QuantumBench: A Benchmark for Quantum Problem Solving
作者: Shunya Minami, Tatsuya Ishigaki, Ikko Hamamura, Taku Mikuriya, Youmi Ma, Naoaki Okazaki, Hiroya Takamura, Yohichi Suzuki, Tadashi Kadowaki
分类: cs.AI, cs.CL, cs.LG, quant-ph
发布日期: 2025-10-30
备注: 11 pages, 8 figures
💡 一句话要点
提出QuantumBench以评估量子领域中的大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量子科学 大型语言模型 基准评估 数据集构建 模型性能分析
📋 核心要点
- 现有的通用基准无法有效评估大型语言模型在量子科学领域的表现,导致对模型能力的误判。
- 本文提出QuantumBench,通过编制量子科学相关的多项选择题,系统评估LLMs在该领域的理解能力。
- 实验结果表明,现有LLMs在量子领域的表现存在显著差异,且对问题格式的变化敏感性较高。
📝 摘要(中文)
随着大型语言模型(LLMs)在科学工作流程中的广泛应用,评估这些模型在特定领域知识捕捉能力的需求日益增加。尤其在量子科学领域,因其非直观现象和复杂数学要求,现有通用基准无法有效反映这些需求。本文提出了QuantumBench,一个专门针对量子领域的基准,系统评估LLMs在该领域的理解和应用能力。我们编制了约800道涵盖量子科学九个领域的问题及其答案,并将其组织为八选一的多项选择数据集。通过该基准,我们评估了多种现有LLMs的表现,并分析了它们对问题格式变化的敏感性。QuantumBench是首个为量子领域构建的LLM评估数据集,旨在指导LLMs在量子研究中的有效应用。
🔬 方法详解
问题定义:本文旨在解决现有通用基准无法有效评估LLMs在量子科学领域表现的问题。量子科学的复杂性和非直观性使得现有方法的评估结果可能不准确。
