LongCat-Flash-Omni Technical Report
作者: Meituan LongCat Team, Bairui Wang, Bayan, Bin Xiao, Bo Zhang, Bolin Rong, Borun Chen, Chang Wan, Chao Zhang, Chen Huang, Chen Chen, Chen Chen, Chengxu Yang, Chengzuo Yang, Cong Han, Dandan Peng, Delian Ruan, Detai Xin, Disong Wang, Dongchao Yang, Fanfan Liu, Fengjiao Chen, Fengyu Yang, Gan Dong, Gang Huang, Gang Xu, Guanglu Wan, Guoqiang Tan, Guoqiao Yu, Haibo Qiu, Hao Lu, Hongbo Liu, Hongyu Xiang, Jiaheng Wu, Jian Yang, Jiaxing Liu, Jing Huang, Jingang Wang, Jinrui Ding, Juchao Jiang, Jun Kuang, Jun Wang, Junhui Mei, Ke Ding, Kefeng Zhang, Lei Chen, Liang Shi, Limeng Qiao, Liming Zheng, Lin Ma, Liuyang Guo, Liya Ma, Luying Sun, Man Gao, Mengshen Zhu, Miao Cao, Minliang Lin, Nuo Xu, Peng Shi, Qi Zhang, Qian Fang, Qian Wang, Qian Yang, Quanxiu Wang, Rongxiang Weng, Rongxin Guo, Ruoxuan Liang, Senbin Yang, Shanbo Xu, Shanglin Lei, Shengze Ye, Shimin Chen, Shuaiqi Chen, Shujie Hu, Shuo Li, Siqi Yang, Siyu Xu, Siyu Ren, Song Li, Songxiang Liu, Tianhao Bai, Tianye Dai, Wei Hong, Wei Wang, Weixiao Zhao, Wengang Cao, Wenlong Zhu, Wenlong He, Xi Su, Xi Nan, Xiaohan Zhao, Xiaohao Wang, Xiaoyu Zhao, Xiaoyu Wang, Xiaoyu Li, Xin Pan, Xin Chen, Xiusong Sun, Xu Xiang, Xudong Xing, Xuezhi Cao, Xunliang Cai, Yang Yang, Yanli Tan, Yao Yao, Yerui Sun, Yi Chen, Yifan Lu, Yin Gong, Yining Zhang, Yitian Chen, Yiyang Gan, Yuchen Tang, Yuchen Xie, Yueqian Wang, Yuewen Zheng, Yufei Zhang, Yufeng Zhong, Yulei Qian, Yuqi Peng, Yuqian Li, Yuwei Jiang, Zeyang Hu, Zheng Zhang, Zhengkun Tian, Zhiqing Hong, Zhixiong Zeng, Zhuqi Mi, Ziran Li, Ziwen Wang, Ziyi Zhao, Ziyuan Zhuang, Zizhe Zhao
分类: cs.MM, cs.AI, cs.CL, cs.DC, cs.LG, cs.SD
发布日期: 2025-10-31 (更新: 2025-11-28)
💡 一句话要点
美团提出LongCat-Flash-Omni,一个5600亿参数的实时音视频交互全模态开源模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全模态模型 多模态学习 混合专家模型 实时交互 音视频处理 大规模模型训练 课程学习 模态解耦并行
📋 核心要点
- 现有全模态模型在处理大规模参数和实时交互方面存在挑战,难以兼顾性能和效率。
- LongCat-Flash-Omni采用渐进式训练策略和Shortcut连接的混合专家架构,提升多模态能力和实时性。
- 该模型在全模态基准测试中达到SOTA,并在文本、图像、视频和音频理解生成任务中表现出色。
📝 摘要(中文)
本文介绍了LongCat-Flash-Omni,一个先进的开源全模态模型,拥有5600亿参数,擅长实时音视频交互。通过采用受课程学习启发的渐进式训练策略,从简单到复杂的模态序列建模任务过渡,LongCat-Flash-Omni在保持强大单模态能力的同时,获得了全面的多模态能力。基于LongCat-Flash,它采用高性能的Shortcut连接的混合专家(MoE)架构,具有零计算专家,LongCat-Flash-Omni集成了高效的多模态感知和语音重建模块。尽管其规模庞大,拥有5600亿参数(其中270亿被激活),但LongCat-Flash-Omni实现了低延迟的实时音视频交互。在训练基础设施方面,我们开发了一种模态解耦并行方案,专门用于管理大规模多模态训练中固有的数据和模型异构性。这种创新方法通过维持超过90%的纯文本训练吞吐量,展示了卓越的效率。广泛的评估表明,LongCat-Flash-Omni在开源模型中,在全模态基准测试中实现了最先进的性能。此外,它在广泛的模态特定任务中提供了极具竞争力的结果,包括文本、图像和视频理解,以及音频理解和生成。我们提供了模型架构设计、训练程序和数据策略的全面概述,并开源该模型,以促进社区未来的研究和开发。
🔬 方法详解
问题定义:现有的大规模多模态模型通常面临两个主要挑战:一是模型参数量巨大,导致计算成本高昂,难以实现实时交互;二是多模态数据的异构性给模型训练带来困难,难以充分利用不同模态的信息。现有方法在效率和性能之间难以取得平衡,限制了其在实际应用中的潜力。
