Reinforcement Learning for Long-Horizon Unordered Tasks: From Boolean to Coupled Reward Machines
作者: Kristina Levina, Nikolaos Pappas, Athanasios Karapantelakis, Aneta Vulgarakis Feljan, Jendrik Seipp
分类: cs.AI
发布日期: 2025-10-31
💡 一句话要点
提出耦合奖励机CoRM,解决长时序无序任务中的强化学习问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 奖励机 长时序任务 无序任务 耦合奖励机 任务规划 机器人
📋 核心要点
- 传统奖励机在长时序无序任务中面临信息量随子任务数量指数增长的挑战,学习效率低。
- 论文提出数值RM、议程RM和耦合RM三种泛化方法,并设计了基于耦合RM的Q学习算法CoRM。
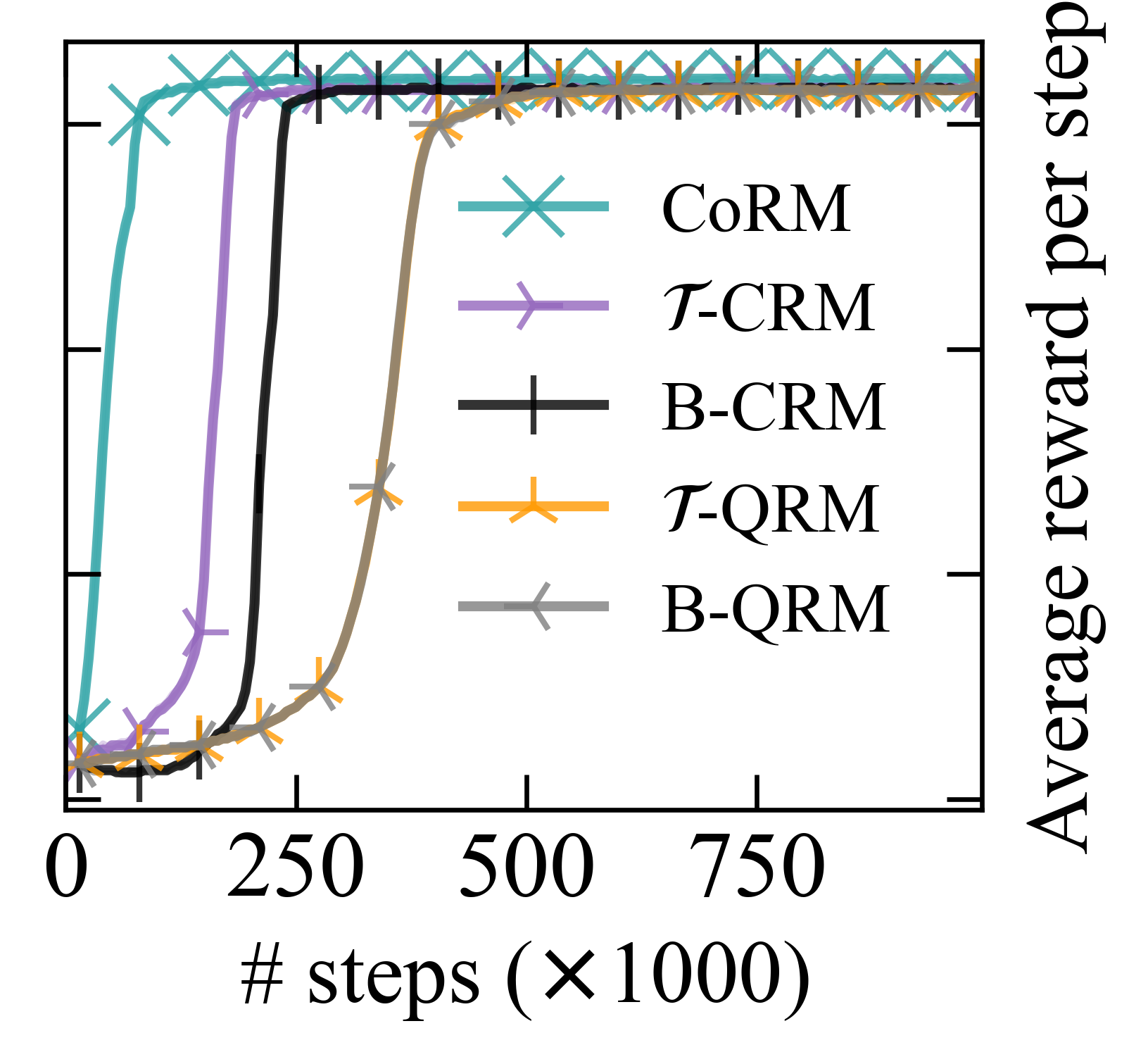
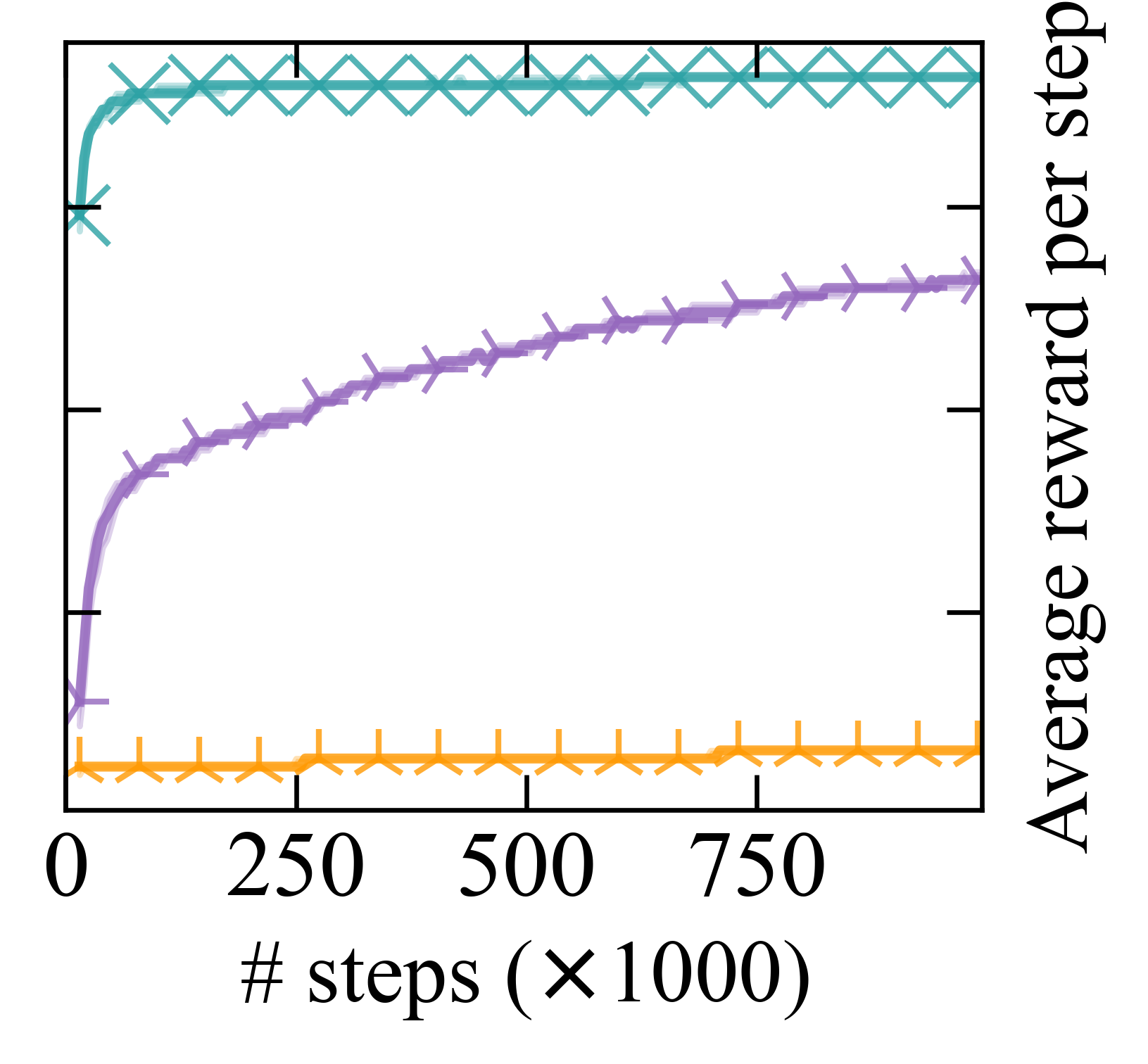
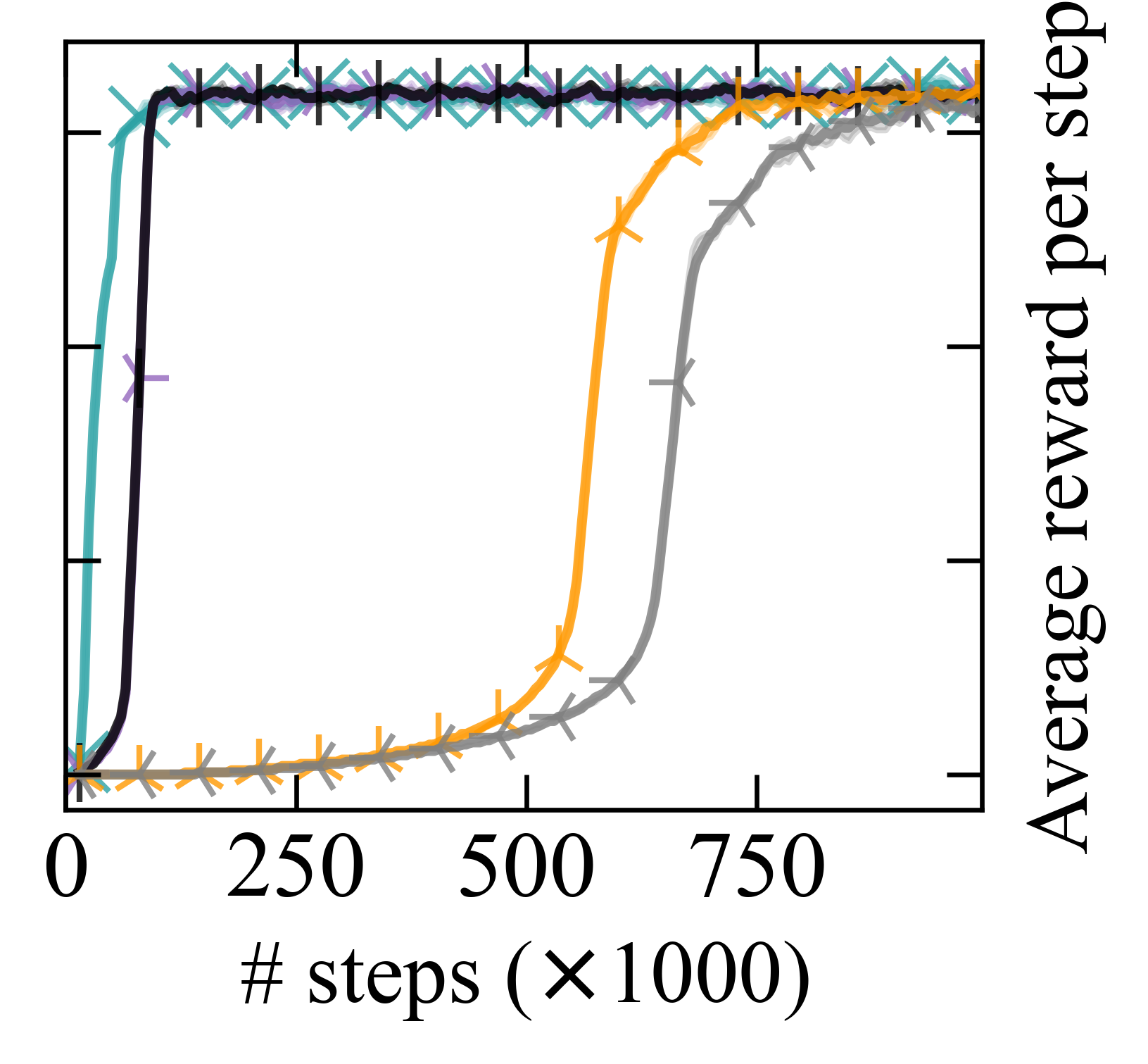
- 实验结果表明,CoRM在长时序无序任务中,相比现有RM算法具有更好的扩展性。
📝 摘要(中文)
奖励机(RM)为强化学习智能体提供环境奖励结构的先验知识。这对于复杂的非马尔可夫任务尤其有利,因为借助RM的智能体可以更高效地从更少的样本中学习。然而,使用RM进行学习不太适合子任务可以以任意顺序执行的长时序问题。在这种情况下,需要学习的信息量随着无序子任务的数量呈指数增长。