Mechanics of Learned Reasoning 1: TempoBench, A Benchmark for Interpretable Deconstruction of Reasoning System Performance
作者: Nikolaus Holzer, William Fishell, Baishakhi Ray, Mark Santolucito
分类: cs.AI, cs.FL
发布日期: 2025-10-31
🔗 代码/项目: GITHUB
💡 一句话要点
TempoBench:用于可解释地解构推理系统性能的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 基准测试 形式验证 因果推理
📋 核心要点
- 现有LLM推理benchmark缺乏真实世界对齐,且难以形式验证,限制了其在复杂决策任务中的应用。
- TempoBench通过形式化和可验证的基准,参数化推理难度,系统性地分析LLM的推理能力。
- 实验结果表明,LLM在理解因果推理任务方面表现良好,但随着系统复杂性增加,性能显著下降。
📝 摘要(中文)
大型语言模型(LLMs)在许多任务上的表现日益出色,甚至超越了人类。然而,为了改进LLM的推理能力,研究人员要么依赖于临时生成的数据集,要么依赖于形式化的数学证明系统,如Lean证明助手。虽然临时生成的方法可以捕捉现实世界推理过程的决策链,但它们可能在推理空间中编码一些无意的偏差,并且无法进行形式验证。另一方面,像Lean这样的系统可以保证可验证性,但不太适合捕捉基于agent决策链的任务的本质。这在商业代理或代码助手等功能的性能以及LLM推理基准的效用方面造成了差距,因为这些基准在推理结构或与现实世界的对齐方面存在不足。我们引入了TempoBench,这是第一个形式化且可验证的诊断基准,它参数化了难度,以系统地分析LLM如何执行推理。TempoBench使用两个评估基准来分解推理能力。首先,时间轨迹评估(TTE)测试LLM理解和模拟给定多步推理系统执行的能力。随后,时间因果评估(TCE)测试LLM执行多步因果推理并从复杂系统中提取因果关系的能力。我们发现模型在TCE-normal上的得分为65.6%,在TCE-hard上的得分为7.5%。这表明最先进的LLM清楚地理解TCE任务,但随着系统复杂性的增加,性能会变差。我们的代码可在我们的GitHub存储库中找到。
🔬 方法详解
问题定义:现有的大型语言模型推理能力评估方法存在局限性。一方面,Ad-hoc生成的数据集可能包含无意的偏差,并且缺乏形式验证。另一方面,形式化的数学证明系统(如Lean)虽然可以保证可验证性,但难以捕捉现实世界中基于agent的决策链任务的本质。因此,需要一种既能模拟真实世界推理过程,又能进行形式验证的基准测试方法。
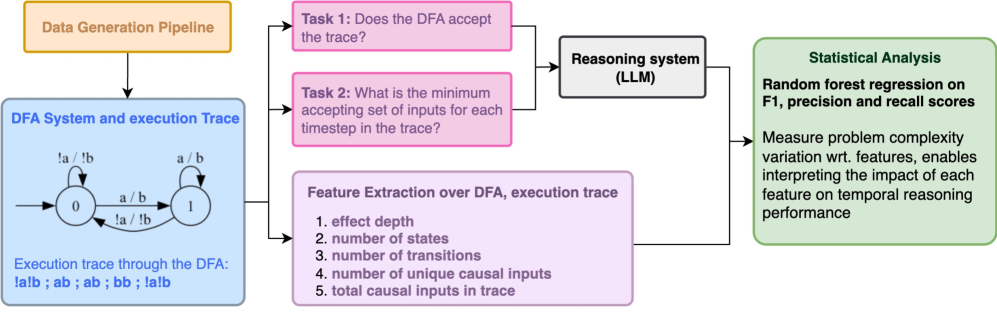
核心思路:TempoBench的核心思路是通过构建一个形式化、可验证且参数化的基准测试,来系统地分析LLM的推理能力。该基准测试通过分解推理过程,评估LLM在理解和模拟多步推理系统执行以及执行多步因果推理方面的能力。通过参数化难度,可以更精细地评估LLM在不同复杂程度下的推理表现。
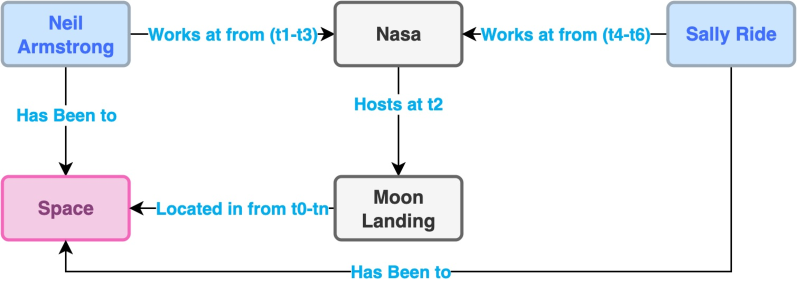
技术框架:TempoBench包含两个主要的评估基准:时间轨迹评估(TTE)和时间因果评估(TCE)。TTE测试LLM理解和模拟给定多步推理系统执行的能力。TCE测试LLM执行多步因果推理并从复杂系统中提取因果关系的能力。这两个基准测试共同构成了一个完整的推理能力评估框架。
关键创新:TempoBench的关键创新在于其形式化和可验证性。与传统的Ad-hoc生成的数据集不同,TempoBench的测试用例是基于形式化的规则生成的,因此可以进行形式验证,从而保证了评估结果的可靠性。此外,TempoBench通过参数化难度,可以更系统地分析LLM在不同复杂程度下的推理表现。
关键设计:TempoBench的具体实现细节未知,但可以推测其关键设计包括:定义形式化的推理规则,生成具有不同复杂程度的测试用例,设计评估指标来衡量LLM在TTE和TCE任务上的表现,以及提供一个易于使用的评估平台。
🖼️ 关键图片

📊 实验亮点