核心思路:QuantumBench通过编制量子科学相关的多项选择题,系统性地评估LLMs在理解和应用量子领域知识的能力,填补了这一领域的评估空白。
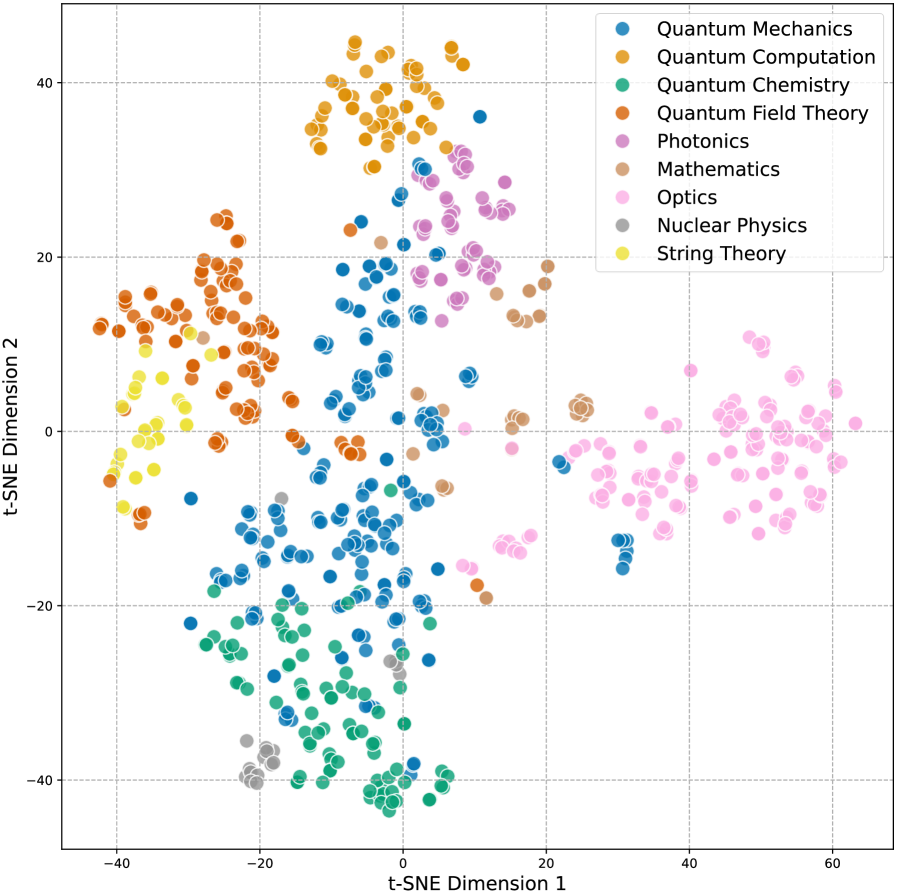
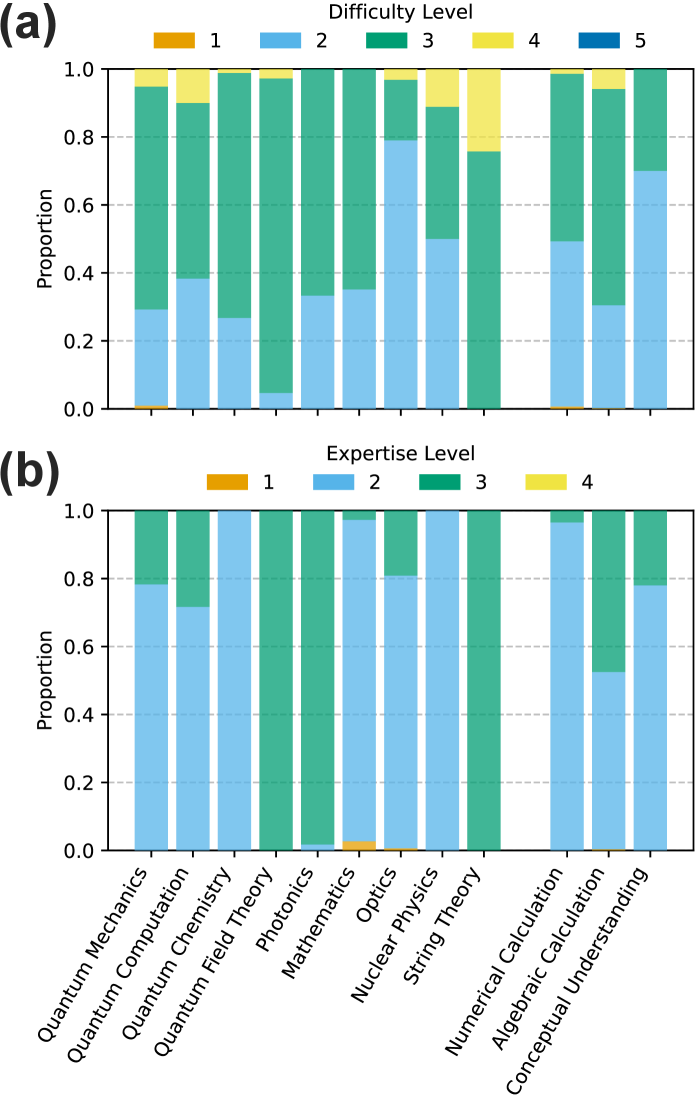
技术框架:整体架构包括数据集的构建、LLMs的评估和性能分析三个主要模块。数据集由约800道问题组成,涵盖九个量子科学领域,采用八选一的格式。
关键创新:QuantumBench是首个专门为量子领域设计的LLM评估数据集,其创新之处在于针对量子科学的特定需求进行设计,能够更准确地评估模型的能力。
关键设计:数据集中的问题设计考虑了量子科学的复杂性,采用多项选择形式以便于评估模型的选择能力,且问题涵盖了量子力学的多个重要领域。
🖼️ 关键图片
📊 实验亮点
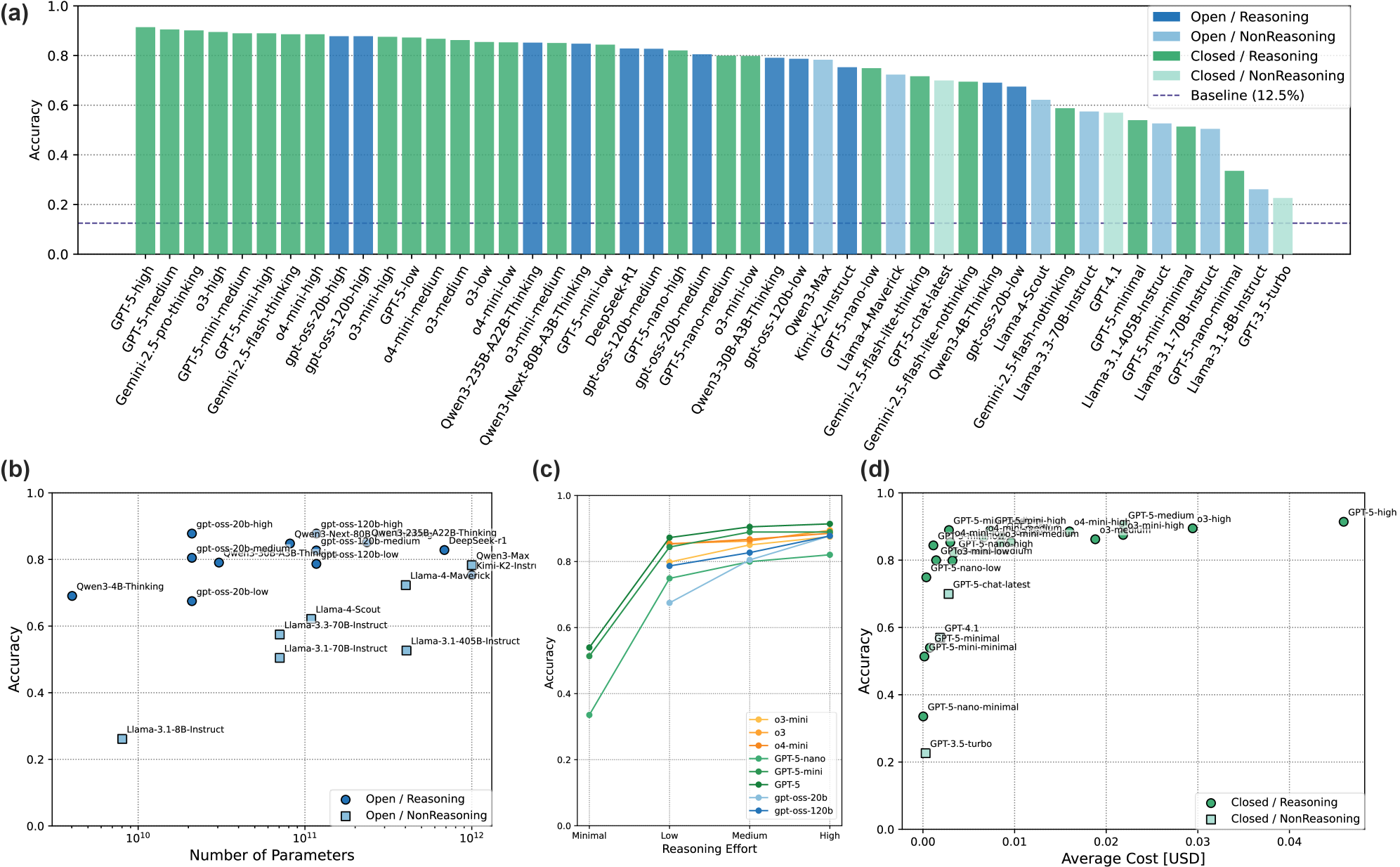
实验结果显示,评估的LLMs在量子领域的表现存在显著差异,某些模型在特定问题类型上表现优异,而其他模型则对问题格式变化表现出较高的敏感性。这些发现为未来量子研究中的模型选择提供了重要依据。
🎯 应用场景
QuantumBench的潜在应用领域包括量子计算、量子通信和量子材料科学等。通过有效评估LLMs在量子领域的表现,研究人员可以更好地利用这些模型进行数据分析、假设生成和设计空间探索,推动量子科学的发展。
📄 摘要(原文)
Large language models are now integrated into many scientific workflows, accelerating data analysis, hypothesis generation, and design space exploration. In parallel with this growth, there is a growing need to carefully evaluate whether models accurately capture domain-specific knowledge and notation, since general-purpose benchmarks rarely reflect these requirements. This gap is especially clear in quantum science, which features non-intuitive phenomena and requires advanced mathematics. In this study, we introduce QuantumBench, a benchmark for the quantum domain that systematically examine how well LLMs understand and can be applied to this non-intuitive field. Using publicly available materials, we compiled approximately 800 questions with their answers spanning nine areas related to quantum science and organized them into an eight-option multiple-choice dataset. With this benchmark, we evaluate several existing LLMs and analyze their performance in the quantum domain, including sensitivity to changes in question format. QuantumBench is the first LLM evaluation dataset built for the quantum domain, and it is intended to guide the effective use of LLMs in quantum research.