核心思路:LongCat-Flash-Omni的核心思路是采用一种渐进式的训练策略,从简单的单模态任务开始,逐步过渡到复杂的多模态任务,从而使模型能够更好地学习不同模态之间的关联。同时,利用Shortcut连接的混合专家(MoE)架构,在保证模型容量的同时,降低计算成本,实现高效的实时交互。
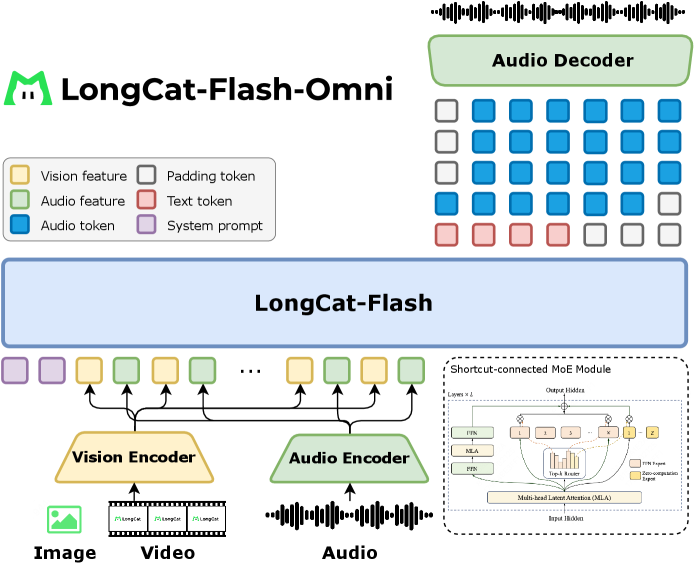
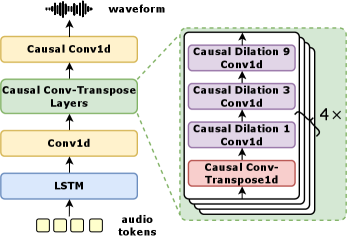
技术框架:LongCat-Flash-Omni的整体架构包括以下几个主要模块:1) 多模态感知模块,用于提取不同模态(文本、图像、视频、音频)的特征;2) 语音重建模块,用于生成音频;3) Shortcut连接的混合专家(MoE)模型,作为核心的序列建模模块;4) 模态解耦并行训练框架,用于高效地训练大规模多模态模型。训练流程采用课程学习的思想,逐步增加训练数据的复杂度和模态数量。
关键创新:LongCat-Flash-Omni的关键创新点在于以下几个方面:1) 渐进式训练策略,能够有效地提升多模态模型的学习效率和泛化能力;2) Shortcut连接的混合专家(MoE)架构,能够在保证模型容量的同时,降低计算成本;3) 模态解耦并行训练框架,能够高效地处理大规模多模态数据的训练。
关键设计:在模型设计方面,采用了Shortcut连接的MoE结构,并引入了零计算专家以进一步提升效率。在训练方面,采用了模态解耦的并行策略,并针对不同模态的数据特性进行了优化。损失函数的设计也考虑了多模态之间的关联性,例如,在语音重建任务中,使用了感知损失和对抗损失来提升生成音频的质量。
🖼️ 关键图片

📊 实验亮点
LongCat-Flash-Omni在全模态基准测试中取得了state-of-the-art的性能,超越了其他开源模型。此外,该模型在文本、图像、视频和音频理解生成等多个模态特定任务中也表现出极具竞争力的结果。值得一提的是,该模型在拥有5600亿参数的情况下,仍然能够实现低延迟的实时音视频交互,这充分体现了其高效的架构设计和训练策略。
🎯 应用场景
LongCat-Flash-Omni具有广泛的应用前景,例如智能助手、多模态对话系统、实时音视频会议、以及各种需要多模态信息融合的场景。该模型能够理解和生成多种模态的信息,实现更自然、更智能的人机交互,为用户提供更丰富的体验。未来,该模型有望在教育、娱乐、医疗等领域发挥重要作用。
📄 摘要(原文)
We introduce LongCat-Flash-Omni, a state-of-the-art open-source omni-modal model with 560 billion parameters, excelling at real-time audio-visual interaction. By adopting a curriculum-inspired progressive training strategy that transitions from simpler to increasingly complex modality sequence modeling tasks, LongCat-Flash-Omni attains comprehensive multimodal capabilities while maintaining strong unimodal capability. Building upon LongCat-Flash, which adopts a high-performance Shortcut-connected Mixture-of-Experts (MoE) architecture with zero-computation experts, LongCat-Flash-Omni integrates efficient multimodal perception and speech reconstruction modules. Despite its immense size of 560B parameters (with 27B activated), LongCat-Flash-Omni achieves low-latency real-time audio-visual interaction. For training infrastructure, we developed a modality-decoupled parallelism scheme specifically designed to manage the data and model heterogeneity inherent in large-scale multimodal training. This innovative approach demonstrates exceptional efficiency by sustaining over 90% of the throughput achieved by text-only training. Extensive evaluations show that LongCat-Flash-Omni achieves state-of-the-art performance on omni-modal benchmarks among open-source models. Furthermore, it delivers highly competitive results across a wide range of modality-specific tasks, including text, image, and video understanding, as well as audio understanding and generation. We provide a comprehensive overview of the model architecture design, training procedures, and data strategies, and open-source the model to foster future research and development in the community.