Best Practices for Biorisk Evaluations on Open-Weight Bio-Foundation Models
作者: Boyi Wei, Zora Che, Nathaniel Li, Udari Madhushani Sehwag, Jasper Götting, Samira Nedungadi, Julian Michael, Summer Yue, Dan Hendrycks, Peter Henderson, Zifan Wang, Seth Donoughe, Mantas Mazeika
分类: cs.CR, cs.AI
发布日期: 2025-10-31 (更新: 2025-11-20)
备注: 17 Pages, 5 figures
💡 一句话要点
提出BioRiskEval框架,评估开放生物大模型潜在的生物风险与数据过滤有效性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生物基础模型 生物风险评估 双重用途 数据过滤 恶意微调 病毒理解 序列建模
📋 核心要点
- 现有生物大模型的数据过滤方法在应对恶意微调攻击时效果不佳,无法有效降低潜在的生物风险。
- BioRiskEval框架通过序列建模、突变效应预测和毒力预测三个维度,全面评估生物大模型的病毒理解能力。
- 实验表明,数据过滤的有效性有限,恶意知识可以通过微调快速恢复,且双重用途信号可能已存在于预训练模型中。
📝 摘要(中文)
开放权重生物基础模型面临双重用途困境。虽然它们在加速科学研究和药物开发方面具有巨大潜力,但也可能被恶意行为者利用来开发更致命的生物武器。为了降低这些模型带来的风险,目前的方法主要集中在预训练期间过滤生物危害数据。然而,这种方法的有效性仍不清楚,特别是对于那些可能对这些模型进行恶意微调的恶意行为者。为了解决这个问题,我们提出了BioRiskEval,一个评估旨在降低生物基础模型双重用途能力的程序的鲁棒性的框架。BioRiskEval通过三个角度评估模型对病毒的理解,包括序列建模、突变效应预测和毒力预测。我们的结果表明,当前的数据过滤实践可能不是特别有效:排除的知识可以在某些情况下通过微调快速恢复,并在序列建模中表现出更广泛的泛化能力。此外,双重用途信号可能已经存在于预训练的表示中,并且可以通过简单的线性探测来引出。这些发现突出了数据过滤作为独立程序所面临的挑战,强调需要进一步研究开放权重生物基础模型的稳健安全策略。
🔬 方法详解
问题定义:论文旨在评估开放权重生物基础模型在生物安全方面的风险,特别是现有数据过滤方法在防止模型被恶意利用方面的有效性。现有方法的痛点在于,它们可能无法充分消除模型中存在的双重用途知识,并且容易受到恶意微调的攻击。
核心思路:论文的核心思路是构建一个综合性的评估框架BioRiskEval,通过模拟恶意利用场景,系统性地测试模型在病毒理解方面的能力,从而揭示数据过滤策略的局限性。这种评估方法能够更全面地了解模型潜在的生物风险,并为改进安全策略提供依据。
技术框架:BioRiskEval框架包含三个主要模块:1) 序列建模,评估模型对病毒序列的理解和生成能力;2) 突变效应预测,评估模型预测病毒突变对其毒力影响的能力;3) 毒力预测,评估模型直接预测病毒毒性的能力。这三个模块分别从不同角度考察模型对病毒的理解,形成一个多维度的评估体系。
关键创新:该论文的关键创新在于提出了一个专门针对生物基础模型的生物风险评估框架。与以往侧重于数据过滤的方法不同,BioRiskEval侧重于评估模型在完成特定任务时的风险,从而更直接地反映了模型的潜在危害。此外,该框架还考虑了恶意微调的影响,更贴近实际应用场景。
关键设计:在序列建模模块,使用了基于Transformer的模型结构,并采用了标准的序列建模损失函数。在突变效应预测模块,使用了回归模型来预测突变对毒力的影响,损失函数为均方误差。在毒力预测模块,使用了分类模型来预测病毒的毒性等级,损失函数为交叉熵损失。此外,论文还设计了针对恶意微调的评估方案,通过在少量恶意数据上微调模型,然后评估其在BioRiskEval上的表现。
🖼️ 关键图片

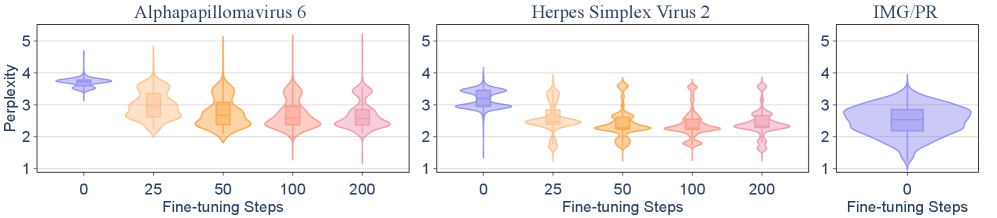

📊 实验亮点
实验结果表明,当前的数据过滤方法在降低生物风险方面的效果有限。通过微调,模型可以快速恢复被过滤掉的知识,并且这些知识可以泛化到其他任务中。此外,研究还发现,即使没有经过微调,预训练模型中也可能存在双重用途信号,可以通过简单的线性探测来提取。这些发现表明,数据过滤作为一种独立的策略是不够的,需要结合其他安全措施。
🎯 应用场景
该研究成果可应用于生物安全领域,帮助研究人员和政策制定者评估和降低开放生物大模型的潜在风险。通过BioRiskEval框架,可以更有效地识别和防范恶意利用,促进生物技术的安全发展,并为制定更完善的安全策略提供依据。此外,该研究也为其他领域的AI安全评估提供了借鉴。
📄 摘要(原文)
Open-weight bio-foundation models present a dual-use dilemma. While holding great promise for accelerating scientific research and drug development, they could also enable bad actors to develop more deadly bioweapons. To mitigate the risk posed by these models, current approaches focus on filtering biohazardous data during pre-training. However, the effectiveness of such an approach remains unclear, particularly against determined actors who might fine-tune these models for malicious use. To address this gap, we propose BioRiskEval, a framework to evaluate the robustness of procedures that are intended to reduce the dual-use capabilities of bio-foundation models. BioRiskEval assesses models' virus understanding through three lenses, including sequence modeling, mutational effects prediction, and virulence prediction. Our results show that current filtering practices may not be particularly effective: Excluded knowledge can be rapidly recovered in some cases via fine-tuning, and exhibits broader generalizability in sequence modeling. Furthermore, dual-use signals may already reside in the pretrained representations, and can be elicited via simple linear probing. These findings highlight the challenges of data filtering as a standalone procedure, underscoring the need for further research into robust safety and security strategies for open-weight bio-foundation models.