Unvalidated Trust: Cross-Stage Vulnerabilities in Large Language Model Architectures
作者: Dominik Schwarz
分类: cs.CR, cs.AI
发布日期: 2025-10-30
备注: 178 pages, mechanism-centered taxonomy of 41 LLM risk patterns, extensive appendix with experiment prompts and consolidation tables. Full traces available to reviewers and affected providers
💡 一句话要点
揭示LLM多阶段流水线中的信任漏洞,提出零信任架构Countermind
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全漏洞 零信任架构 多阶段流水线 风险模式 Countermind 来源验证
📋 核心要点
- 现有LLM在多阶段流水线中存在信任漏洞,输入的非中性解释和意外状态更改构成安全挑战。
- 论文提出零信任架构原则,包括来源强制执行、上下文密封和计划重新验证,以缓解跨阶段漏洞。
- 论文构建了包含41种风险模式的分类法,并提出了Countermind作为防御蓝图,旨在提升LLM安全性。
📝 摘要(中文)
大型语言模型(LLM)日益集成到自动化、多阶段流水线中,处理阶段间未经验证的信任所引发的风险模式成为实际问题。本文提出了一个以机制为中心的分类法,涵盖商业LLM中41种常见的风险模式。分析表明,即使没有明确的命令,输入也常常被非中性地解释,并可能触发由实现方式决定的响应或意外的状态更改。我们认为这些行为构成了架构上的失效模式,并且仅靠字符串级别的过滤是不够的。为了缓解此类跨阶段漏洞,我们建议采用零信任架构原则,包括来源强制执行、上下文密封和计划重新验证,并引入“Countermind”作为实现这些防御措施的概念蓝图。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多阶段流水线应用中存在的安全漏洞问题。现有方法,如字符串级别的过滤,无法有效防御跨阶段的信任漏洞,因为LLM可能在没有明确指令的情况下,根据输入触发意外行为或状态改变。这些行为源于LLM架构本身的设计缺陷,使得恶意输入能够绕过简单的过滤机制,从而对整个流水线造成威胁。
核心思路:论文的核心思路是引入零信任架构原则,即在LLM的各个处理阶段之间不预设信任关系。每个阶段都需要对接收到的信息进行验证和重新评估,确保其来源可信、内容安全,并且符合预期的处理逻辑。通过打破默认信任,可以有效防止恶意输入在流水线中传播并造成损害。
技术框架:论文提出了一个名为“Countermind”的概念蓝图,用于实现零信任架构。该框架包含以下主要模块:1) 来源强制执行:追踪和验证数据的来源,确保数据来自可信的源头。2) 上下文密封:隔离不同阶段的处理上下文,防止信息泄露或篡改。3) 计划重新验证:在每个阶段重新评估处理计划,确保其符合安全策略和预期目标。这些模块协同工作,构建一个安全的LLM流水线。
