GUI-Rise: Structured Reasoning and History Summarization for GUI Navigation
作者: Tao Liu, Chongyu Wang, Rongjie Li, Yingchen Yu, Xuming He, Bai Song
分类: cs.AI, cs.CV
发布日期: 2025-10-31
备注: Published in NeurIPS 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
GUI-Rise:提出一种融合结构化推理和历史总结的GUI导航框架,提升跨领域泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI导航 多模态大语言模型 结构化推理 历史总结 强化学习 Chain-of-Thought 跨领域泛化
📋 核心要点
- 现有GUI导航代理在跨领域泛化能力和历史信息有效利用方面存在不足,限制了其应用范围。
- GUI-Rise框架通过结构化推理生成Chain-of-Thought分析,指导动作预测和历史总结,提升决策质量。
- 实验表明,GUI-Rise在标准基准上取得了最先进的结果,尤其在领域外场景中表现出强大的泛化能力。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在GUI导航代理方面取得了进展,但现有方法在跨领域泛化和有效利用历史信息方面存在局限性。本文提出了一种推理增强框架,系统地整合了结构化推理、动作预测和历史总结。结构化推理组件生成连贯的Chain-of-Thought分析,结合了进度估计和决策推理,为即时动作预测和未来步骤的紧凑历史总结提供信息。基于此框架,我们通过在伪标签轨迹上进行监督微调和使用群体相对策略优化(GRPO)进行强化学习,训练了一个GUI代理,名为GUI-Rise。该框架采用了专门的奖励,包括一个历史感知目标,直接将总结质量与后续动作表现联系起来。在标准基准上的全面评估表明,在相同的训练数据条件下,GUI-Rise取得了最先进的结果,尤其是在领域外场景中表现出色。这些发现验证了我们的框架在各种GUI导航任务中保持鲁棒推理和泛化的能力。
🔬 方法详解
问题定义:现有基于多模态大型语言模型(MLLMs)的GUI导航代理,在面对不同领域的GUI界面时,泛化能力不足。同时,如何有效地利用历史导航信息,辅助当前决策,也是一个挑战。现有方法难以在复杂GUI环境中进行有效的推理和决策,导致导航效率和成功率较低。
核心思路:GUI-Rise的核心思路是通过引入结构化推理和历史总结机制,增强代理的决策能力和泛化能力。结构化推理模拟人类的思考过程,对导航任务进行分解和分析,从而做出更合理的决策。历史总结则将之前的导航经验压缩成简洁的摘要,供后续步骤参考,避免重复探索和错误决策。
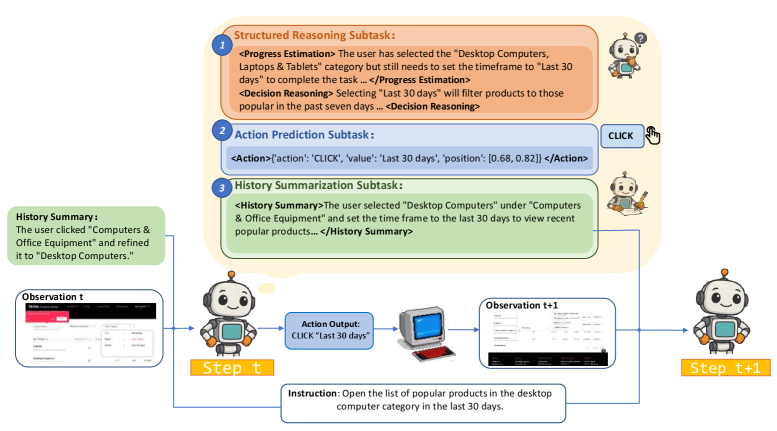
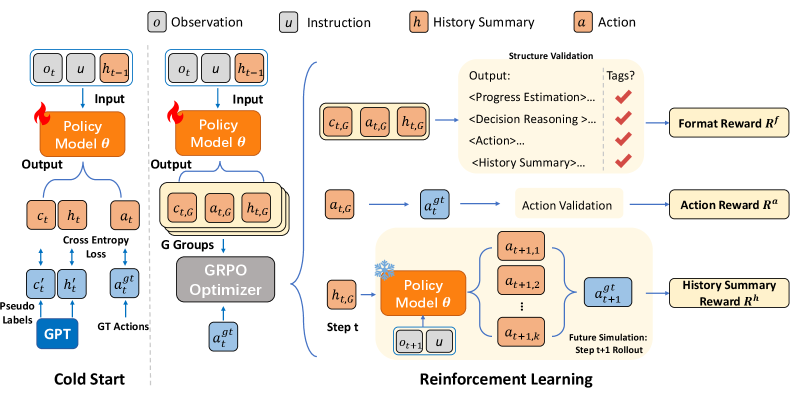
技术框架:GUI-Rise框架主要包含三个核心组件:结构化推理、动作预测和历史总结。首先,结构化推理模块生成Chain-of-Thought分析,包括进度估计和决策推理。然后,动作预测模块基于推理结果,预测下一步要执行的动作。最后,历史总结模块将之前的导航轨迹压缩成简洁的摘要,用于指导后续的推理和决策。整个框架通过监督微调和强化学习进行训练。
关键创新:GUI-Rise的关键创新在于将结构化推理和历史总结有机地结合在一起。结构化推理不仅用于指导动作预测,还用于生成历史总结,从而保证了历史信息的质量和相关性。同时,框架引入了历史感知奖励,直接将总结质量与后续动作表现联系起来,鼓励代理学习更有效的历史总结策略。