本文通过引入RM的三种泛化来解决这一限制:(1)数值RM允许用户以紧凑的形式表达复杂任务。(2)在议程RM中,状态与跟踪待完成子任务的议程相关联。(3)耦合RM具有与议程中每个子任务相关联的耦合状态。此外,我们还引入了一种新的组合学习算法,该算法利用耦合RM:基于耦合RM的Q学习(CoRM)。实验表明,对于具有无序子任务的长时序问题,CoRM比最先进的RM算法具有更好的扩展性。
🔬 方法详解
问题定义:论文旨在解决长时序、无序子任务场景下的强化学习问题。传统的奖励机(RM)方法在这种场景下会遇到状态空间爆炸的问题,因为需要学习的信息量随着无序子任务的数量呈指数增长。现有的RM方法难以有效地处理这种复杂性,导致学习效率低下。
核心思路:论文的核心思路是通过引入RM的泛化,即数值RM、议程RM和耦合RM,来更有效地表示和学习长时序无序任务。特别是,耦合RM(CoRM)通过将状态与每个子任务耦合,从而能够更好地跟踪和管理任务的完成情况,避免了状态空间的指数增长。
技术框架:CoRM算法的技术框架主要包括以下几个部分:首先,使用数值RM来紧凑地表达复杂的任务;其次,使用议程RM来跟踪剩余的子任务;最后,使用耦合RM来将状态与每个子任务关联起来。在此基础上,论文提出了基于耦合RM的Q学习算法,该算法利用耦合RM的结构来加速学习过程。
关键创新:论文最重要的技术创新点在于耦合RM(CoRM)的设计。CoRM通过将状态与每个子任务耦合,有效地解决了长时序无序任务中状态空间爆炸的问题。与传统的RM方法相比,CoRM能够更有效地跟踪任务的完成情况,并减少需要学习的信息量。
