Understanding Code Agent Behaviour: An Empirical Study of Success and Failure Trajectories
作者: Oorja Majgaonkar, Zhiwei Fei, Xiang Li, Federica Sarro, He Ye
分类: cs.SE, cs.AI
发布日期: 2025-10-31
💡 一句话要点
通过分析代码Agent轨迹理解其行为,揭示成功与失败模式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码Agent 行为分析 轨迹分析 软件工程 大型语言模型
📋 核心要点
- 现有代码Agent决策过程不透明,难以理解其问题解决行为,阻碍了更鲁棒系统的开发。
- 通过分析代码Agent在解决软件问题时的执行轨迹,揭示其成功和失败的模式与策略。
- 实验表明,不同Agent的失败模式差异显著,成功更多依赖于近似而非精确的代码修改。
📝 摘要(中文)
大型语言模型(LLM)Agent在复杂软件工程任务中的日益普及,促使人们需要超越简单的成功指标来理解其问题解决行为。尽管这些Agent在自动问题解决方面表现出令人印象深刻的能力,但其决策过程在很大程度上仍然不透明。本文对Agent轨迹进行了实证研究,即捕获Agent尝试解决软件问题时所采取步骤的执行跟踪。我们分析了SWE-Bench基准测试中三个最先进的代码Agent(OpenHands、SWE-agent和Prometheus)的轨迹,检查了成功和失败的尝试。我们的研究揭示了Agent行为的几个关键见解。首先,我们确定了不同的问题解决策略,如防御性编程和上下文收集,如何在不同的场景中实现成功。其次,我们发现失败的轨迹始终比成功的轨迹更长,并且表现出更高的方差,不同Agent之间的失败模式差异显著。第三,我们的故障定位分析表明,虽然大多数轨迹正确识别了有问题的文件(即使在失败中也达到72-81%),但成功更多地取决于实现近似而非精确的代码修改。这些以及我们研究揭示的其他发现,为通过轨迹分析理解Agent行为奠定了基础,有助于开发更强大和可解释的自主软件工程系统。
🔬 方法详解
问题定义:现有的大型语言模型代码Agent在软件工程任务中展现出强大的能力,但其内部决策过程如同黑盒,难以理解。这使得我们难以诊断Agent的失败原因,也无法针对性地改进Agent的性能。现有方法缺乏对Agent行为轨迹的深入分析,无法有效揭示Agent的成功和失败模式。