关键设计:GUI-Rise使用Chain-of-Thought进行结构化推理,将复杂的导航任务分解为一系列简单的步骤。历史总结模块采用Transformer模型,将历史导航轨迹压缩成固定长度的向量表示。在强化学习阶段,使用Group Relative Policy Optimization (GRPO)算法,提高训练的稳定性和效率。此外,还设计了专门的奖励函数,包括成功奖励、惩罚奖励和历史感知奖励,引导代理学习最优的导航策略。
🖼️ 关键图片

📊 实验亮点
GUI-Rise在标准GUI导航基准测试中取得了最先进的结果,尤其是在领域外场景中表现出色。在相同的训练数据条件下,GUI-Rise的性能显著优于现有方法,验证了其在跨领域泛化方面的优势。此外,实验还表明,历史总结模块能够有效地提升导航效率和成功率。
🎯 应用场景
GUI-Rise框架可应用于各种需要人机交互的场景,例如自动化测试、智能助手、无障碍辅助等。通过提升GUI导航代理的智能化水平,可以提高工作效率,降低人工成本,并为残障人士提供更好的用户体验。未来,该技术有望应用于更复杂的交互式系统中,实现更智能、更自然的交互方式。
📄 摘要(原文)
While Multimodal Large Language Models (MLLMs) have advanced GUI navigation agents, current approaches face limitations in cross-domain generalization and effective history utilization. We present a reasoning-enhanced framework that systematically integrates structured reasoning, action prediction, and history summarization. The structured reasoning component generates coherent Chain-of-Thought analyses combining progress estimation and decision reasoning, which inform both immediate action predictions and compact history summaries for future steps. Based on this framework, we train a GUI agent, \textbf{GUI-Rise}, through supervised fine-tuning on pseudo-labeled trajectories and reinforcement learning with Group Relative Policy Optimization (GRPO). This framework employs specialized rewards, including a history-aware objective, directly linking summary quality to subsequent action performance. Comprehensive evaluations on standard benchmarks demonstrate state-of-the-art results under identical training data conditions, with particularly strong performance in out-of-domain scenarios. These findings validate our framework's ability to maintain robust reasoning and generalization across diverse GUI navigation tasks. Code is available at https://leon022.github.io/GUI-Rise.