CodeAlignBench: Assessing Code Generation Models on Developer-Preferred Code Adjustments
作者: Forough Mehralian, Ryan Shar, James R. Rae, Alireza Hashemi
分类: cs.SE, cs.AI, cs.HC
发布日期: 2025-10-31
💡 一句话要点
CodeAlignBench:评估代码生成模型在开发者偏好代码调整上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 语言模型 基准测试 指令遵循 代码调整 多语言 开发者偏好
📋 核心要点
- 现有代码生成模型评估主要关注功能正确性,忽略了开发者在实际编码中对代码风格和可维护性的偏好。
- CodeAlignBench旨在评估LLM在遵循初始约束和后续指令进行代码改进方面的能力,更贴近实际开发场景。
- 该基准测试支持多语言(Python, Java, JavaScript),并揭示了模型在不同语言和指令遵循维度上的性能差异。
📝 摘要(中文)
随着大型语言模型在代码生成方面能力日益增强,评估其性能仍然是一个复杂且不断演变的挑战。现有的基准测试主要关注功能正确性,忽略了真实世界编码任务的多样性和开发者的期望。为此,我们引入了一个多语言基准测试,用于评估LLM的指令遵循能力,并且可以扩展到任何独立编码问题集上。我们的基准测试在两个关键设置中评估指令遵循:遵守初始问题中指定的预定义约束,以及执行基于后续指令的改进的能力。在本文的分析中,我们使用来自LiveBench的编程任务对我们的基准测试流程进行了实证评估,这些任务也自动从Python翻译成Java和JavaScript。我们的自动化基准测试表明,模型在指令遵循的多个维度上表现出不同的性能水平。我们的基准测试流程提供了对代码生成模型更全面的评估,突出了它们在不同语言和生成目标方面的优势和局限性。
🔬 方法详解
问题定义:现有代码生成模型的评估方法主要集中在功能正确性上,缺乏对开发者在实际开发中对代码风格、可读性和可维护性等偏好的考虑。此外,现有方法难以评估模型根据后续指令进行代码调整和改进的能力,这与实际开发流程存在差距。
核心思路:CodeAlignBench的核心思路是构建一个更贴近实际开发场景的基准测试,通过评估模型在遵循初始约束和后续指令进行代码改进方面的能力,来更全面地衡量代码生成模型的性能。该基准测试关注模型对开发者意图的理解和执行能力,以及在不同编程语言环境下的适应性。
技术框架:CodeAlignBench的整体框架包含以下几个主要模块:1) 问题收集模块:从LiveBench等现有数据集收集编程任务,并将其翻译成多种编程语言(Python, Java, JavaScript)。2) 指令生成模块:为每个编程任务生成初始约束和后续改进指令,模拟实际开发中的需求变更。3) 代码生成模块:使用待评估的LLM生成代码。4) 评估模块:自动评估生成的代码在功能正确性、代码风格、可读性等方面的表现,并与开发者提供的参考代码进行比较。
关键创新:CodeAlignBench的关键创新在于其评估指标的设计,不仅关注代码的功能正确性,还关注代码是否符合开发者预期的风格和可维护性。此外,该基准测试引入了后续指令的概念,可以评估模型根据需求变更进行代码调整的能力,更贴近实际开发流程。
关键设计:CodeAlignBench的关键设计包括:1) 多语言支持:支持Python, Java, JavaScript等多种编程语言,可以评估模型在不同语言环境下的适应性。2) 自动翻译:使用自动翻译工具将编程任务从Python翻译成其他语言,降低了构建基准测试的成本。3) 多维度评估:从功能正确性、代码风格、可读性等多个维度评估生成的代码,提供更全面的性能评估。
🖼️ 关键图片

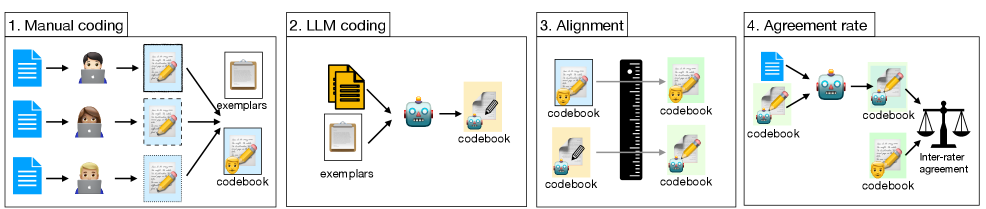
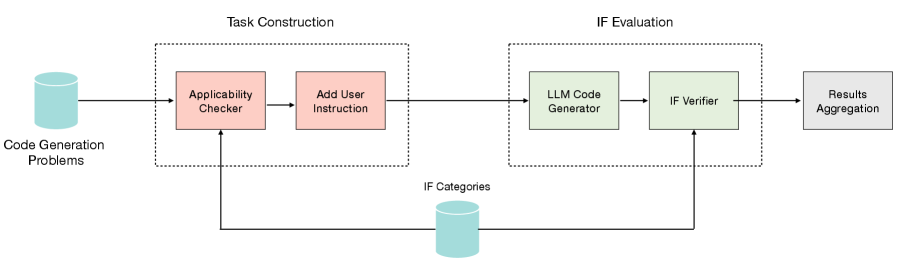
📊 实验亮点
实验结果表明,不同的代码生成模型在CodeAlignBench上表现出显著的性能差异,尤其是在指令遵循和代码改进方面。该基准测试揭示了现有模型在代码风格和可维护性方面的不足,并为未来的研究提供了方向。例如,某些模型在Python上的表现优于Java,表明模型对不同语言的理解程度存在差异。
🎯 应用场景
CodeAlignBench可用于评估和比较不同代码生成模型的性能,帮助开发者选择更适合其需求的模型。此外,该基准测试可以促进代码生成模型的研究,推动模型在代码风格、可读性和可维护性等方面的改进。未来,该基准测试可以扩展到更多编程语言和更复杂的编程任务,以更好地模拟实际开发场景。
📄 摘要(原文)
As large language models become increasingly capable of generating code, evaluating their performance remains a complex and evolving challenge. Existing benchmarks primarily focus on functional correctness, overlooking the diversity of real-world coding tasks and developer expectations. To this end, we introduce a multi-language benchmark that evaluates LLM instruction-following capabilities and is extensible to operate on any set of standalone coding problems. Our benchmark evaluates instruction following in two key settings: adherence to pre-defined constraints specified with the initial problem, and the ability to perform refinements based on follow-up instructions. For this paper's analysis, we empirically evaluated our benchmarking pipeline with programming tasks from LiveBench, that are also automatically translated from Python into Java and JavaScript. Our automated benchmark reveals that models exhibit differing levels of performance across multiple dimensions of instruction-following. Our benchmarking pipeline provides a more comprehensive evaluation of code generation models, highlighting their strengths and limitations across languages and generation goals.