩展性。我们的解决方案在最先进的CXL-PNM系统之上实现,为具有高达405B参数和1M token上下文的LLM提供了持续的性能提升。我们的纯PNM卸载方案(PNM-KV)和具有稳定token执行的GPU-PNM混合方案(PnG-KV)实现了高达21.9倍的吞吐量提升,每token能耗降低高达60倍,总成本效率比基线提高高达7.3倍,这表明基于CXL的多PNM架构可以作为未来长上下文LLM推理的可扩展骨干。
🔬 方法详解
问题定义:现有LLM在处理长上下文时,KV缓存规模巨大,超出GPU显存容量。传统的KV缓存管理方法需要在GPU和外部存储之间频繁传输数据,导致推理速度显著下降,成为长上下文LLM推理的瓶颈。
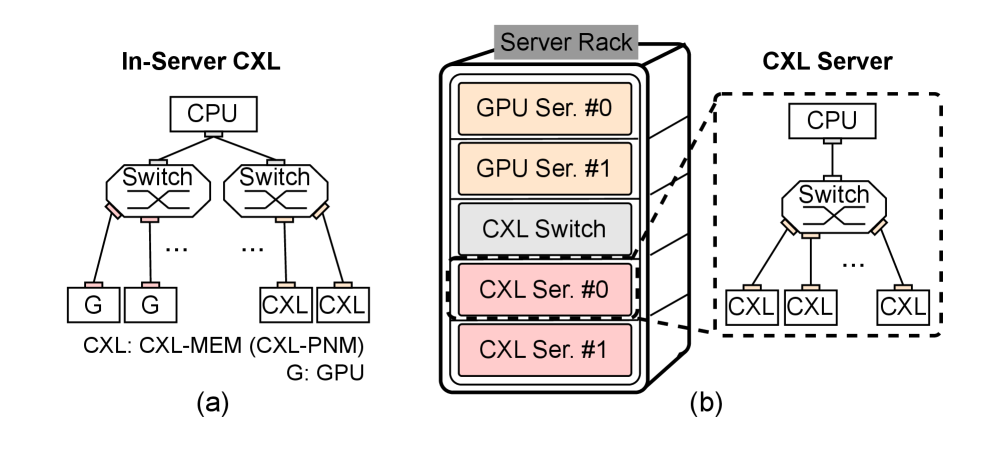
核心思路:利用CXL提供的近内存计算能力,将KV缓存管理的部分计算任务卸载到CXL内存附近的PNM加速器上。通过在PNM上进行token选择,减少了GPU和外部存储之间的数据传输量,从而提高了推理效率。
技术框架:该方案包含以下主要模块:1) CXL内存:用于存储KV缓存;2) PNM加速器:负责token页面选择等计算任务;3) GPU:执行LLM的核心计算;4) 混合并行化策略:结合数据并行和流水线并行,提高计算效率;5) 稳定token选择机制:减少token选择的波动,提高缓存命中率。整体流程为:LLM推理过程中,PNM加速器根据上下文信息选择合适的token页面,然后将这些页面传输到GPU进行计算。
关键创新:最重要的创新点在于将token选择计算卸载到PNM加速器上。与传统的完全依赖GPU进行KV缓存管理的方法相比,该方案显著减少了GPU和外部存储之间的数据传输量,从而提高了推理速度和能效。
关键设计:论文提出了两种主要的方案:PNM-KV(纯PNM卸载)和 PnG-KV(GPU-PNM混合)。PNM-KV将所有token选择计算都卸载到PNM上,而PnG-KV则将部分计算保留在GPU上,以实现更好的负载均衡。此外,论文还设计了一种稳定token选择机制,通过对token的重要性进行排序和筛选,减少了token选择的波动,提高了缓存命中率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PNM-KV和PnG-KV方案在具有高达405B参数和1M token上下文的LLM上,实现了显著的性能提升。与基线相比,吞吐量提升高达21.9倍,每token能耗降低高达60倍,总成本效率提高高达7.3倍。这些结果表明,基于CXL的多PNM架构可以作为未来长上下文LLM推理的可扩展骨干。
🎯 应用场景
该研究成果可应用于需要处理长上下文信息的各种LLM应用场景,例如长文档摘要、对话系统、代码生成等。通过降低推理成本和提高推理效率,可以促进LLM在更多领域的应用,并为未来的长上下文LLM推理提供可扩展的解决方案。
📄 摘要(原文)
The expansion of context windows in large language models (LLMs) to multi-million tokens introduces severe memory and compute bottlenecks, particularly in managing the growing Key-Value (KV) cache. While Compute Express Link (CXL) enables non-eviction frameworks that offload the full KV-cache to scalable external memory, these frameworks still suffer from costly data transfers when recalling non-resident KV tokens to limited GPU memory as context lengths increase. This work proposes scalable Processing-Near-Memory (PNM) for 1M-Token LLM Inference, a CXL-enabled KV-cache management system that coordinates memory and computation beyond GPU limits. Our design offloads token page selection to a PNM accelerator within CXL memory, eliminating costly recalls and enabling larger GPU batch sizes. We further introduce a hybrid parallelization strategy and a steady-token selection mechanism to enhance compute efficiency and scalability. Implemented atop a state-of-the-art CXL-PNM system, our solution delivers consistent performance gains for LLMs with up to 405B parameters and 1M-token contexts. Our PNM-only offloading scheme (PNM-KV) and GPU-PNM hybrid with steady-token execution (PnG-KV) achieve up to 21.9x throughput improvement, up to 60x lower energy per token, and up to 7.3x better total cost efficiency than the baseline, demonstrating that CXL-enabled multi-PNM architectures can serve as a scalable backbone for future long-context LLM inference.