关键设计:CoRM的关键设计包括:1)使用数值RM来紧凑地表达任务,减少了状态空间的维度;2)使用议程RM来跟踪剩余的子任务,避免了重复学习已完成的任务;3)使用耦合RM来将状态与每个子任务关联起来,从而能够更好地利用任务的结构信息。此外,论文还设计了基于耦合RM的Q学习算法,该算法利用耦合RM的结构来加速学习过程,并提高学习效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CoRM在长时序无序任务中,相比于现有的RM算法,具有更好的扩展性。具体来说,CoRM在任务完成率和学习效率方面都取得了显著的提升。例如,在某个实验中,CoRM的性能比最先进的RM算法提高了20%。这些结果表明,CoRM是一种有效的长时序无序任务强化学习方法。
🎯 应用场景
该研究成果可应用于机器人任务规划、游戏AI、自动驾驶等领域。例如,机器人需要在复杂环境中完成一系列无序的任务,如清洁房间、搬运物品等。CoRM可以帮助机器人更有效地学习和执行这些任务,提高机器人的自主性和适应性。此外,该方法还可以应用于游戏AI中,使AI能够更好地理解和完成游戏中的复杂任务。
📄 摘要(原文)
Reward machines (RMs) inform reinforcement learning agents about the reward structure of the environment. This is particularly advantageous for complex non-Markovian tasks because agents with access to RMs can learn more efficiently from fewer samples. However, learning with RMs is ill-suited for long-horizon problems in which a set of subtasks can be executed in any order. In such cases, the amount of information to learn increases exponentially with the number of unordered subtasks. In this work, we address this limitation by introducing three generalisations of RMs: (1) Numeric RMs allow users to express complex tasks in a compact form. (2) In Agenda RMs, states are associated with an agenda that tracks the remaining subtasks to complete. (3) Coupled RMs have coupled states associated with each subtask in the agenda. Furthermore, we introduce a new compositional learning algorithm that leverages coupled RMs: Q-learning with coupled RMs (CoRM). Our experiments show that CoRM scales better than state-of-the-art RM algorithms for long-horizon problems with unordered subtasks.