实验结果表明,最先进的LLM在TCE-normal上的得分为65.6%,但在TCE-hard上的得分仅为7.5%。这表明LLM能够理解因果推理任务,但随着系统复杂性的增加,性能显著下降。这一结果突显了现有LLM在处理复杂推理任务方面的局限性,并强调了TempoBench的价值。
🎯 应用场景
TempoBench可用于评估和改进LLM在商业代理、代码助手等领域的推理能力。通过系统地分析LLM的推理弱点,可以指导模型训练和架构设计,从而提高LLM在复杂决策任务中的性能。该基准测试还有助于推动可解释AI的发展,使人们能够更好地理解LLM的推理过程。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly excelling and outpacing human performance on many tasks. However, to improve LLM reasoning, researchers either rely on ad-hoc generated datasets or formal mathematical proof systems such as the Lean proof assistant. Whilst ad-hoc generated methods can capture the decision chains of real-world reasoning processes, they may encode some inadvertent bias in the space of reasoning they cover; they also cannot be formally verified. On the other hand, systems like Lean can guarantee verifiability, but are not well-suited to capture the nature of agentic decision chain-based tasks. This creates a gap both in performance for functions such as business agents or code assistants, and in the usefulness of LLM reasoning benchmarks, whereby these fall short in reasoning structure or real-world alignment. We introduce TempoBench, the first formally grounded and verifiable diagnostic benchmark that parametrizes difficulty to systematically analyze how LLMs perform reasoning. TempoBench uses two evaluation benchmarks to break down reasoning ability. First, temporal trace evaluation (TTE) tests the ability of an LLM to understand and simulate the execution of a given multi-step reasoning system. Subsequently, temporal causal evaluation (TCE) tests an LLM's ability to perform multi-step causal reasoning and to distill cause-and-effect relations from complex systems. We find that models score 65.6% on TCE-normal, and 7.5% on TCE-hard. This shows that state-of-the-art LLMs clearly understand the TCE task but perform poorly as system complexity increases. Our code is available at our \href{https://github.com/nik-hz/tempobench}{GitHub repository}.