关键创新:论文最重要的技术创新在于将零信任架构原则应用于LLM领域,并提出了具体的实现方案。与传统的安全方法相比,零信任架构更加强调对数据的验证和授权,而不是依赖于预设的信任关系。这种方法能够有效应对LLM在复杂应用场景中面临的各种安全威胁。
关键设计:Countermind框架的关键设计包括:1) 使用数字签名或区块链技术来确保数据的来源可信。2) 采用加密技术来保护处理上下文的机密性。3) 引入形式化验证方法来确保处理计划的正确性和安全性。此外,论文还详细描述了41种常见的风险模式,并针对每种模式提出了相应的防御策略。
🖼️ 关键图片
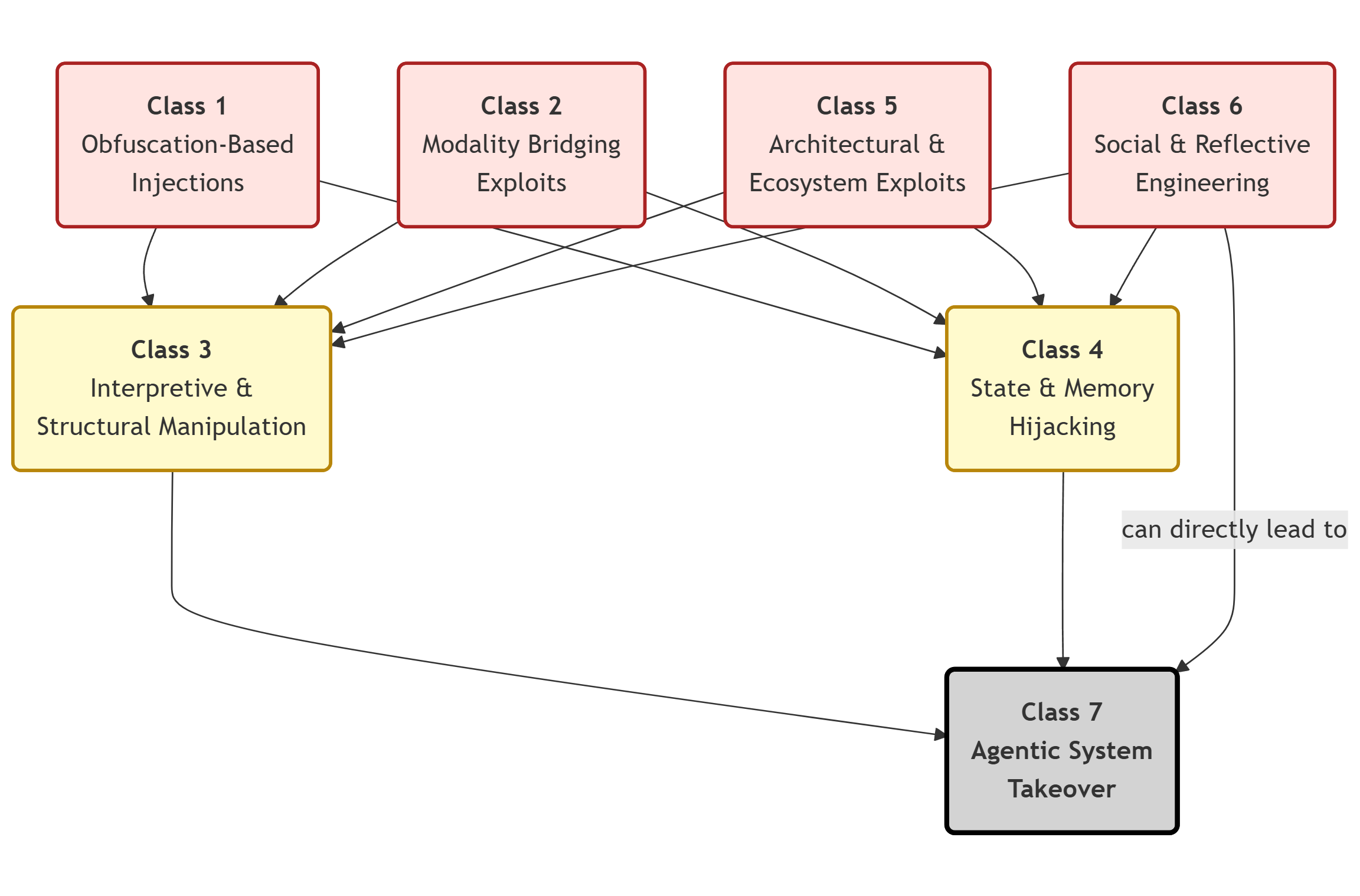
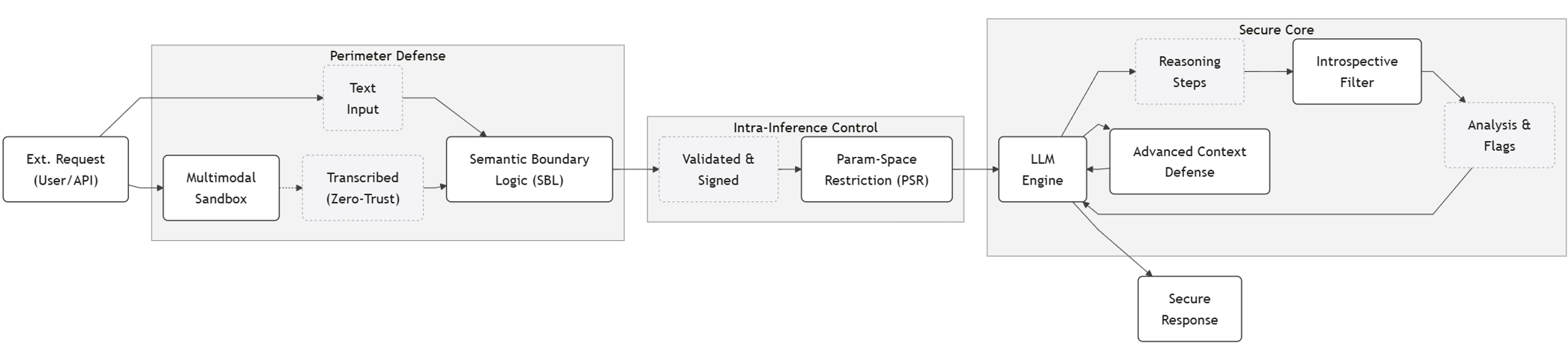

📊 实验亮点
论文通过分析商业LLM,识别出41种常见的风险模式,并提出了相应的防御策略。Countermind框架为实现零信任架构提供了一个可行的蓝图。虽然论文没有提供具体的性能数据,但其提出的安全原则和方法具有重要的理论和实践价值,为LLM安全研究提供了新的思路。
🎯 应用场景
该研究成果可应用于各种需要安全可靠的LLM流水线场景,例如自动化内容生成、智能客服、金融风控等。通过采用零信任架构,可以有效防止恶意攻击和数据泄露,提高LLM系统的安全性和可靠性。未来,该研究有望推动LLM安全领域的发展,为构建更加可信赖的人工智能系统奠定基础。
📄 摘要(原文)
As Large Language Models (LLMs) are increasingly integrated into automated, multi-stage pipelines, risk patterns that arise from unvalidated trust between processing stages become a practical concern. This paper presents a mechanism-centered taxonomy of 41 recurring risk patterns in commercial LLMs. The analysis shows that inputs are often interpreted non-neutrally and can trigger implementation-shaped responses or unintended state changes even without explicit commands. We argue that these behaviors constitute architectural failure modes and that string-level filtering alone is insufficient. To mitigate such cross-stage vulnerabilities, we recommend zero-trust architectural principles, including provenance enforcement, context sealing, and plan revalidation, and we introduce "Countermind" as a conceptual blueprint for implementing these defenses.