核心思路:本文的核心思路是通过分析代码Agent在解决软件问题时的执行轨迹(trajectory),来理解其行为模式。轨迹包含了Agent在解决问题过程中采取的每一步操作,例如读取文件、修改代码、运行测试等。通过对轨迹的分析,可以了解Agent的决策过程、问题解决策略以及失败的原因。这种方法类似于对人类专家进行“事后分析”,从而学习其经验和教训。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择合适的代码Agent和软件问题基准测试集(SWE-Bench)。2) 运行Agent解决问题,并记录其执行轨迹。3) 对轨迹进行清洗和预处理,例如去除无关信息、对操作进行分类等。4) 对轨迹进行统计分析,例如计算轨迹长度、操作类型频率、失败率等。5) 对成功和失败的轨迹进行对比分析,找出差异和共性。6) 进行故障定位分析,确定Agent在哪些步骤或文件中出现错误。
关键创新:该研究的关键创新在于将轨迹分析方法应用于代码Agent的行为理解。与传统的只关注Agent的最终结果(成功或失败)的方法不同,本文深入分析了Agent的整个问题解决过程,从而揭示了Agent的内部决策机制。此外,本文还提出了针对代码Agent的故障定位分析方法,可以帮助开发者快速找到Agent出错的位置。
关键设计:在轨迹分析方面,研究者设计了多种统计指标来描述轨迹的特征,例如轨迹长度、操作类型频率、代码修改的精确度等。在故障定位分析方面,研究者采用了基于文件和代码行的定位方法,可以精确地找到Agent出错的位置。此外,研究者还对不同Agent的轨迹进行了对比分析,从而揭示了不同Agent之间的行为差异。
🖼️ 关键图片
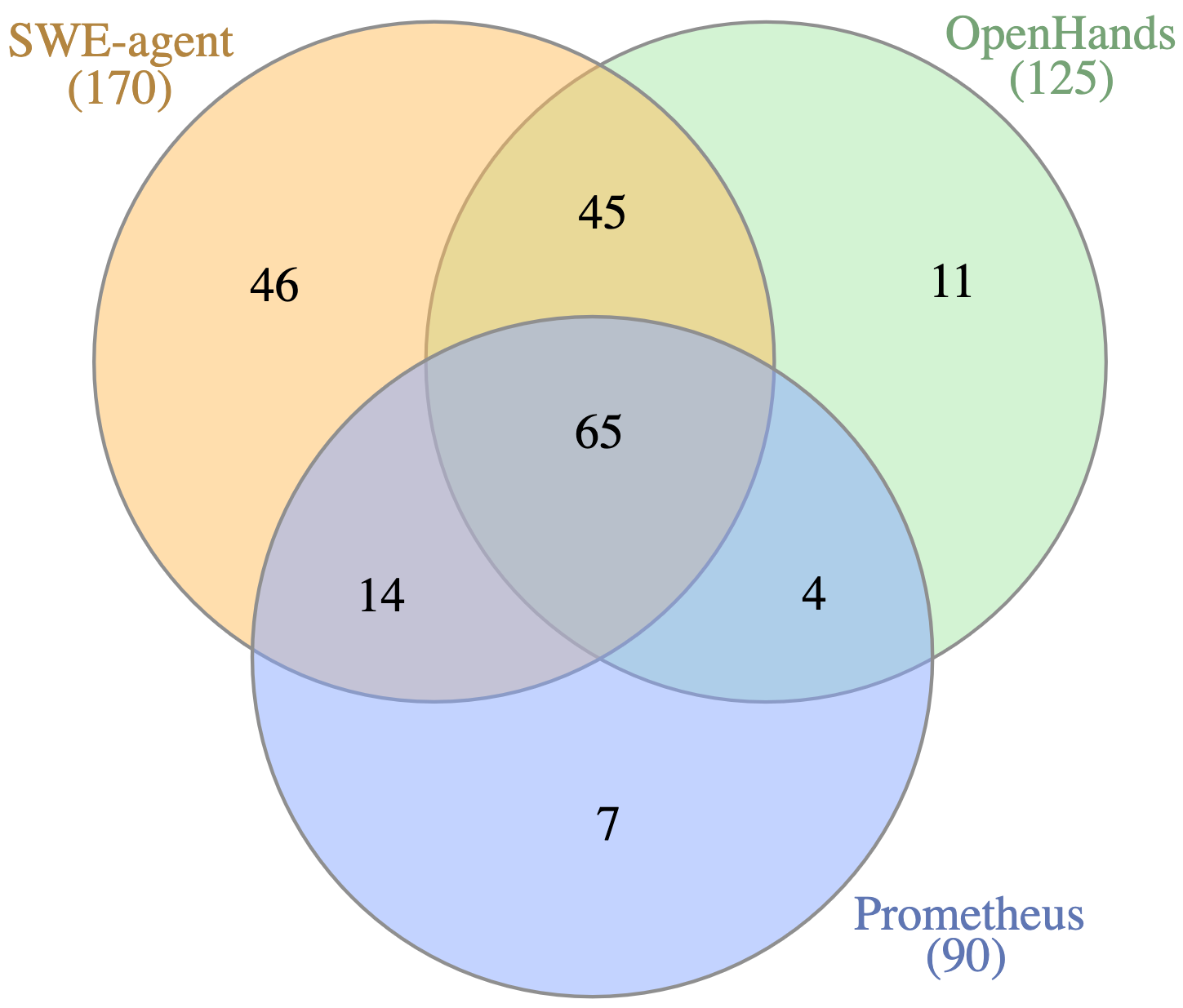
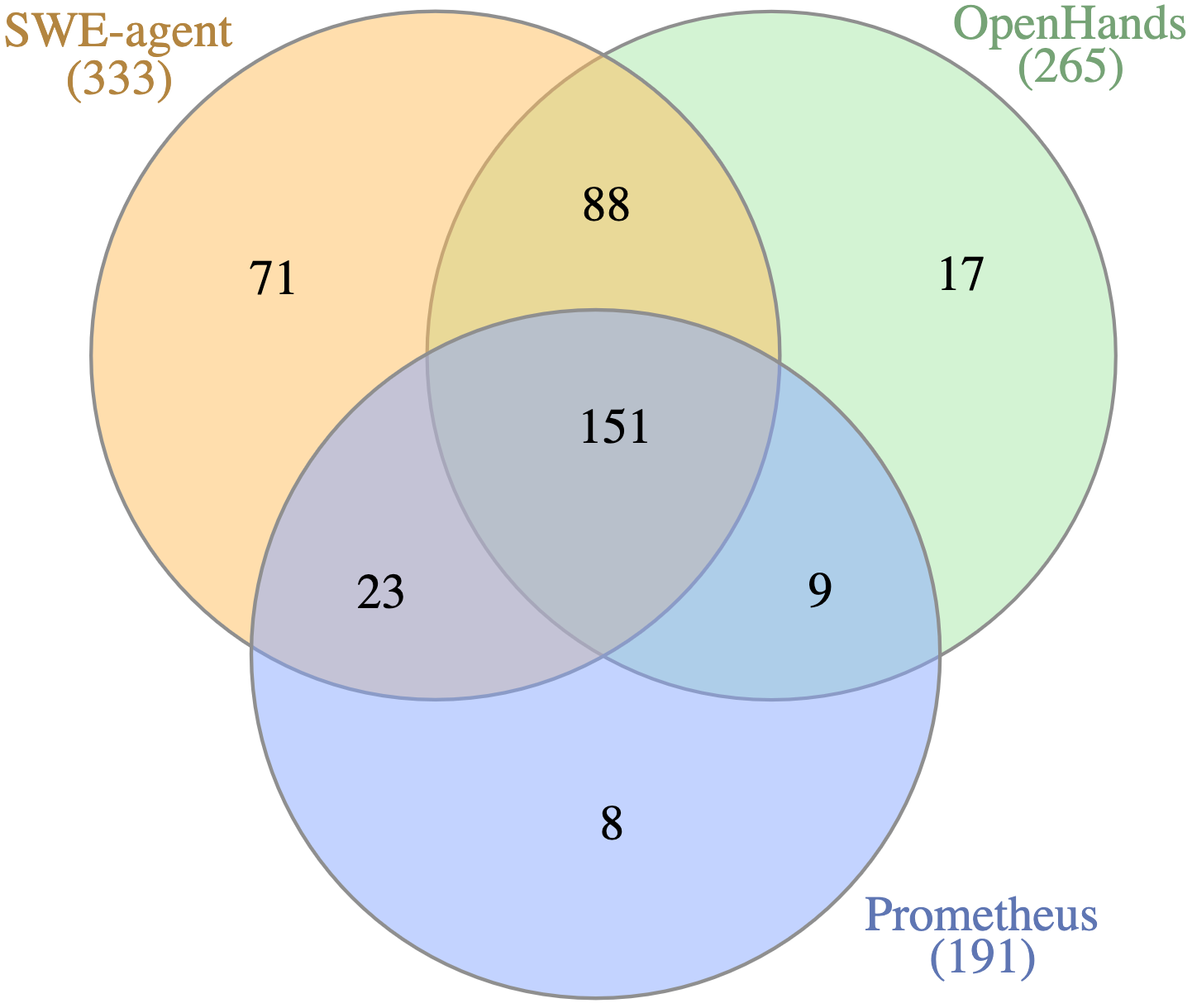

📊 实验亮点
实验结果表明,失败的轨迹通常比成功的轨迹更长且方差更大,表明失败的尝试涉及更多的探索和尝试。故障定位分析显示,即使在失败的轨迹中,Agent也能正确识别问题文件(72-81%),但成功与否更多取决于代码修改的近似程度而非完全正确。不同Agent的失败模式存在显著差异,表明它们采用了不同的问题解决策略。
🎯 应用场景
该研究成果可应用于提升代码Agent的可靠性和可解释性。通过理解Agent的行为模式,开发者可以针对性地改进Agent的算法和训练数据,提高其解决问题的能力。此外,该研究还可以用于开发智能调试工具,帮助开发者快速定位Agent出错的位置,提高软件开发的效率。未来,该研究有望推动自主软件工程系统的发展。
📄 摘要(原文)
The increasing deployment of Large Language Model (LLM) agents for complex software engineering tasks has created a need to understand their problem-solving behaviours beyond simple success metrics. While these agents demonstrate impressive capabilities in automated issue resolution, their decision-making processes remain largely opaque. This paper presents an empirical study of agent trajectories, namely the execution traces capturing the steps agents take when attempting to resolve software issues. We analyse trajectories from three state-of-the-art code agents (OpenHands, SWE-agent, and Prometheus) on the SWE-Bench benchmark, examining both successful and failed attempts. Our investigation reveals several key insights into agent behaviour. First, we identify how distinct problem-solving strategies, such as defensive programming and context gathering, enable success in different scenarios. Second, we find that failed trajectories are consistently longer and exhibit higher variance than successful ones, with failure patterns differing significantly between agents. Third, our fault localisation analysis shows that while most trajectories correctly identify problematic files (72-81\% even in failures), success depends more on achieving approximate rather than exact code modifications. These and other findings unveiled by our study, provide a foundation for understanding agent behaviour through trajectory analysis, contributing to the development of more robust and interpretable autonomous software engineering systems.