e1: Learning Adaptive Control of Reasoning Effort
作者: Michael Kleinman, Matthew Trager, Alessandro Achille, Wei Xia, Stefano Soatto
分类: cs.AI, cs.LG
发布日期: 2025-10-30 (更新: 2025-11-12)
💡 一句话要点
提出自适应努力控制方法,实现推理资源按需分配,提升成本-精度权衡。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自适应推理 强化学习 思维链 成本-精度权衡 资源分配
📋 核心要点
- 现有方法难以根据问题难度动态调整推理资源,需要手动指定token数量。
- 提出自适应努力控制,通过强化学习训练模型,根据用户指定的比例分配token。
- 实验表明,该方法能在保持或提升性能的同时,显著减少推理所需的token数量。
📝 摘要(中文)
增加AI模型的思考预算可以显著提高准确性,但并非所有问题都需要相同程度的推理。用户可能希望根据输出质量、延迟和成本的权衡,分配不同数量的推理资源。为了有效地利用这种权衡,用户需要对特定查询使用的思考量进行细粒度控制,但很少有方法能够实现这种控制。现有方法要求用户指定所需的绝对token数量,但这需要预先了解问题的难度,以便为查询设置适当的token预算。为了解决这些问题,我们提出了一种自适应努力控制(Adaptive Effort Control)方法,这是一种自适应强化学习方法,它训练模型使用相对于当前平均思维链长度的用户指定比例的token。这种方法消除了数据集和阶段特定的调整,同时产生了比标准方法更好的成本-精度权衡曲线。用户可以通过在推理时指定的连续努力参数动态调整成本-精度权衡。我们观察到,该模型自动学习按比例分配资源给任务难度,并且在从1.5B到32B参数的模型规模范围内,我们的方法能够将思维链长度减少2-3倍,同时保持或提高相对于用于强化学习训练的基础模型的性能。
🔬 方法详解
问题定义:现有的大语言模型在推理时,通常采用固定的token预算,无法根据问题的难易程度动态调整推理资源。用户需要手动设置token数量,这需要预先了解问题的难度,否则可能导致资源浪费或推理不足。因此,如何实现推理资源的自适应分配,以达到更好的成本-精度权衡,是一个重要的研究问题。
核心思路:论文的核心思路是利用强化学习训练模型,使其能够根据用户指定的努力程度(effort parameter)动态调整推理过程中的token使用量。模型学习如何根据问题的难度,自适应地分配推理资源,从而在保证性能的同时,降低计算成本。用户可以通过调整努力程度参数,灵活地控制成本和精度之间的权衡。
技术框架:整体框架是一个强化学习流程。首先,使用一个预训练的大语言模型作为基础模型。然后,定义一个奖励函数,该函数鼓励模型在达到目标精度的同时,尽可能减少token的使用量。接下来,使用强化学习算法(具体算法未知)训练模型,使其能够根据当前的状态(例如,已经生成的思维链)和用户指定的努力程度,选择下一步要执行的动作(例如,生成下一个token)。训练完成后,用户可以在推理时,通过调整努力程度参数,控制模型的推理过程。
关键创新:该方法的核心创新在于提出了自适应努力控制的概念,并将其转化为一个强化学习问题。通过强化学习,模型能够学习到一种策略,该策略可以根据问题的难度和用户的偏好,自适应地分配推理资源。这种方法不需要手动调整token数量,而是通过一个连续的努力程度参数来实现细粒度的控制。
关键设计:论文的关键设计包括:1) 使用用户指定的token比例作为控制信号,而不是绝对token数量;2) 设计一个奖励函数,该函数同时考虑了精度和token使用量;3) 使用强化学习算法训练模型,使其能够学习到一种最优的资源分配策略。具体的强化学习算法、奖励函数和网络结构等细节未知。
🖼️ 关键图片
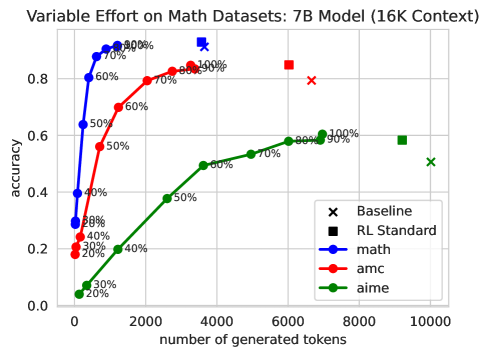
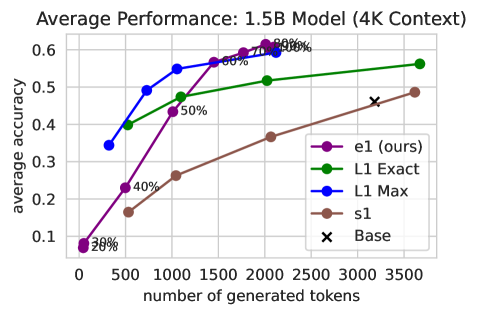

📊 实验亮点
实验结果表明,该方法能够在保持或提高性能的同时,将思维链长度减少2-3倍。与传统的固定token预算方法相比,该方法能够产生更好的成本-精度权衡曲线。在不同规模的模型(1.5B到32B参数)上都取得了显著的性能提升,表明该方法具有良好的可扩展性。
🎯 应用场景
该研究成果可应用于各种需要权衡计算成本和推理精度的场景,例如在线问答系统、智能客服、自动代码生成等。通过自适应地分配推理资源,可以显著降低计算成本,提高系统的响应速度,并提升用户体验。未来,该方法有望推广到更复杂的推理任务和更大的模型规模。
📄 摘要(原文)
Increasing the thinking budget of AI models can significantly improve accuracy, but not all questions warrant the same amount of reasoning. Users may prefer to allocate different amounts of reasoning effort depending on how they value output quality versus latency and cost. To leverage this tradeoff effectively, users need fine-grained control over the amount of thinking used for a particular query, but few approaches enable such control. Existing methods require users to specify the absolute number of desired tokens, but this requires knowing the difficulty of the problem beforehand to appropriately set the token budget for a query. To address these issues, we propose Adaptive Effort Control, a self-adaptive reinforcement learning method that trains models to use a user-specified fraction of tokens relative to the current average chain-of-thought length for each query. This approach eliminates dataset- and phase-specific tuning while producing better cost-accuracy tradeoff curves compared to standard methods. Users can dynamically adjust the cost-accuracy trade-off through a continuous effort parameter specified at inference time. We observe that the model automatically learns to allocate resources proportionally to the task difficulty and, across model scales ranging from 1.5B to 32B parameters, our approach enables a 2-3x reduction in chain-of-thought length while maintaining or improving performance relative to the base model used for RL training.